创建k-近邻算法分类器
def classify0(inX,dataSet,labels,k):## inX:用于分类的输入向量## dataSet:输入的训练样本集## labels:训练样本标签## k:选择的近邻数目dataSetSize=dataSet.shape[0] ##样本集的数目diffMat=tile(inX,(dataSetSize,1))-dataSet ##输入向量与训练样本相减sqDiffMat=diffMat**2 ##两个样本点之间的距离的平方sqDistance=sqDiffMat.sum(axis=1) ##所有样本点之间距离的平方相加distance=sqDistance**0.5 ##所有样本点之间距离的平方和开根号sorted_d=distance.argsort() ##对其进行排序classCount={}for i in range(k):votel=labels[sorted_d[i]] ##距离从小到大的样本点对应类别classCount[votel]=classCount.get(votel,0)+1 ##该类别的数目加1sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) ##排序return sortedClassCount[0][0] ##选取第一个即为分类结果
读取约会数据
数据存放在一个名为datingTestSet2.txt的文件中,每个样本数据占据一行,共1000行,每行包含三个特征。
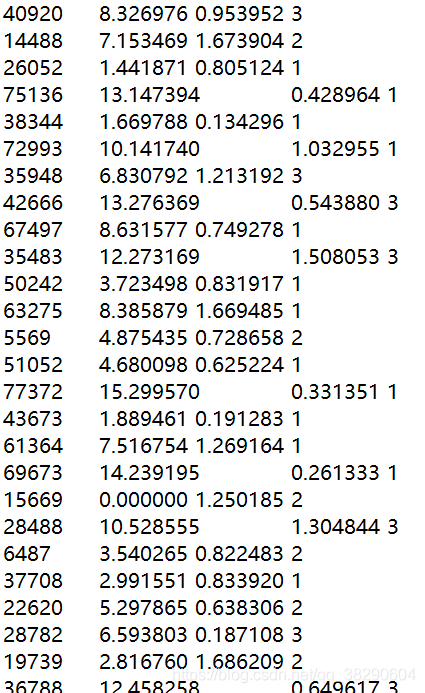
def file2matrix(filename):fr=open(filename)arrayOLines=fr.readlines()numberarray=len(arrayOLines)returnMat=zeros((numberarray,3))classLabel=[]index=0for line in arrayOLines:line=line.strip() ##去掉两头的空格listline=line.split('\t') ##以\t划分returnMat[index,:]=listline[0:3] ##将新数据加入到returnMatclassLabel.append(int(listline[-1])) ##将新数据的类别加入到classLabelindex+=1return returnMat,classLabel
对所有数据归一化处理
在处理不同取值范围的特征数据时,通常采用归一化数值的方法,将取值范围处理为0到1或者-1到1之间。使用下边的公式既可实现;
newValue=(oldValue−min)/(max−min)newValue=(oldValue-min)/(max-min)newValue=(oldValue−min)/(max−min)
def autoNorm(returnMat):min=returnMat.min(0)max=returnMat.max(0)range=max-minnormDataSet=zeros(shape(returnMat))m=returnMat.shape[0]normDataSet=returnMat-tile(min,(m,1))normDataSet=normDataSet/tile(range,(m,1))return normDataSet
测试分类器的准确率
def datingClassTest():hoRatio=0.1 ##选取10%的数据作为测试集datingDataMat,datingLabels=file2matrix('datingTestSet2.txt') ##从文件中读取数据normMat=autoNorm(datingDataMat) ##对数据进行归一化处理m=normMat.shape[0] numTestVecs=int(m*hoRatio) ##测试集的数目errorCount=0.0for i in range(numTestVecs):classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)print('The classifier came back with:%d,the real result is %d.'%(classifierResult,datingLabels[i]))if classifierResult!=datingLabels[i]:errorCount+=1print('The total error rate is:%f.'%(errorCount/float(numTestVecs)))
约会结果运行结果

手写数字识别系统读取文件数据
##将32x32的数据转变为1x1024
def img2vector(filename):returnVect=zeros((1,1024))fr=open(filename)for i in range(32):linestr=fr.readline()for j in range(32):returnVect[0,32*i+j]=int(linestr[j])return returnVect
手写数字识别
##数据分为两个文件夹,一个是测试数据集,一个是验证数据集。
##首先将测试数据集中的数据以1x1024格式导出,放入trainingMat列表中;然后将验证集中的数据以同样的方式导出,放入分类器中进行分类,所用分类器是前边的k-近邻分类法。将分类器产生的类别与实际类别对比,得到准确率。文本名称是数字的类别,所以对于数据集的类别,可以对文本名称进行提取。
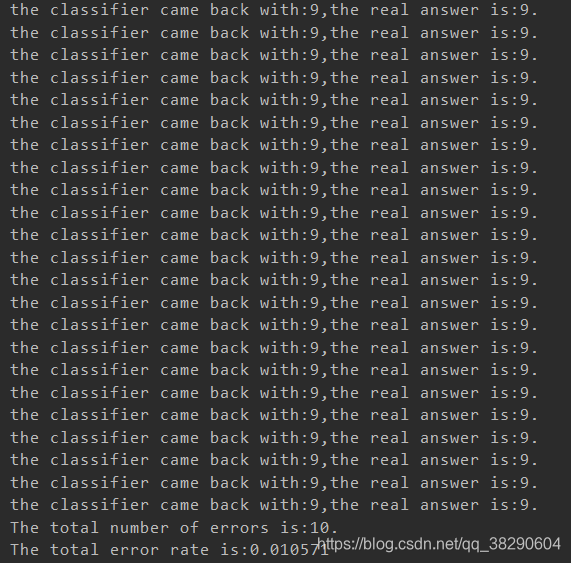
def handwritingClassTest():hwLabels=[]trainingFileList=listdir('trainingDigits')m=len(trainingFileList)trainingMat=zeros((m,1024))##训练集数据以及类别导出for i in range(m):fileNamestr=trainingFileList[i]filestr=fileNamestr.split('.')[0]classNumStr=int(filestr.split('_')[0])hwLabels.append(classNumStr)trainingMat[i,:]=img2vector('trainingDigits/%s' % fileNamestr)testFileList=listdir('testDigits')errorCount=0.0mTest=len(testFileList)##验证集数据的训练for i in range(mTest):fileNameStr=testFileList[i]fileStr=fileNameStr.split('.')[0]classNumStr=int(fileStr.split('_')[0])vectorUnderTest=img2vector('testDigits/%s' % fileNameStr)classifierResult=classify0(vectorUnderTest,trainingMat,hwLabels,3)print('the classifier came back with:%d,the real answer is:%d.' % (classifierResult,classNumStr))if classifierResult!=classNumStr:errorCount+=1.0print('The total number of errors is:%d.' % errorCount)print('The total error rate is:%f' % (errorCount/float(mTest)))
运行结果