更多中文编程推广过程内情, 请关注“用中文编程”微信公众号.
作者:乘风龙王
原文:https://zhuanlan.zhihu.com/p/51309019
为保持源码格式, 转载时使用了截图. 原文中的源码块为文本格式.
我比较喜欢看小说,在网络上看小说一般有2种选择,正版或盗版。正版要钱,盗版要么只能在线阅读,要么下载下来一堆广告。既然学了python就应该写点爬虫练练手,把网络小说爬下来。
本文章需要的python第三方库:
- requests(获取网页内容)
- BeautifulSoup4(解析网页内容)
本文章需要读者具备python基础知识,并且我不会对文章中所出现的标准库、第三方库的每个类/函数的作用进行解释,请大家自行查阅资料。我不会对代码中的中文命名进行解释。
寻找目标
由于那些著名的小说网站具有很强的版权意识,防盗版措施做得很好,要把小说内容爬下来不是很容易。所以我选择一个盗版小说网站作为爬虫目标。
嗯,全是盗版。
首先编写代码获取文档内容。

打开其中一本小说目录页,记住地址,然后调用 f获取文档 测试代码是否可以运行。
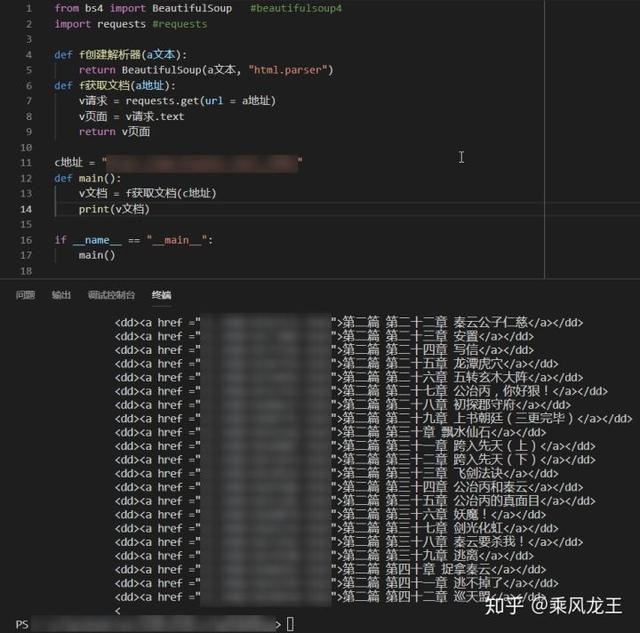
看起来只输出了一半内容,实际上 v文档 已经包含了所有内容,只不过是字符串太长了被print截断而已。
框架
浏览一下小说网站结构,每个小说页面可以分为目录页、正文页。
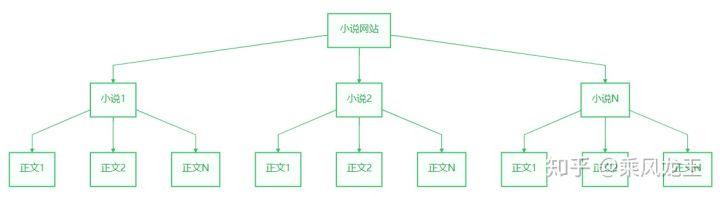
设计2个接口,分别取名 I小说 和 I章节,I小说 用来提取小说信息和目录,I章节 用来提取章节信息和小说正文。同时定义 I文档,负责从网站上获取文档

提取目录
先查看一下目录页的内容
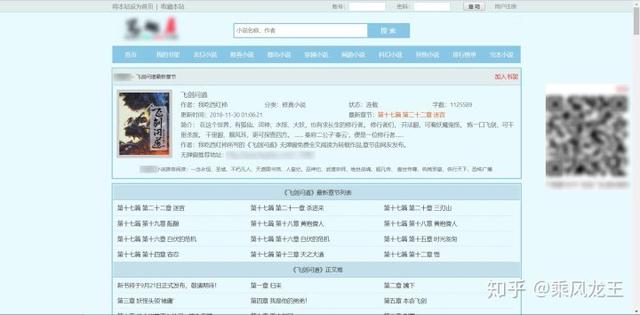
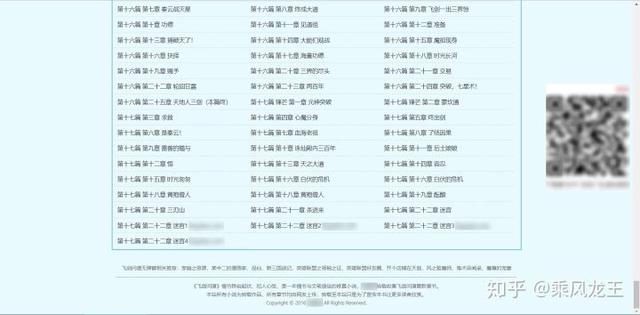
从图中可以看到,目录最前面有最新章节,目录最后还有重复章节,这些都是需要去除掉的,保留从正文卷开始的章节。
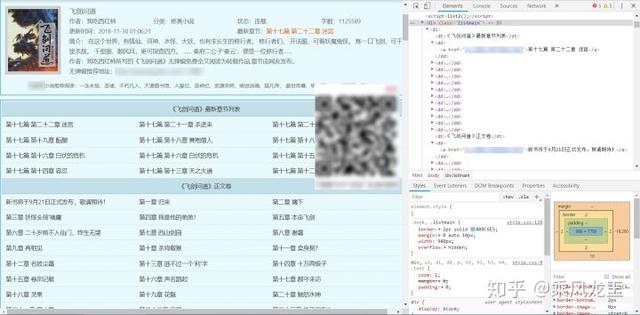
检查网页元素后可知道,目录包含在

提取目录的代码很简单,把上面提到的
修改一下主函数,运行代码
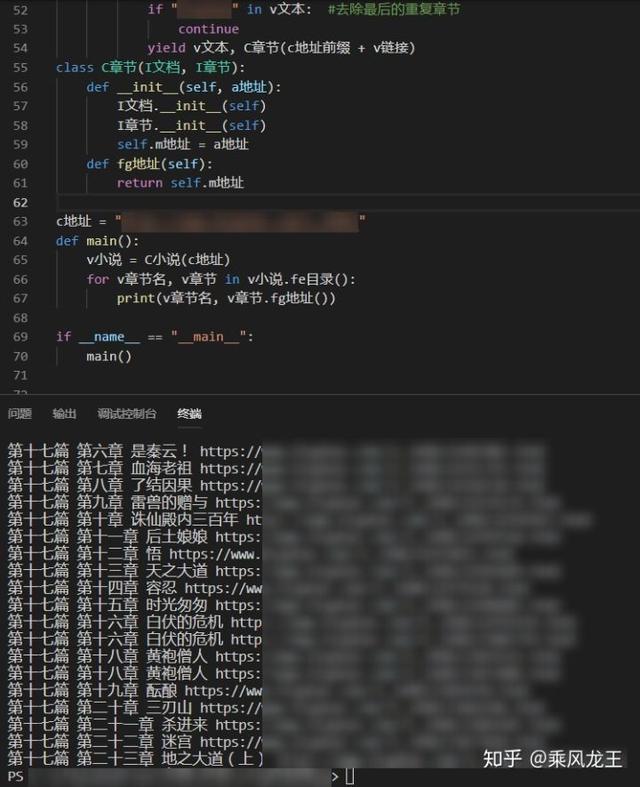
似乎还有重复章节。我点开一些重复章节看了一下,地址不一样但是内容是一样的,应该是网站录入时出了问题。这个我就不管了。
提取正文
提取完目录后,再看一下正文页。
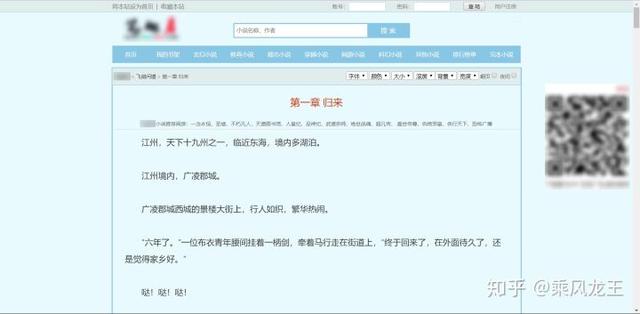
发现正文最底下有广告链接,这个也要去掉。
分析网页元素,可以知道正文全部包含在

修改主函数测试代码是否可用

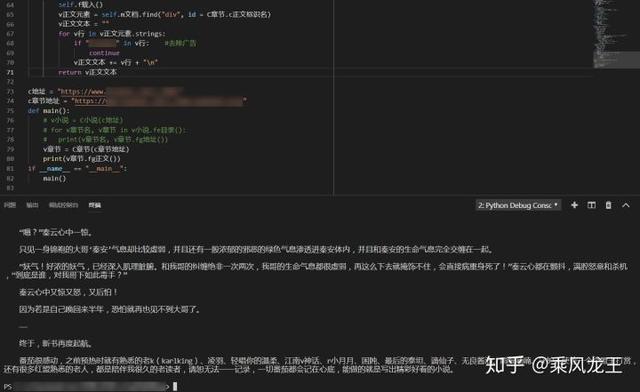
从运行结果看,爬到的正文有空行有缩进。虽然没有问题,但是小说最终是要放进阅读器里慢慢看的,并不是所有的阅读器都能正确处理空行和缩进,所以还要在代码里对正文进一步处理。
写一个函数叫 f处理正文,负责处理乱七八糟的空行和缩进

然后修改 C章节.fg正文,在返回字符串时做一些处理
return f处理正文(v正文文本)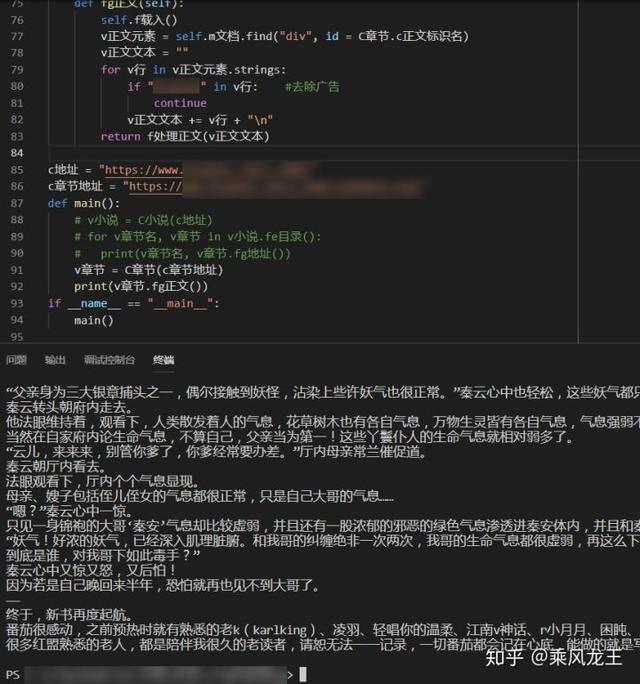
这样看起来好多了。
保存
确认可以爬到目录和正文之后,接下来就是把正文保存到电脑上。

在实际测试中,网站经常返回503。如果在代码里增加错误重试功能会导致代码变得又臭又长,这里我就不写了。
打开下载下来的文本文件看看。因为网站经常503,只爬了前几章就断掉了,所以没爬完。
结尾
上面的代码可以从一个特定的小说网站下载小说。但是这个网站是盗版小说网站,容易被封掉。或者有各式各样的理由需要从另外一个网站下载小说呢?
由于上面已经写过一些代码了,只需要照葫芦画瓢,重新写个 C小说 和 C章节 就行了。其他什么都不用动。
文章里的代码省略了很多细节,比如HTTP请求头、文档编码处理、异常处理,只保留最重要的爬虫代码。完整代码我发到了github上,见:https://github.com/cflw/cflw_py。
最后请大家以学习研究为目的写爬虫,毕竟爬别人的劳动成果是不好的,请大家多多支持正版。