一、一些用到的技术
1.1解析验证码(联众-收费,两分钱一个)
验证码识别设计机器学习,没有耗费时间去实现,所以采用了第三方(联众)的在线打码,注册充值便可使用,识别率挺高的,验证码识别种类不少,充了五十块玩了好久还剩不少。具体地址http://v1-http-api.jsdama.com/api.php?mod=php
1.2 具体实现代码,此部分负责登录的部分逻辑(__init__.py)

# -*- coding: utf-8 -*- import sys sys.path.append("..") import requests, json from common.base import Base from requests.packages.urllib3.exceptions import InsecureRequestWarning # 禁用安全请求警告 requests.packages.urllib3.disable_warnings(InsecureRequestWarning) __author__ = 'Rachel feng' PATH = 'https://kyfw.12306.cn' __all__ = ['LoginTic']class LoginTic(Base):def __init__(self):super(LoginTic, self).__init__()# 验证结果 def checkYanZheng(self,solution): # # 分割用户输入的验证码位置 # 225,83|181,31|35,67 => 225,83,181,31,35,67yanStr = solution.replace('|',',')print('校验验证码......')checkUrl = "https://kyfw.12306.cn/passport/captcha/captcha-check" data = { 'login_site':'E', #固定的 'rand':'sjrand', #固定的 'answer':yanStr #验证码对应的坐标,两个为一组,跟选择顺序有关,有几个正确的,输入几个 } print(data)# 发送验证 cont = self.requests.post(checkUrl, data=data, verify=False) # 返回json格式的字符串,用json模块解析 dic = cont.json() code = dic['result_code'] # 取出验证结果,4:成功 5:验证失败 7:过期 if str(code) == '4': return True else:print(dic)return False # 发送登录请求的方法 def loginTo(self, userName, pwd):yan = self.decode_captcha(url) check = False # #只有验证成功后才能执行登录操作 # while not check: check = self.checkYanZheng(yan)if not check:return 600, '验证失败,请重新验证'loginUrl = "https://kyfw.12306.cn/passport/web/login" data = { 'username':userName, 'password':pwd, 'appid':'otn' }print(data)headers = {'Origin': 'https://kyfw.12306.cn','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36','Referer': 'https://kyfw.12306.cn/otn/login/init','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'application/json, text/javascript, */*; q=0.01'}result = self.requests.post(loginUrl,data=data,headers=headers) dic = result.json() print(dic)mes = dic['result_message'] # 结果的编码方式是Unicode编码,所以对比的时候字符串前面加u,或者mes.encode('utf-8') == '登录成功'进行判断,否则报错 if mes == u'登录成功':# 获取cookier = self.requests.post('https://kyfw.12306.cn/otn/login/userLogin')data = {'appid': 'otn'}r = self.requests.post('https://kyfw.12306.cn/passport/web/auth/uamtk', data=data)if r.status_code != 200:return 600, '登录验证不通过'd = r.json()if d.get('result_code') == 0:data = {'tk': d.get('newapptk')}r = self.requests.post('https://kyfw.12306.cn/otn/uamauthclient', data=data)d = r.json()print(d)if d.get('result_code') == 0:print('恭喜你,登录成功,可以购票!')return Trueelse:return 600, d.get('result')else: print(dic.get('result_message'))return 600, dic.get('result_message')def get_info(self):data = {'_json_att': ''}headers = {'Referer': 'https://kyfw.12306.cn/otn/index/initMy12306','Origin': 'https://kyfw.12306.cn','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded'}r = self.requests.post('https://kyfw.12306.cn/otn/modifyUser/initQueryUserInfo', data=data, headers=headers)if r.status_code != 200:print('获取购票人信息异常')with open('__tmp/userInfo.html', 'wb') as f:f.write(r.content)f.close() print('获取信息成功')if __name__ == '__main__': userName = '’ # 12306登录账号pwd = '' #12306登录密码url = "https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand"; login = LoginTic() d = login.loginTo(userName, pwd)if type(d) != tuple:login.get_info()else:print(d)
1.2base.py(在comment目录底下共用)
# -*- coding: utf-8 -*- import importlib, logging, codecs, json, datetime, time import web, requests from pyquery import PyQuery as pq from jinja2 import Template__all__ = ["cache_session"]# API_PATH = 'http://bbb4.hyslt.com/api.php?mod=php' API_PATH = 'http://v1-http-api.jsdama.com/api.php?mod=php' USERNAME = '' #联众账号 PASSWORD = '' #联众密码 TOKEN = ''class Base(object):"""docstring for base"""def __init__(self):self.session = requests.session() net = requests.Session()net.timeout = 30net.headers.update({ "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36" })retries = requests.packages.urllib3.util.retry.Retry(total=3, backoff_factor=0.1,status_forcelist=[500, 502, 503, 504])adapter = requests.adapters.HTTPAdapter(max_retries=retries)net.mount('http://', adapter)net.mount('https://', adapter)self.requests = net# 识别def decode(self, img, codetype=1303, minlength=1, maxlength=8):"""img: 验证码图片codetype: 验证码类型(https://www.jsdati.com/price)1001: 四个字母,数字1201: 计算题1008: 纯字母验证码1009: 纯数字验证码1013: 5位字母加数字(5位纯字母)1014: 6位字母加数字(6位纯字母)1015: 7位字母加数字(7位纯字母)1313: 坐标点击3次1314: 坐标点击4次minlength: 验证码最小长度maxlength: 验证码最大长度"""data = {'user_name': USERNAME,'user_pw': PASSWORD,'zztool_token': TOKEN,'yzmtype_mark': codetype,'yzm_minlen': minlength,'yzm_maxlen': maxlength}files = {'upload': img}try:r = self.requests.post(API_PATH, params={'act':'upload'}, data=data, files=files, timeout=20)except:return 504, '连接超时'd = r.json()return d# 获取验证码图片 def decode_captcha(self, url): print('get code....') response = self.requests.get(url, verify=False) # 把验证码图片保存到本地 with open('vcode.png','wb') as f: f.write(response.content) # 用pillow模块打开并解析验证码,这里是假的,自动解析以后学会了再实现 try: content = response.contentexcept:content = Noneprint('获取验证码失败')# 识别print('decode...')d = self.decode(content)# 识别成功if type(d) is dict and d['result']:code = d['data']['val']print(code)# 保存验证码图片return codeelif type(d) is str:return d
1.3一些乱七八糟补充的:
项目目录
comment
---__init__.py
---base.py
test
---__init__.py
验证码识别有时候识别不准确,导致校验有时候会不通过,得检查一下请求头什么的。
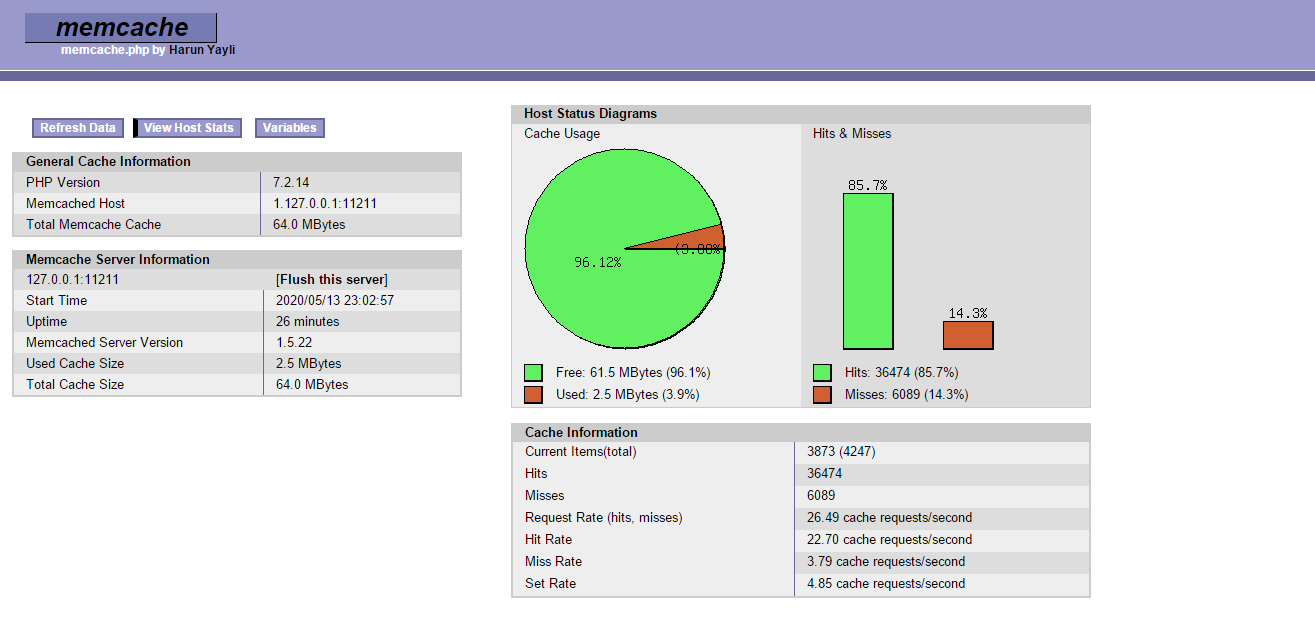
2.运行结果