书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现。
首先还是上代码:
#-*- coding:utf-8 -*-
importrequestsimportreimportmysql.connector#changepage用来产生不同页数的链接
defchangepage(url,total_page):
page_group= ['https://www.dygod.net/html/gndy/jddy/index.html']for i in range(2,total_page+1):
link= re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)returnpage_group#pagelink用来产生页面内的视频链接页面
defpagelink(url):
base_url= 'https://www.dygod.net/html/gndy/jddy/'headers= {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req= requests.get(url , headers =headers)
req.encoding= 'gbk'#指定编码,否则会乱码
pat = re.compile('',re.S)#获取电影列表网址
reslist =re.findall(pat, req.text)
finalurl=[]for i in range(1,25):
xurl=reslist[i][0]
finalurl.append(base_url+xurl)return finalurl #返回该页面内所有的视频网页地址
#getdownurl获取页面的视频地址和信息
defgetdownurl(url):
headers= {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req= requests.get(url , headers =headers)
req.encoding= 'gbk'#指定编码,否则会乱码
pat= re.compile('ftp',re.S)#获取下载地址
reslist =re.findall(pat, req.text)
furl= 'ftp'+reslist[0]
pat2= re.compile('(.*?)',re.S)#获取影片信息
reslist2 =re.findall(pat2, req.text)
reslist3= re.sub('[
]','',reslist2[0])fdetail= reslist3.split('◎')return(furl,fdetail)#创建表movies
defcreatetable(con,cs):#创建movies表,确定其表结构:
cs.execute('create table if not exists movies (film_addr varchar(1000), cover_pic varchar(1000), name varchar(100) primary key,\
ori_name varchar(100),prod_year varchar(100), prod_country varchar(100), category varchar(100), language varchar(100), \
subtitle varchar(100), release_date varchar(100), score varchar(100), file_format varchar(100), video_size varchar(100), \
file_size varchar(100), film_length varchar(100), director varchar(100), actors varchar(500), profile varchar(2000),capt_pic varchar(1000))')#提交事务:
con.commit()#将电影地址和简介插入表中
definserttable(con,cs,x,y):try:
cs.execute('insert into movies values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)',\
(x,y[0],y[1],y[2],y[3],y[4],y[5],y[6],y[7],y[8],y[9],y[10],y[11],y[12],y[13],y[14],y[15],y[16],y[17]))except:pass
finally:
con.commit()if __name__ == "__main__":
html= "https://www.dygod.net/html/gndy/jddy/index.html"
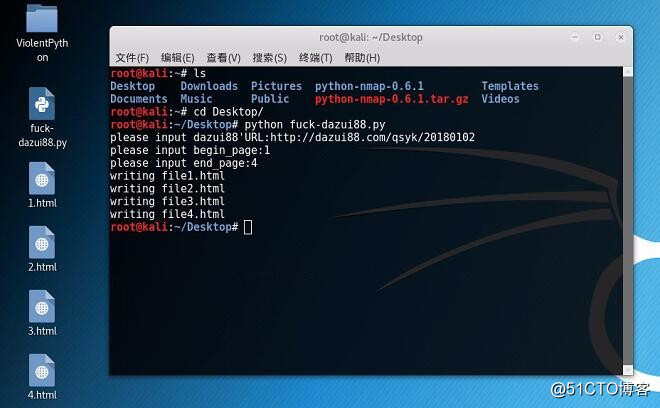
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages= input('请输入需要爬取的页数:')
createtable
p1=changepage(html,int(pages))#打开数据库
conn = mysql.connector.connect(user='py', password='Unix_1234', database='py_test')
cursor=conn.cursor()
createtable(conn,cursor)#插入数据
j =0for p1i inp1 :
j= j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2=pagelink(p1i)for p2i inp2 :
p3,p4=getdownurl(p2i)if len(p3) ==0 :pass
else:
inserttable(conn,cursor,p3,p4)#关闭数据库
cursor.close()
conn.close()print('所有页面地址爬取完毕!')
用到的知识点和前面比,最重要是多了数据库的操作,下面简要介绍下python如何连接数据库。
一、python中使用mysql需要驱动,常用的有官方的mysql-connect-python,还有mysqldb(Python 2.x)和pymysql(Python 3.x),这几个模块既是驱动,又是工具,可以用来直接操作mysql数据库,也就是说它们是通过在Python中写sql语句来操作的,例如创建user表:
cursor.execute('create table user (id int, name varchar(20))')
#这里的create table语句就是典型的sql语句。
二、还有很多情况下我们用ORM(object relational mapping)即对象映射关系框架,将编程语言的对象模型和数据库的关系模型(RDBMS关系型数据库)进行映射,这样可以直接使用编程语言的对象模型操作数据库,而不是使用sql语言。同样创建user表:
user=Table('user',metadata,
Column('id',Integer),
Column('name', String(20))
)
metadata.create_all()
#这里可以看到根本没有sql语句的影子,这样我们可以专注在Python代码而不是sql代码上了。(注意ORM并不包含驱动,如要使用同样要安装前面提到的驱动)
如有兴趣可以自行学习,这不是本文的重点。为简单起见,文中用的是mysql-connect-python。
正则匹配部分也很简单,因为源网页比较规则,如下网页图和对应的源代码:
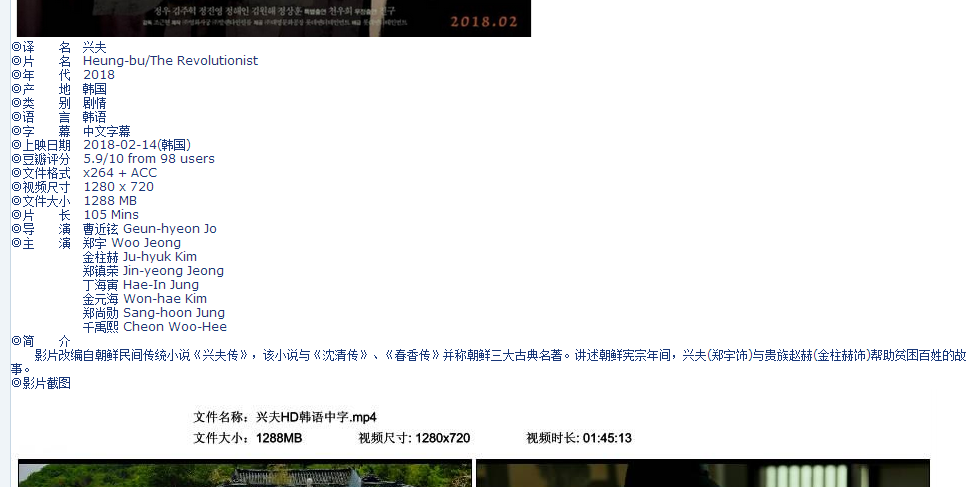
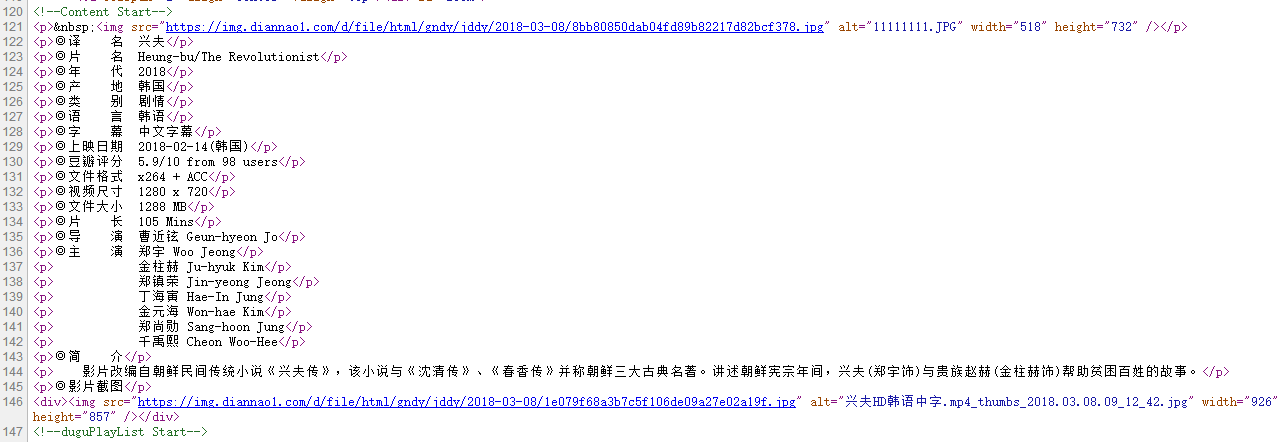
直接用◎匹配即可。
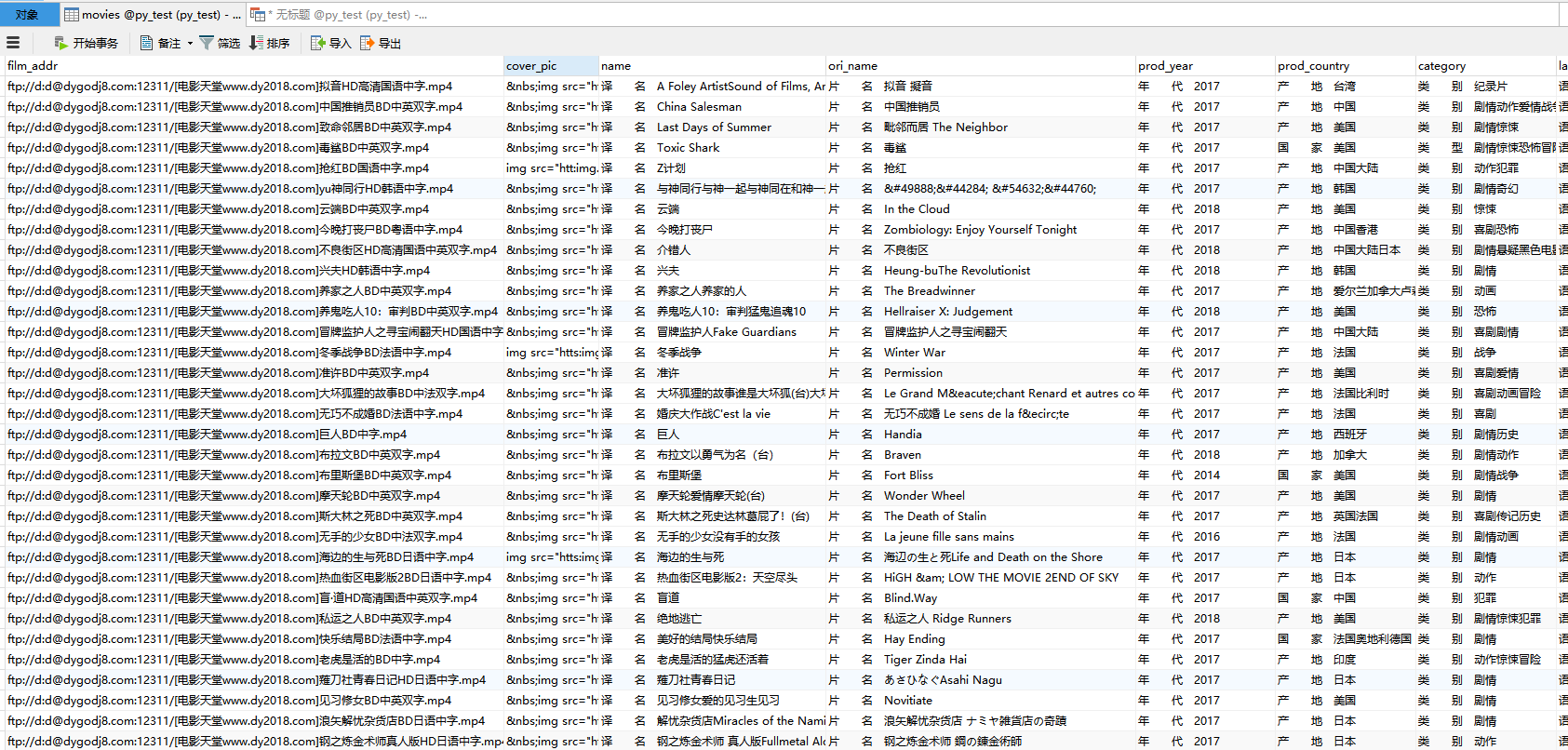
程序运行完后,数据都写入movies表中。
比如我想筛选豆瓣评分>7的,
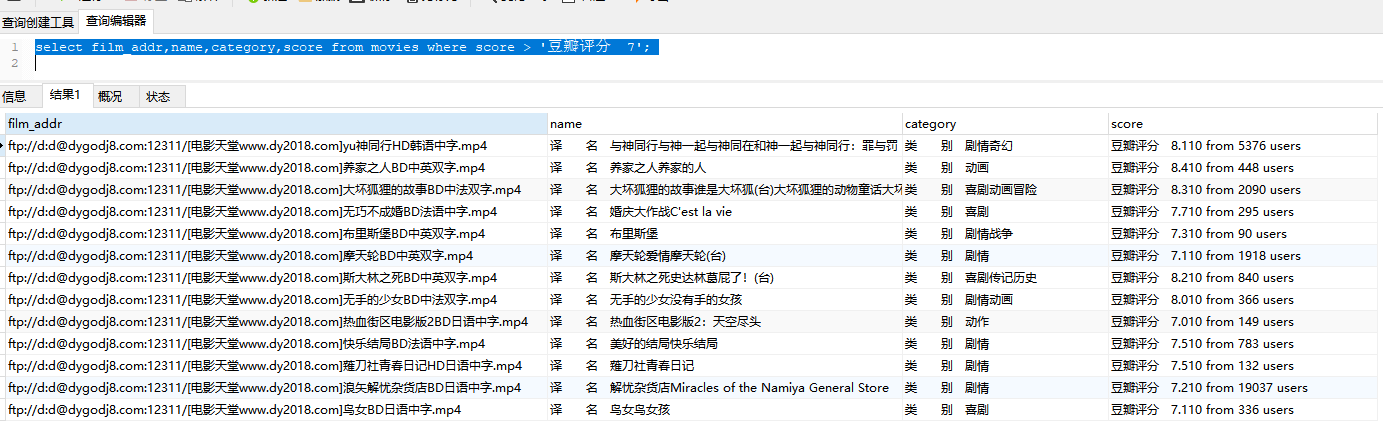
是不是很简单,你GET到了吗?


![一步步构建大型网站架构 转http://kb.cnblogs.com/page/99549/]](http://b91.photo.store.qq.com/psb?/d54c06d7-41b0-45b5-9b1b-bda00a30ac8e/4iZge65.RH1eXl8fK3uWjWOEWltqu8asEUUY7fYOqvk!/b/YcYcQjaFSQAAYh9GSzYYSgAA)