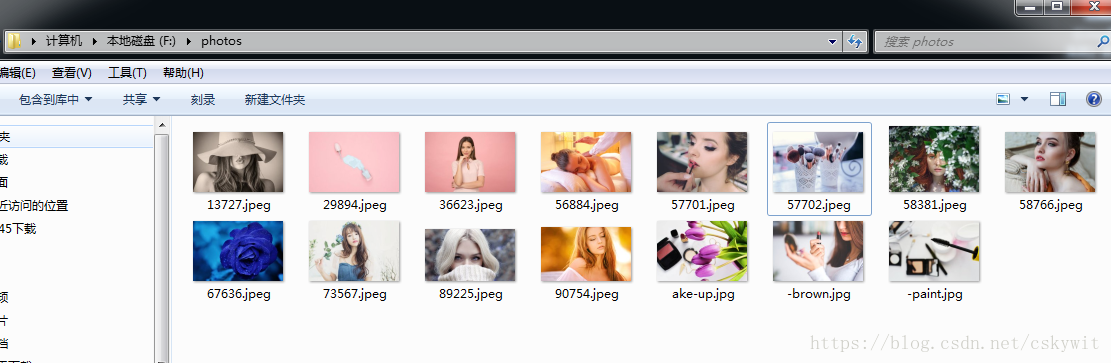
PEXELS网站上的图片素材,质量很高,可以免费用于个人和商业用途,但是搜索功能不能用中文,这里结合百度翻译API完成搜索路径的构建。由于百度翻译API为个人申请使用,这里用XXX代替,需要的童鞋可以自己申请免费key。代码如下:
from bs4 import BeautifulSoup
import requests
import json
import random
import hashlibappid = 'XXXXX' #这里换成自己申请的
key = 'XXXXX' #这里换成自己申请的img_list=[]
save_path = 'F://photos/'
url_path = 'https://www.pexels.com/search/'
headers ={'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'
}def Chinese_to_English(word): #调用百度翻译API进行中翻英url = 'http://api.fanyi.baidu.com/api/trans/vip/translate?'# 需要翻译的文本q = word# 原语言from_language = 'zh'# 目的语言to_language = 'en'# 随机数salt = random.randint(32768, 65536)# 签名sign = appid + q + str(salt) + keysign = sign.encode('utf-8')sign_new = hashlib.md5(sign).hexdigest()# 生成URLnew_url = url + 'q=' + q + '&from=' + from_language + '&to=' + to_language + '&appid=' + appid + '&salt=' + str(salt) + '&sign=' + sign_newres = requests.get(new_url)json_data = json.loads(res.text)return json_data["trans_result"][0]["dst"]word = input('请输入要下载的图片类型:')
url = url_path + Chinese_to_English(word)+'/'
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('article > a > img')
#print(soup.prettify())
for img in imgs:photo_src = img.get('src')img_list.append(photo_src)print(photo_src)
for item in img_list:data = requests.get(item, headers=headers)fp = open(save_path+item.split('?')[0][-10:],'wb')fp.write(data.content)fp.close()输入美女,可以看到自动构建了URL:'https://www.pexels.com/search/Beauty/'查看路径下已经将图片下载下来