---恢复内容开始---
基于scrapy_redis和mongodb的分布式爬虫
项目需求:
1:自动抓取每一个农产品的详细数据
2:对抓取的数据进行存储
第一步:
创建scrapy项目


创建爬虫文件

在items.py里面定义我们要爬取的数据
# -*- coding: utf-8 -*-# Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass NongcpspiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 供求关系supply = scrapy.Field()# 标题title = scrapy.Field()# 发布时间create_time = scrapy.Field()# 发布单位unit = scrapy.Field()# 联系人contact = scrapy.Field()# 手机号码phone_number = scrapy.Field()# 地址address = scrapy.Field()# 详细地址detail_address = scrapy.Field()# 上市时间market_time = scrapy.Field()# 价格price = scrapy.Field()
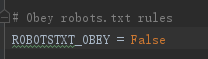
将settings.py改为false
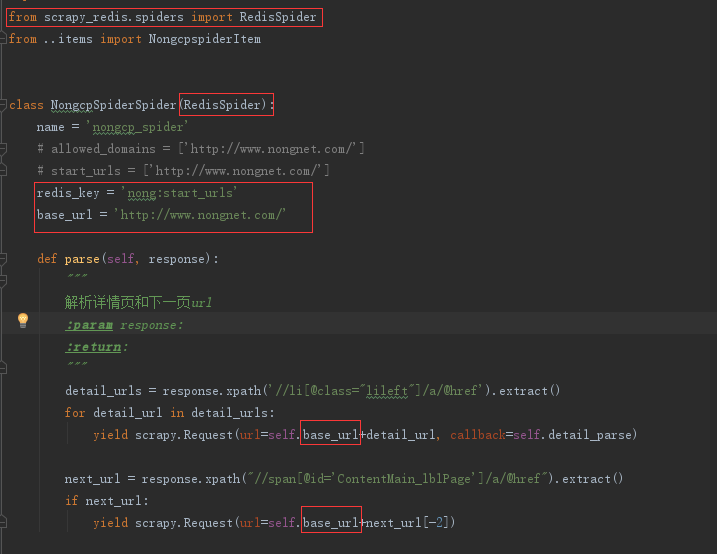
写spider爬虫文件nongcp_spider.py,进行字段解析使用xpath,正则表达式
# -*- coding: utf-8 -*- import scrapy import re from ..items import NongcpspiderItemclass NongcpSpiderSpider(scrapy.Spider):name = 'nongcp_spider'# allowed_domains = ['http://www.nongnet.com/']start_urls = ['http://www.nongnet.com/']def parse(self, response):"""解析详情页和下一页url:param response::return:"""detail_urls = response.xpath('//li[@class="lileft"]/a/@href').extract()for detail_url in detail_urls:yield scrapy.Request(url=self.start_urls[0]+detail_url, callback=self.detail_parse)next_url = response.xpath("//span[@id='ContentMain_lblPage']/a/@href").extract()if next_url:yield scrapy.Request(url=self.start_urls[0]+next_url[-2])def detail_parse(self, response):"""解析具体的数据:param response::return:"""items = NongcpspiderItem()title_result = response.xpath('//h1[@class="h1class"]/text()').extract_first()if title_result:items['supply'] = title_result.strip()[1:2]items['title'] = title_result.strip()[3:]creatte_time = re.findall(r"<font color='999999'>时间:(\d+/\d+/\d+ \d+:\d+)  ", response.text)if creatte_time:items['create_time'] = creatte_time[0]unit = re.findall(r"发布单位</div><div class='xinxisxr'><a href='.*?.aspx'>(.*?)</a>", response.text, re.S)if unit:items['unit'] = unit[0]price = response.xpath('//div[@class="scdbj1"]/text()').extract()if price:items['price'] = ''.join(price)yield items
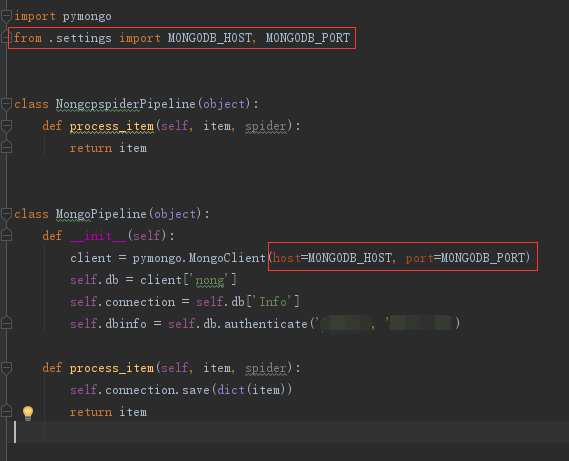
编写pipelines.py,往mongodb里面存储数据
# -*- coding: utf-8 -*-# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongoclass NongcpspiderPipeline(object):def process_item(self, item, spider):return itemclass MongoPipeline(object):def __init__(self):client = pymongo.MongoClient(host='127.0.0.1', port=27017)self.db = client['nong']self.connection = self.db['Info']self.dbinfo = self.db.authenticate('xxxx', 'xxxx')def process_item(self, item, spider):self.connection.save(dict(item))return item
完成以上步骤就可以进行数据的爬取了,接下来我们来测试一下爬取的效果
编写启动脚本start.py
#encoding: utf-8from scrapy import cmdline# cmdline.execute("scrapy crawl qsbk_spider".split()) cmdline.execute(["scrapy", 'crawl', 'nongcp_spider'])
开启settings.py pipelines字段

运行程序,爬取到的效果如下

接下来实现分布式去重爬取
先安装scrapy-redis

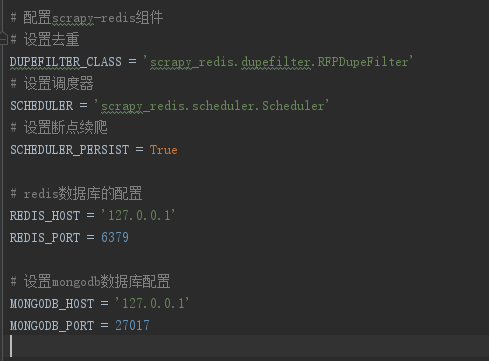
在settings.py里面配置scrapy-redis组件
在pipelines.py引入mongdb配置
修改nongcp_spider.py文件
如果爬取过程中出现封ip的操作,我们可以设置middlewares.py,,在该文件设置代理
使用阿布云代理

先启动start.py文件,在运行redis-cli

然后就可以抓取数据了到mongdb里面了
---恢复内容结束---