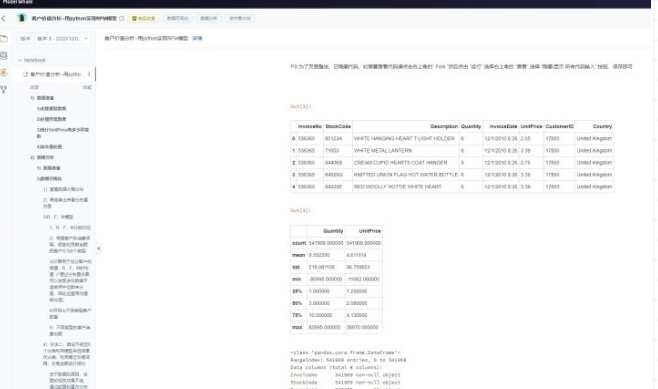
每日更新网站的名言与图片
- 前言
- 具体流程
- 用爬虫收集想要的信息
- 将内容写入数据库
- 设置定时脚本
- 后端读取数据库
前言
我做自己网站时,觉得内容有点空洞,想到有道翻译首页每天都会更新图片和名言,还挺有意思的,不如我去抄一抄吧。
最后没抄有道翻译,而是去抄了ONE,因为我之前用爬虫爬过ONE的名言,为了省事,我就是这么懒。
先放上效果图

这个框里的图片、日期、格言会每日自动更新

这个是我参考的版式,要特别感谢帮我排版的妹子,拯救了我糟糕的审美,哈哈。
具体流程
用爬虫收集想要的信息
这里用的方法还是python的BeautifulSoup。在我之前的文章里详细说过用法,我也上传过代码到git上
用爬虫爬取 boss直聘 招聘信息文章链接
除了爬取名言外,还需要下载图片,用到了urllib.request.urlretrieve方法
urllib.request.urlretrieve(img_url,img_name)
也可以这么写,这样能看到下载进度
urllib.request.urlretrieve(img_url,img_name,download_schedule)def download_schedule(a,b,c):"""a:已经下载的数据块b:数据块的大小c:远程文件的大小"""per = 100.0*float(a*b)/float(c)if per > 100:per = 100print("a", a)print("b", b)print("c", c)print('{:.2f}%'.format(per))
将内容写入数据库
我用了Mysql数据库,设置了四个字段,id(主键 自增)、date(日期,string)、motto(名言,Text)、img(img_url,string)
爬虫爬取了相应信息后,用pymysql写入数据库,记录一下pymysql的用法
db = pymysql.connect(db_ip,user,pwd,db_name,charset='utf8') //创建连接
cursor = db.cursor() //设置游标
cursor.execute("DROP TABLE IF EXISTS t_motto") //用了mysql原生语句创建一个表
sql = """CREATE TABLE t_motto (id INT NOT NULL AUTO_INCREMENT,date CHAR(10),url CHAR(80),motto TEXT(300),PRIMARY KEY (`id`))"""
cursor.execute(sql) //执行mysql语句
db.close() //关闭连接
插入数据:
db = pymysql.connect(db_ip,user,pwd,db_name,charset='utf8') //创建连接
cursor = db.cursor() //设置游标
sql = "INSERT INTO t_motto(date,url, motto) VALUES ( '%s', '%s', '%s')" % ('2019-05-23', './0604.jpg', '难来')
try:cursor.execute(sql) //尝试执行mysql语句db.commit()
except:db.rollback() //回档
db.close()
设置定时脚本
我的服务器是ubuntu系统,因此我使用了linux系统的crontab执行定时任务(当然也可以用python的定时模块APScheduler,个人感觉还是crontab好用)
这里有个小坑,我发现ONE并不是过了晚上十二点就马上更新名言,于是我将定时脚本设置为早上六点执行,这样比较保险
crontab
文件路径:/etc/crontab
文件内容:
#运行环境
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin#分(0-59) 小时(1-23) 日(1-31) 月(1-12) dayofweek周几(0-6) 用户权限 执行的命令
m h dom mon dow user command# *表示所有可用值 ‘/’可以用来表示每隔一段时间 minute:*/2表示每两分钟 run-parts表示运行文件夹所有脚本#写一个shell脚本用于执行python脚本,在crontab文件中新增一行定时执行该shell脚本的指令
//查询所有用户的定时任务
cat /etc/passwd | cut -f 1 -d : |xargs -I {} crontab -l -u {} //查看当前用户的定时任务
crontab -l
后端读取数据库
从相应的表中,取出id最大的数据,用于显示在前端界面。
这里要注意图片路径问题,后端框架一般只认相对路径,如果在数据库里写的是绝对路径,就要再做一次转换。