http://www.apkbus.com/forum.php?mod=viewthread&tid=17712&extra=page%3D1
文章覆盖知识点:HttpWatch抓包,HttpClient模拟POST请求,Jsoup解析HTML代码,动态更新ListView
背景介绍:客户端(Client)或称为用户端,是指与服务器相对应,为客户提供本地服务的程序。而android系统上的90%客户端软件都有一个共性,就是为了改善网页在android系统上体验不佳而生,最具有影响力的软件有:新浪微博、人人网、淘宝等,这类软件最突出的特点就是,先有网站再有软件。由于网络技术发展的多样性,手机浏览器往往无法跟随它的步伐,为改善用户体验,网站客户端软件印运而生。
以下内容100%原创,并在安卓巴士论坛首发,如需转载,请注明作者和出处。谢谢合作。
开发Android网站客户端通常有两种方法:第一种,通过服务端的开放平台,调用提供的API接口来开发,比如说open sina;第二种,服务端没有提供任何接口,你也没有服务端任何数据库访问权限,就是一个纯纯粹粹的网站,要你做客户端。今天,我要和大家分享的正是第二种情况。

这是一个简单的示意图,告诉我们,数据是由网页从数据库中取出,我们要为这个系统做客户端,我们就应该这样去改造它。

通过这样间接的方法来访问数据库,只要网页能看到的内容,我们的客户端都能获取到,而UI是由你自行制作,就可以使使用体验上一个台阶。
既然网页是我们的数据枢纽,我们就从网页分析着手。
该教程来自本人项目-掌上民大-真实经验,所以用项目中的”掌上图书馆”板块来示范。
该项目任务为中南民族大学图书馆图书查询功能制作客户端。
首先打开该网址http://www.lib.scuec.edu.cn/,我们会看到主界面

正中间就是查询入口,我们输入”android”进行查询

得到结果的网页,但我们能发现,这个页面是ILAS图书管理系统,所以真正的入口并不是上面红圈的地方。
所以我继续找,经过短暂的观察,发现入口在这里
所以我继续找,经过短暂的观察,发现入口在这里

我们点击进入

果然就是这货,我们点击书目查询

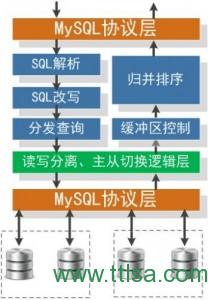
就是它了。真正的入口就在这里,这时我们打开HttpWatch软件,点”Record”,在搜索框里输入”android”,点击查询,抓取以”android”为关键字搜索时浏览器的所有包。待结果界面载入完成后,HttpWatch上就会出现如下信息

我们先看Summary选项卡,我们可以初步了解,这是一个POST请求(Http请求中的一种,另一种是GET),POST到的网址是 http://coin.lib.scuec.edu.cn/cgi-bin/IlaswebBib 。
这样我们的思路就清晰了,我们的客户端需要模拟浏览器,向上述地址POST一个包,那个地址肯定会返回一个Content给我们,不出意外的话,Content里面就是我们要的书目信息。那么,浏览器POST上去的内容是什么呢?我们点击这条POST请求,看详细信息,

由于是POST请求,我们先看POST DATA,里面是以键值对的形式存储的,这里显示了我们浏览器在我们搜索”android”时,POST的所有数据。那这些键值对又代表了什么呢,我们打开这个网页的源码来一探究竟。

从这段可以看出v_index是表示查找途径的它有TITLE,AUTHOR,SUBJECT,CLASSNO,ISBN,CALLNO六种值

FLD_DAT_BEG和FLD_DAT_END分别是开始和结束年份

v_value表示用户在搜索框中输入的内容

v_paggnum表示每页显示的书目条数,有10 15 20三种

v_seldatabases是检索库 有0 1 2三种值v_LogicSrch是检索方式 有0 1两种值

Submit是查询或重填,有 查 询 和 重 填 两种值
至此,我们弄清楚了POST Data里所有内容的含义和取值可能。但我们模拟POST请求为什么,其实就是为了得到搜索的书目信息,所以我们看一下返回的Content是不是我们要的东西

果然,就是我们搜到的书目信息,就以String的形式放在Content里面。最后我们查看一下Stream,截图,以防等下我们需要这里面的东西

好了,这个页面的工作原理我们已经弄清楚了:用户在网页中输入搜索内容后,点击查询,浏览器会POST一个Data到目标网址,该网址的返回信息就是搜到的书目。
我们开始编写代码,模拟这个过程,先打开eclipse建立一个Java项目(注意是Java项目,因为Java项目可以完美移植到Android项目中且调试方便,并且模拟Http请求这一过程没有用到任何Android功能)。
导入HttpClient的4个包commons-codec、commons-httpclient、commons-logging、log4j。
现在,我们得到了POST方法返回的String,我们输出到控制台看看是什么

没错,就是我们上文看到的HttpWatch 抓到的返回Content,也就是一段HTML代码,这说明,我们模拟浏览器POST请求成功了!
我们再试试别的搜索内容,来一个” Android开发 ”(即将v_value键值对的值改成”android开发”),这时运行后,我们却从控制台得到了这样的结果:

经过几次试验后,发现一个规律,只要搜索内容中包括中文,就搜不到。
所以可以判定是中文编码的问题,(在开发这类客户端时候,中文编码往往是个很具困难的问题。安卓巴士开发3群的某群友提到:服务器交流用的编码是”ISO-8859-1”,跟我起初用到的编码一致,但真实性仍需考证)所以我们修改上面的代码,将代表搜索内容的v_value对应的值编码为”ISO-8859-1”
就将上段代码中的
改为
这时再运行,控制台成功输出以” android开发”为关键字的Content。
至此,我们POST请求才真正完成。 观察控制台的HTML后发现,我们需要的书目信息就在里面,只不过被一些HTML标签包裹住了,下一步我们就要解放这些信息,存储到容器里。
这里我们要用到Jsoup,一个Java开源HTML解析器(来自org.jsoup包)。
我们直接上代码,逐行解释(大家最好对应上面的HTML代码来理解)
首先我们建一个容器来装这些解析到的数据,由于我的项目是将这些数据以ListView呈现给用户,而ListView的数据是由Adapter提供,Adapter需要传一个特殊容器-包含HashMap的ArrayList(Android基础知识)
list就是我们需要的ArrayList啦
上面所有代码调通后,我们只需一些简单的复制粘贴,就可以放在我们的Android工程中,加上一段简单的代码就可以让ListView显示这个ArrayList。(由于没有任何技术含量,以及该项目暂未上线,此段代码不予以展示,敬请谅解)
接下来,我们一个页面最多只包含10个书目信息,而我们校图书馆,光以”Java”为关键字的书就超过1000本,怎么来显示完全呢,一次显示所有的书肯定不现实。首先数据量太大,手机无法承受;消耗流量过大,用户体验极差。所以,我们就需要ListView能够动态加载数据,即一开始显示十项,如果用户此时拉动ListView显示完十项之后,自动联网,再加载十项(如果还有十项的话),这样的用户体验会非常顺畅。
这个功能的核心是,我们的ListView需要实现OnScrollListener接口。
如果你的ListView所在的Activity继承的是ListActivity的话,只需在extends ListActivity后面加上implements OnScrollListener,这时你需要复写onScroll和onScrollStateChanged。如果你的ListView是从XMLgetView 得到的,你只需为它setOnScrollListener,也会需要你复写onScroll和onScrollStateChanged。
不管你用哪种方法,我们只用修改onScroll方法
至此,文章开头的几个知识点已经全部讲解完毕,时间仓促,事物繁忙,可能会影响文章质量,还请大家多多包涵。 如果有问题,可以直接回帖、发论坛信息或通过Email:anliupeinye@gmail.com联系我。
项目成品展示:

看看这些信息是不是就是上面用网页以"android"为关键字搜索到的?
最后感谢安卓巴士论坛、安卓王子、安卓巴士开发3群的群友的支持。