pandas的read_html()函数是将HTML表转换为pandas内部的DataFrame类型的快速便捷的方法。更直白地说,对于专门写爬取表格的Python从业者来说, 此函数简直就是懒人一大利器,你无需重做轮子如何使用Cython去写一个table表格的解释器。因为Pandas底层基于lxml+numpy+openpyxl这些底层库做了高度的Cython优化。在本文中,笔者粗略地讲解pandas.read_html()读取网上的表格和基本的数据格式化操作。
read_html()大法,好~!
直奔主题吧,当然你要给一个包含表格的网站url传递给read_html函数
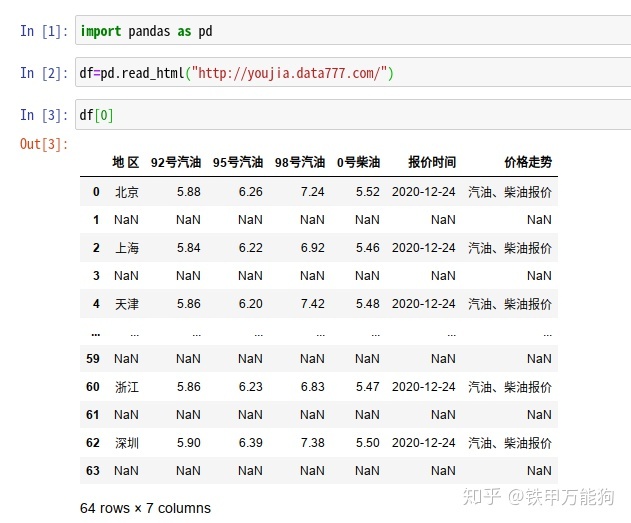
read_html会返回这些表的DataFrame列表,即便整个网站有一个表也会包含在list中。因此需要访问具体的DataFrame,必须添加下标访问符,例如
df[0]如果需要查看当前网站有多少张表,使用Python默认的len函数查看就OK了。
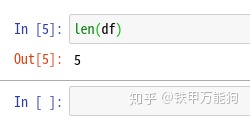
dropna()大法,好~
上面的有一些NaN的无效数据,我们需要清理,怎么做呢?如果用惯panda做数据采集的话,那么应该知道dropna大法好~
drop大法~好!
对于一些行或列的单元格有不连续多个的表格,我们要去除NaN这里需要细说一下dropna的几种情况,例如我们要删除整列都是NaN的列
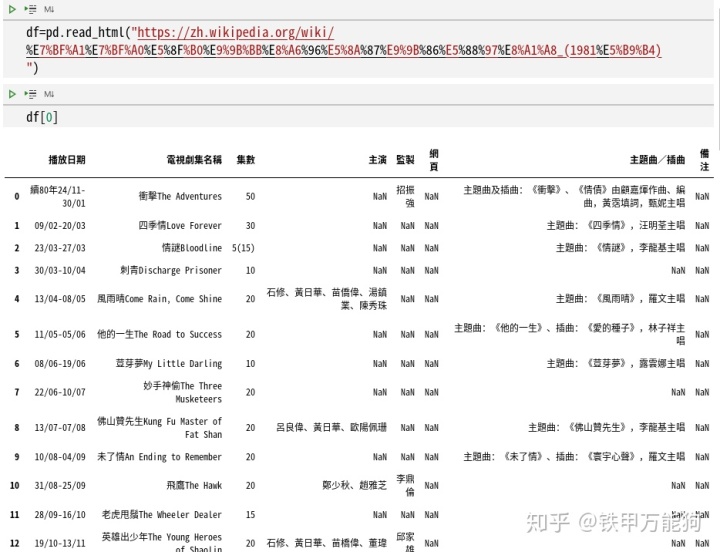
就需要用到drop方法,例如如下,第一个参数是列名,第二个参数是axis=1表示删除的列,若axis=0删除的行,inpace=True表示在当前dataFrame所在堆内存区域执行删除,而不额外产生新的dataFrame内存副本。
df[0].drop('網頁',axis=1,inplace=True)
df[0].drop('備注',axis=1,inplace=True)
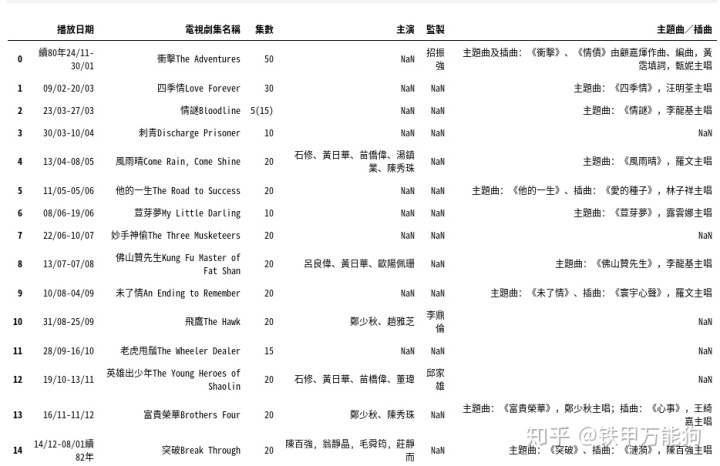
但上面的表格,笔者仍然不满意,认为主演一列有NaN的行都是无意义的数据,需要将[主演]的所在列,若为NaN的单元格的相关行都删掉,要怎么处理呢?
我们介绍的是pandas的isnull函数,我们将“主演”的那一列传递给isnull函数,如下所示
pd.isnull(df[0]['主演'])或结合dataframe的iloc下标操作符筛选出“主演”列(索引列为3),并调用isnull()方法
df[0].iloc[:,3].isnull()如下所示,若当前所在列的单元格包含NaN,那么就返回True,反之返回False
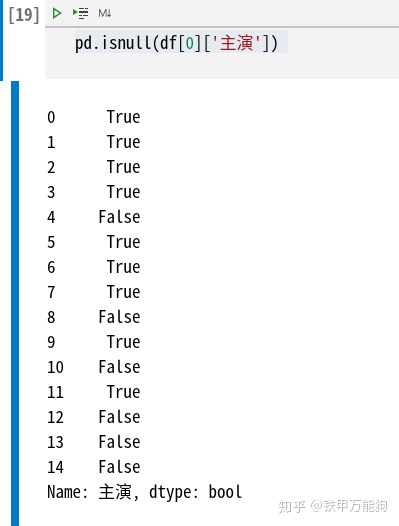
但这样还不够的,我们需要将isnull返回所在列的单元格包含NaN的情况,包装为一个Index对象。
cellIsNaN=df[0].index[df[0].iloc[:,3].isnull()]或
cellIsNaN=df[0].index[pd.isnull(df[0]['主演'])]此时,我们可以将cellIsNaN该缓存的Index对象,传递给datafram实例的drop方法
df[0].drop(cellIsNaN,axis=0,inplace=True)那么最终在“主演”所在列包含NaN的行都会被删除
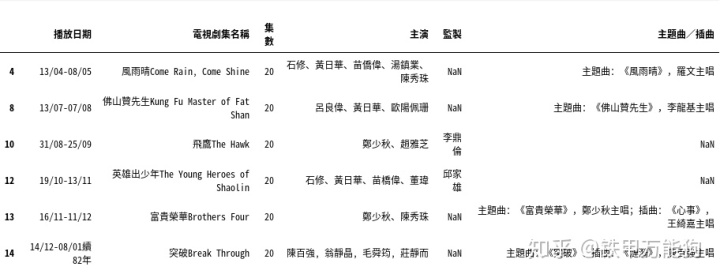
如果你只想保留前5列的所有数据,可以使用iloc索引操作符
df[0].iloc[:,[0,1,2,3,4]]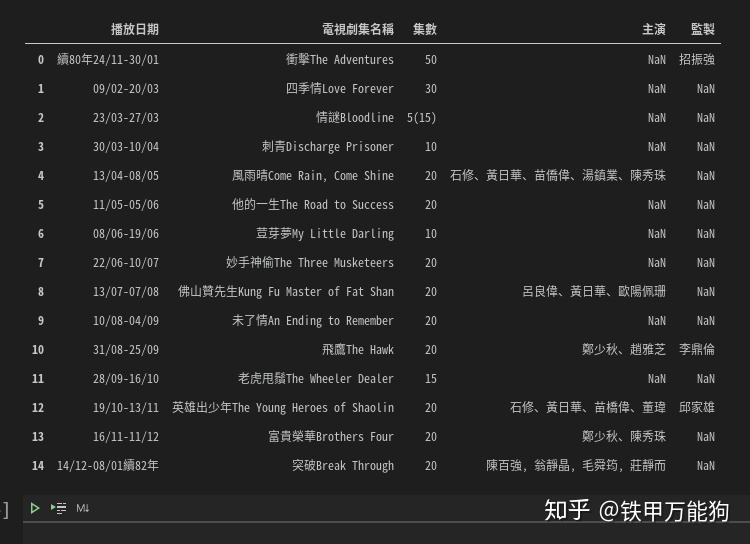
如果基于列的索引值,删除某一列的数据,例如第6列的索引是5,可以这样操作
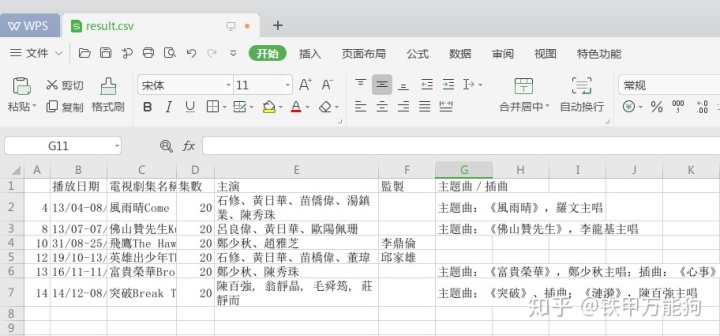
df.drop(df.columns[5],axis=1,inplace=True)最后,将上表的数据,另存为csv文本,使用to_csv()方法
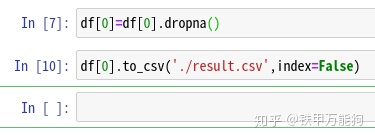
输出如下图
小结
写本文的目地是其实是一篇预热文章,为后面写有关Python中型爬虫项目做铺垫的。我的那个Python爬虫用到了Pandas库。



![网站安装打包 修改app.config[六]](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)