node.js爬取网站数据
- 提醒:示例网站代码已失效[ 应用逻辑有效 ]
- 第一步:准备工作;
- 1. 选择目标地址URL;
- 2. 确保 node.js 环境;
- 3. CMd命令 :创建项目文件夹 ;
- 4. CMd窗口 :调用 npm init 来初始化 生成 package.json ;
- 5. CMd窗口 : 安装所需依赖包 cheerio 、superagent 及nodejs 中的 fs 文件模块;
- (1)superagent 包 定义:
- (1)cheerio 包 定义:
- 第二步: 编写代码;
- 1. 引入依赖包;
- 2. 声明目标网址的url;
- 3. superagent 发送网络请求,下载Demo;
- 4 . 分析目标网站Dom结构,定位所需数据位置;
- 5 . 用 cheerio 的 load 方法进行包装请求后的响应体;
- 6 . 数据写入 json 文件;
- 第三步:执行一次test.js,爬取一次热门列表数据;
- 拓展 : 添加定时任务,定时爬取数据 【基于 node-schedule 包】;
- 1 . 安装node-schedule;
- 2 . node-schedule代码中的用法;
- 完整版:node.js 定时爬虫抓取数据;
提醒:示例网站代码已失效[ 应用逻辑有效 ]
示例网站已添加反爬处理,superagent部分仅获取到包含js跳转功能的部分html,非完整页面html;
针对未添加反爬处理的网站,本文逻辑依旧有效
第一步:准备工作;
1. 选择目标地址URL;
URL: https://s.weibo.com/top/summary?cate=realtimehot ;
2. 确保 node.js 环境;
node.js下载\安装
3. CMd命令 :创建项目文件夹 ;
mkdir antd-course
cd antd-course
4. CMd窗口 :调用 npm init 来初始化 生成 package.json ;
npm init -y // -y命令代表yes, 省略默认选项点击
5. CMd窗口 : 安装所需依赖包 cheerio 、superagent 及nodejs 中的 fs 文件模块;
npm i cheerio superagent -D
(1)superagent 包 定义:
一个轻量级、渐进式的请求库,内部依赖 nodejs 原生的请求 api,适用于 nodejs 环境;
(1)cheerio 包 定义:
nodejs 的抓取页面模块,为服务器特别定制的,快速、灵活、实施的 jQuery 核心实现;
适合各种 Web 爬虫程序。node.js 版的 jQuery ;
第二步: 编写代码;
1. 引入依赖包;
创建test.js文件
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
2. 声明目标网址的url;
const weiboURL = "https://s.weibo.com"; // 域名
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot"; // 路径
3. superagent 发送网络请求,下载Demo;
(1)参数:2 个;(请求的 url ,请求成功后的回调函数);
(2)回调函数参数:2个;(error 【成功,则返回 null,反之则抛出错误】, 成功后的 响应体);
# hotSearchURL :请求的Url;
# err : 回调函数第一参数[ 成功,则返回 null,反之则抛出错误 ];
# res : 请求的响应体;
superagent.get(hotSearchURL, (err, res) => {if (err) console.error(err);
});
4 . 分析目标网站Dom结构,定位所需数据位置;
如图:

5 . 用 cheerio 的 load 方法进行包装请求后的响应体;
【作用】:达成 nodejs 中,可以写 jQuery 语法的效果;
// 包装请求后的响应体 ;
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {// 拼接数组元素;if (index !== 0) {const $td = $(this).children().eq(1);const link = weiboURL + $td.find("a").attr("href");const text = $td.find("a").text();const hotValue = $td.find("span").text();const icon = $td.find("img").attr("src")? "https:" + $td.find("img").attr("src"): "";// 元素push进数组;hotList.push({index,link,text,hotValue,icon,});}
});
6 . 数据写入 json 文件;
fs.writeFileSync(file, data[, options]).
// node.js文件模块fs;
fs.writeFileSync('qq.json',JSON.stringify(hotList),"utf-8"
);
第三步:执行一次test.js,爬取一次热门列表数据;
node test.js
结果:
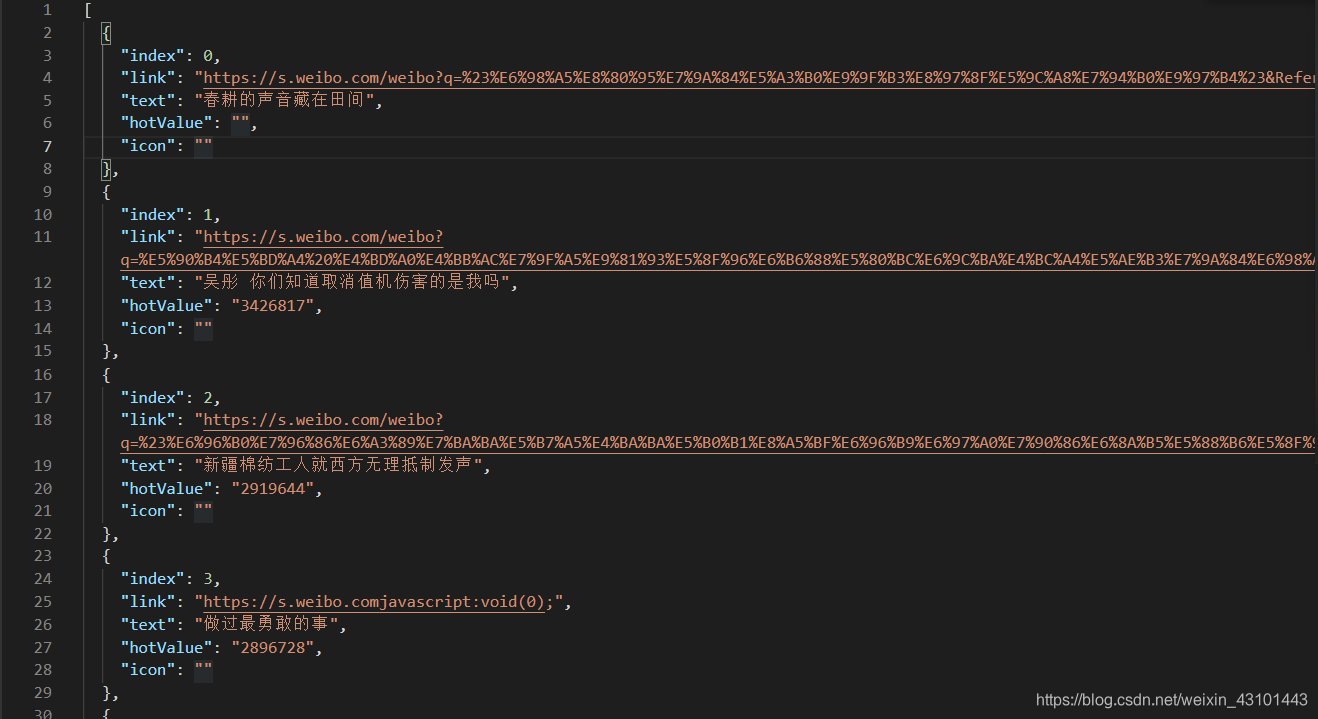
打开生成的qq.json文件可见, 爬取成功;
拓展 : 添加定时任务,定时爬取数据 【基于 node-schedule 包】;
schedule 的git地址.
1 . 安装node-schedule;
npm i node-schedule
2 . node-schedule代码中的用法;
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59, OPTIONAL)
// 分割线: 上方为对应使用规则 ;
const nodeSchedule = require("node-schedule");
const rule = "30 * * * * *"; // 30秒刷新一次,输出时间点;
nodeSchedule .scheduleJob(rule, () => {console.log(new Date());
});
完整版:node.js 定时爬虫抓取数据;
包含知识点:async、await 异步内容;.
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
const nodeSchedule = require("node-schedule");
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
// 封装单词抓取数据函数为async 函数,返回Promise对象,;
function getHotSearchList() {return new Promise((resolve, reject) => {superagent.get(hotSearchURL, (err, res) => {if (err) reject("request error");const $ = cheerio.load(res.text);let hotList = [];$("#pl_top_realtimehot table tbody tr").each(function (index) {if (index !== 0) {const $td = $(this).children().eq(1);const link = weiboURL + $td.find("a").attr("href");const text = $td.find("a").text();const hotValue = $td.find("span").text();const icon = $td.find("img").attr("src")? "https:" + $td.find("img").attr("src"): "";hotList.push({index,link,text,hotValue,icon,});}});hotList.length ? resolve(hotList) : reject("errer");});});
}// 利用node包“ nodeSchedule” 每隔30秒,执行async函数;
nodeSchedule.scheduleJob("30 * * * * *", async function () {
// 捕捉错误try {const hotList = await getHotSearchList(); // 阻塞代码,直到拿到resolve的值,此处即 hotList;await fs.writeFileSync(`app.json`,JSON.stringify(hotList),"utf-8");} catch (error) {console.error(error);}
});