市面上已经有众多【AI伪原创】工具,看产品说明,介绍是基于NPL卷积神经网络千万语料库机器学习生成的文章。
百度“AI伪原创”,随便找一款产品,测试一下伪原创效果:
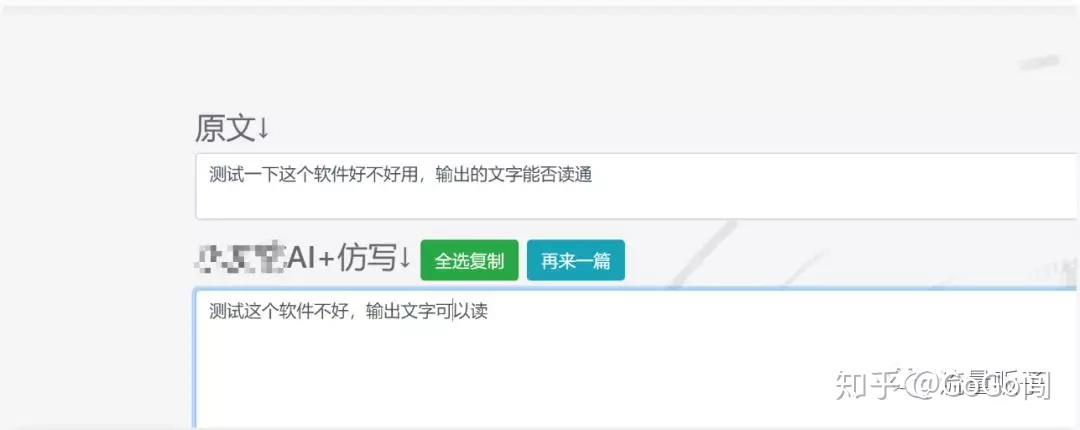
巧了,这个伪原创的内容,跟Google中英互译两次的结果一样:


所以我们要实现市面上“AI伪原创”的功能,不需要搞“NPL卷积神经网络千万语料库机器学习”神马的,只要调用Google翻译,执行“中--->英--->中”两次翻译即可。于是google搜罗并修改一番,见代码:
import requests
import json
from bs4 import BeautifulSoup
import execjs
from aip import AipNlp""" 你的 APPID AK SK """
APP_ID = 'you id'
API_KEY = 'you api key'
SECRET_KEY = 'you secret key'client = AipNlp(APP_ID, API_KEY, SECRET_KEY)class Py4Js():def __init__(self): self.ctx = execjs.compile(""" function TL(a) { var k = ""; var b = 406644; var b1 = 3293161072; var jd = "."; var $b = "+-a^+6"; var Zb = "+-3^+b+-f"; for (var e = [], f = 0, g = 0; g < a.length; g++) { var m = a.charCodeAt(g); 128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512) && g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 + ((m & 1023) << 10) + (a.charCodeAt(++g) & 1023), e[f++] = m >> 18 | 240, e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224, e[f++] = m >> 6 & 63 | 128), e[f++] = m & 63 | 128) } a = b; for (f = 0; f < e.length; f++) a += e[f], a = RL(a, $b); a = RL(a, Zb); a ^= b1 || 0; 0 > a && (a = (a & 2147483647) + 2147483648); a %= 1E6; return a.toString() + jd + (a ^ b) }; function RL(a, b) { var t = "a"; var Yb = "+"; for (var c = 0; c < b.length - 2; c += 3) { var d = b.charAt(c + 2), d = d >= t ? d.charCodeAt(0) - 87 : Number(d), d = b.charAt(c + 1) == Yb ? a >>> d: a << d; a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d } return a } """)def getTk(self,text):return self.ctx.call("TL",text)def buildUrl(text,tk,language):baseUrl='https://translate.google.cn/translate_a/single'baseUrl+='?client=t&'if language == 'en-zh':baseUrl+='s1=en&'baseUrl+='t1=zh-CN&'baseUrl+='h1=zh-CN&'elif language == 'zh-en':baseUrl+='sl=zh-CN&'baseUrl+='tl=en&'baseUrl+='hl=zh-CN&'baseUrl+='dt=at&'baseUrl+='dt=bd&'baseUrl+='dt=ex&'baseUrl+='dt=ld&'baseUrl+='dt=md&'baseUrl+='dt=qca&'baseUrl+='dt=rw&'baseUrl+='dt=rm&'baseUrl+='dt=ss&'baseUrl+='dt=t&'baseUrl+='ie=UTF-8&'baseUrl+='oe=UTF-8&'baseUrl+='otf=1&'baseUrl+='pc=1&'baseUrl+='ssel=0&'baseUrl+='tsel=0&'baseUrl+='kc=2&'baseUrl+='tk='+str(tk)+'&'baseUrl+='q='+textreturn baseUrldef translate(language,text):header={'authority':'translate.google.cn','method':'GET','path':'','scheme':'https','accept':'*/*','accept-encoding':'gzip, deflate, br','accept-language':'zh-CN,zh;q=0.9','cookie':'','user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36','x-client-data':'CIa2yQEIpbbJAQjBtskBCPqcygEIqZ3KAQioo8oBGJGjygE='}url=buildUrl(text,js.getTk(text),language)res=''try:r=requests.get(url)result=json.loads(r.text)#print (result)if result[7]!=None:# 如果我们文本输错,提示你是不是要找xxx的话,那么重新把xxx正确的翻译之后返回try:correctText=result[7][0].replace('<b><i>',' ').replace('</i></b>','')print(correctText)correctUrl=buildUrl(correctText,js.getTk(correctText),language)correctR=requests.get(correctUrl)newResult=json.loads(correctR.text)res=newResult[0][0][0]except Exception as e:print(e)for r in result[0]: if r[0] is not None: res += r[0]else:for r in result[0]: if r[0] is not None: res += r[0]except Exception as e:res=''print(url)print("翻译"+text+"失败")print("错误信息:")print(e)finally:return resdef dnnlm(text):dnn = client.dnnlm(text)return dnn["ppl"]text = "测试一下这个软件好不好用,输出的文字能否读通"if __name__ == '__main__':js=Py4Js()yw = translate('zh-en',text)res_enzh = translate('en-zh',yw)print ("原文:",text)print ("英文:",yw)print ("伪原创:",res_enzh)#print (dnnlm(text),dnnlm(res_enzh))
输出结果与Google翻译一致:

那么问题来了,这种中英中互译两次出来的文字,搜索引擎能否看出来呢?我们找下百度AI开放平台,自然语言分析里有一项“DNN语言模型”,文档中说明可以判断句子是否符合语言表达习惯。我姑且理解为,判断一句话是人写的概率有多大
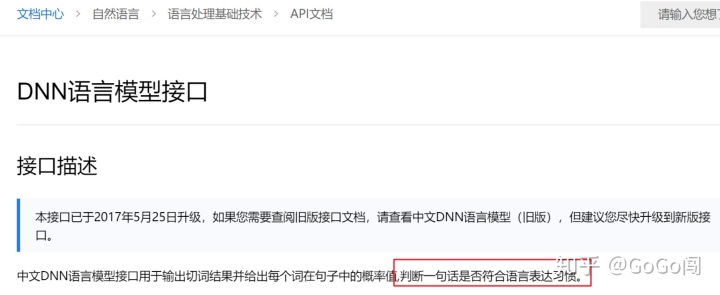
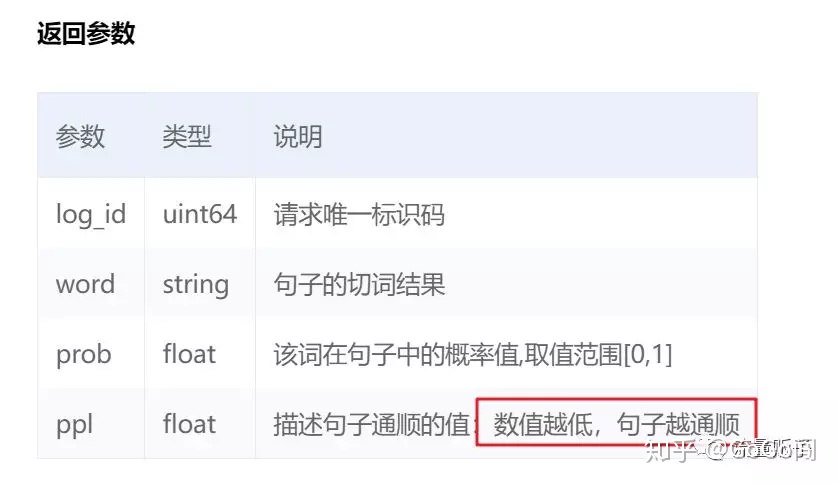
我们依次跑下原始句子,和伪原创句子的通顺度:

看来对百度爸爸而言,原始句子通顺的多。我们再多测试几个句子:

蜜汁尴尬^1

蜜汁尴尬^2

蜜汁尴尬^3
一些搬运英文视频,添加中文字幕;或通过音频生成文章的自媒体,同理;
微信公众号---->右下角