目录
- 一、需求信息
- 二、过程感触
- 三、实战code
一、需求信息
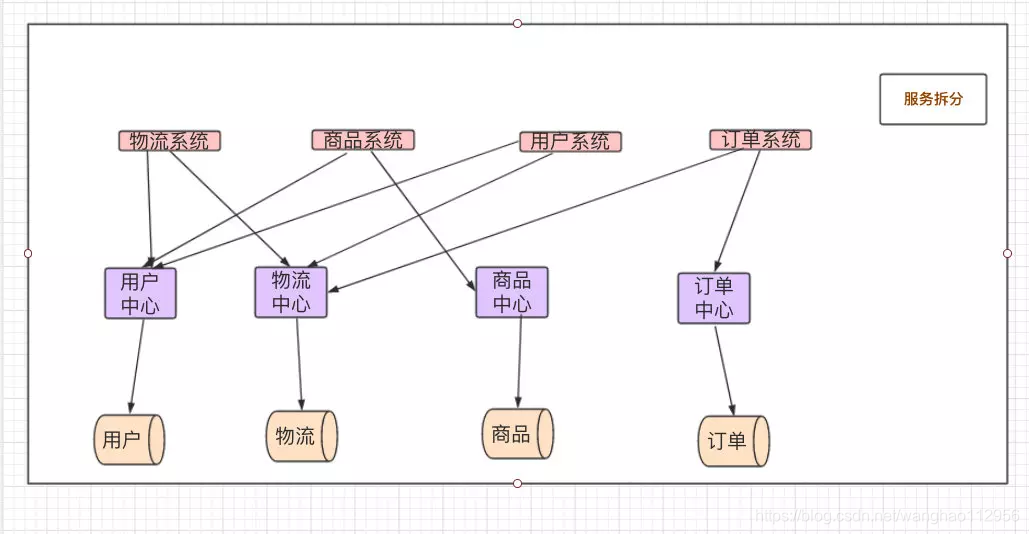
需要信息: 每个内容下开篇的索引号、发布机构、组配分类、标题、发布时间和链接地址,部分实例如下图:

上图中左侧的目录结构对应的刊布信息中的如下信息:

题外话:有些日子没有爬取过信息了,本来就是个菜鸟,时间间隔的一久,真的感觉忘得光光的。有种重头再来的感觉。
还是要时常回头看看,不时的回顾回顾,不然知识它真的不进脑子啊。
二、过程感触
爬虫只是自己之前突发想法,就看了一点书籍,顺带简单练了练手,接触的很是浅显,诸如怎么用Scrapy这种专业的方式去获取,就一直没研究。或许是现在没啥需求吧,学习的动力也就不足。
言归正传,目前初步的一个体验就是看到的网页的源码信息,自己找不到对应的 真实 地址信息,因此时常扑空。如果找到了地址信息,获取具体的信息的逻辑加工,反倒变得简单了。毕竟获取的信息都是很规范化的。
比如这个目录结构,我就是从这个地方才发现:

这才打开了实现的一道口子,至于具体文章的信息获取,这个位置的信息就很好处理,没有那么多的“坑”。
爬虫,某种程度上就是在找获取的信息地址的跳转间的逻辑关系,理清了这一点,其他的具体信息的获取、存放,感觉相对来说就不是那么复杂了。当然,还有一个最大的问题就是反爬问题,这个问题就复杂,还不在自己的重点考虑范围,毕竟获取的信息基本都是公开的,也不涉及很多的信息和很大的数据量。
时常还是要爬爬,不然真的就不会了。
欢迎提需求,共同探讨,学习!
三、实战code
说一千,道一万,还是扎扎实实的干吧,实战为王!!!
# 导入库
from bs4 import BeautifulSoup
import re
import pandas as pd
import json
import requests
import time # url = "http://www.****.***.cn/col/col156912/index.html?vc_xxgkarea=371700000000&number=&jh=263"
get_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/**.*****.Safari/537.36","Host": "www.****.***.cn","Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6"
}
post_headers = {'Accept': '*/*','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6','Connection': 'keep-alive','Cookie': 'cod=*******************************************',# 根据自己电脑配置'Host': 'www.****.***.cn','Origin': 'http://www.****.***.cn','Referer': 'http://www.****.***.cn/module/xxgk/tree.jsp?area=&divid=div156912&showwebname=1&limit=0&standardXxgk=1&isGB=1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36','X-Requested-With': 'XMLHttpRequest'
}
tree_url = "http://www.****.***.cn/module/xxgk/tree.jsp?area=&divid=div156912&showwebname=1&limit=0&standardXxgk=1&isGB=1"
获取目录信息,以及对应的id,为了获取不同目录信息下的内容信息。
html = requests.get(tree_url,headers=get_headers)
soup = BeautifulSoup(html.text,'lxml')
mulu_tree = soup.findAll('script')[2]
mulu_split = (str(mulu_tree).split('\n'))[1].split(';">')mulu_list = [] # 存放目录名和 对应的id 信息
for i in range(len(mulu_split)):try:mulu_id = re.search(r"funclick\(.*\\\'\,\\\'",mulu_split[i])mulu_id = mulu_id.group()mulu_id = re.search(r'\'.*\',',mulu_id)mulu_id = mulu_id.group()mulu_id = mulu_id[1:-3] # infotypeIdmulu_name = re.search(r".*</a>\'\);",mulu_split[i])mulu_name = mulu_name.group()if len(mulu_name)>50:continuemulu_name = mulu_name[:-7] # 目录链的名称mulu_list.append([mulu_name,mulu_id]) except:pass
开始获取不同目录页面下的文章对应的想要获取的具体信息。
result = [] # 存放结果post_data = {'divid': 'div156912','infotypeId': 'HZA10202040206','jdid': 62,'area': '','standardXxgk': 1
}
url = 'http://www.****.***.cn/module/xxgk/search.jsp?'
num = 0
count = 0
for mulu_name,mulu_id in mulu_list:num +=1print(num,mulu_name,mulu_id)post_data['infotypeId'] = mulu_idhtml = requests.post(url,headers=post_headers,data=post_data)html.encoding='utf-8' # 将编码格式改为utf-8soup = BeautifulSoup(html.text,'lxml')first_message = soup.findAll('div',class_="zfxxgk_zdgkc")########################################################################################messages = re.findall('<a.*</a>',str(first_message),re.M)for i in range(len(messages)):try:href = "http://www.****.***.cn/"+re.findall('/art.*html',messages[i],re.M)[0] # 链接地址except:continuetitle = re.findall('title=".*"',messages[i],re.M)[0].split('"')[1] # 标题# 链接里边的信息html_two = requests.get(href,headers=get_headers)html_two.encoding='utf-8' # 将编码格式改为utf-8soup_two = BeautifulSoup(html_two.text,'lxml')message_two = soup_two.findAll('table')if message_two:fabu_date = soup_two.find('span',class_='date').text[5:-6] # 发布日期six_mes = message_two[2].findAll('td') index_num = re.sub(r'\s*','',six_mes[1].text) # 索引号gongkai = re.sub(r'\s*','',six_mes[3].text) # 公开方式fabu = re.sub(r'\s*','',six_mes[5].text) # 发布机构fenlei = re.sub(r'\s*','',six_mes[7].text) # 组配分类wenhao = re.sub(r'\s*','',six_mes[9].text) # 发文文号try:youxiaoxing = re.sub(r'\s*','',six_mes[11].text) # 有效性except:youxiaoxing=''result.append([mulu_name,mulu_id,title,href,fabu_date,index_num,gongkai,fabu,fenlei,wenhao,youxiaoxing])count +=1print(count)time.sleep(1) # 程序休眠5s
# num +=1
# if num>2:
# breakresult = pd.DataFrame(result,columns=['对应目录','目录id','标题','链接地址','发布日期','索引号','公开方式','发布机构','组配分类','发文文号','有效性'])
result.to_excel('网站信息获取结果2.xlsx')
部分结果如下: