在本案例中将对传统Spider类和CrawlSpider在实际项目中的应用进行对比,所完成的功能为一样的结果,采用三种不同的方式进行代码编写,请读者自行学习。
- 传统Spider实现数据爬取
- CrawlSpider实现数据读取(网站解析有问题暂时不能够实现)和页面跳转
- CrawlSpider实现单一页面跳转并采用传统scrapy方式进行数据爬取功能
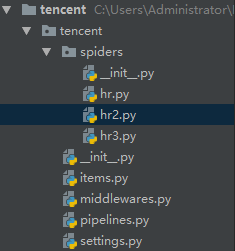
1.项目框架展示
2.爬取数据网站展示

3.三种不同爬虫代码展示
# -*- coding: utf-8 -*-
import scrapyclass HrSpider(scrapy.Spider):name = 'hr'allowed_domains = ['tencent.com']start_urls = ['http://hr.tencent.com/position.php']def parse(self, response):tr_list = response.xpath("//table[@class = 'tablelist']/tr")[1:-1] #去除第一个和最后一个--切片for tr in tr_list:item = {}item["title"] = tr.xpath("./td[1]/a/text()").extract_first()item["position"] = tr.xpath("./td[2]/text()").extract_first()item["publish_date"] = tr.xpath("./td[5]/text()").extract_first()yield item#找到下一页的url地址next_url = response.xpath("//a[@id='next']/@href").extract_first()if next_url != "javascript:;": #判断是否为最后一页next_url = "http://hr.tencent.com/" + next_urlyield scrapy.Request(next_url,callback = self.parse, #处理方式一样,所以交给自己处理)# def parse1(self, response):# response.meta["item"] #实现item在不同解析函数之间的数据传输
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule#网站有问题,仅作为学习参考即可
class Hr2Spider(CrawlSpider):name = 'hr2'allowed_domains = ['tencent.com']start_urls = ['https://hr.tencent.com/position.php/']rules = (Rule(LinkExtractor(allow=r'position_detail\.php\?id=\d+&keywords=&tid=0&lid=0'), callback='parse_item'),Rule(LinkExtractor(allow=r'position\.php\?&start=\d+#a'), follow=True),#翻页功能)def parse_item(self, response):print(response.url)item = {}item["title"] = response.xpath("//td[@id='sharetitle']").extract_first()#item["qcquire"] = response.xpath("//div[text()=='工作要求:']/../ul/li/text()").extract()#多条文本print(item)- 此处网站解析有问题暂时无法实现详细简介爬取,在方法三中使用传统scrapy方法可以得到,请读者自行查看学习。如实在不理解哪里的错误可以留言给我。
-
3.CrawlSpider实现单一页面跳转并采用传统scrapy方式进行数据爬取功能
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass Hr3Spider(CrawlSpider):name = 'hr3'allowed_domains = ['tencent.com']start_urls = ['https://hr.tencent.com/position.php/']rules = (# 提取翻页列表页的URL地址Rule(LinkExtractor(allow=r'position\.php\?&start=\d+#a'), callback='parse_item', follow=True),)def parse_item(self, response):tr_list = response.xpath("//table[@class='tablelist']/tr")[1:-1] #取出所有tr信息标签(去除了第一个无用tr标签)for tr in tr_list:item = {}item["title"] = tr.xpath("./td[1]/a/text()").extract_first()item["href"] = "https://hr.tencent.com/"+tr.xpath("./td[1]/a/@href").extract_first()yield scrapy.Request(item["href"],callback=self.parse_detail,meta = {"item":item})def parse_detail(self,response):item = response.meta["item"]item["aquire"] = response.xpath("//div[text()='工作要求:']/../ul/li/text()").extract()print(item)
4.pipeline.py展示
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlclass TencentPipeline(object):def process_item(self, item, spider):print(item)return item
5.settings.py展示
# -*- coding: utf-8 -*-# Scrapy settings for tencent project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'tencent'SPIDER_MODULES = ['tencent.spiders']
NEWSPIDER_MODULE = 'tencent.spiders'LOG_LEVEL = "WARNING"# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'# Obey robots.txt rules
ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'tencent.middlewares.TencentSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'tencent.middlewares.TencentDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'tencent.pipelines.TencentPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
6.效果展示