1. 概述
因为无聊,闲来没事做,故突发奇想,爬个种子,顺便学习爬虫。本文将介绍使用Spring/Mybatis/webmagic等框架构建项目并爬取种子磁链。
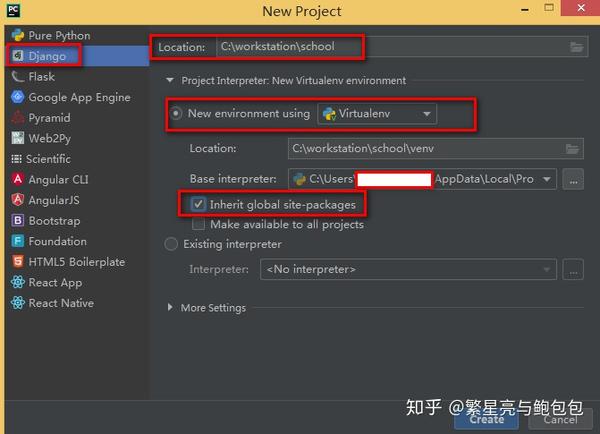
2. 项目搭建
如下图为本项目的工程结构,主要代码实现在Spider包中。

3. 数据库设计
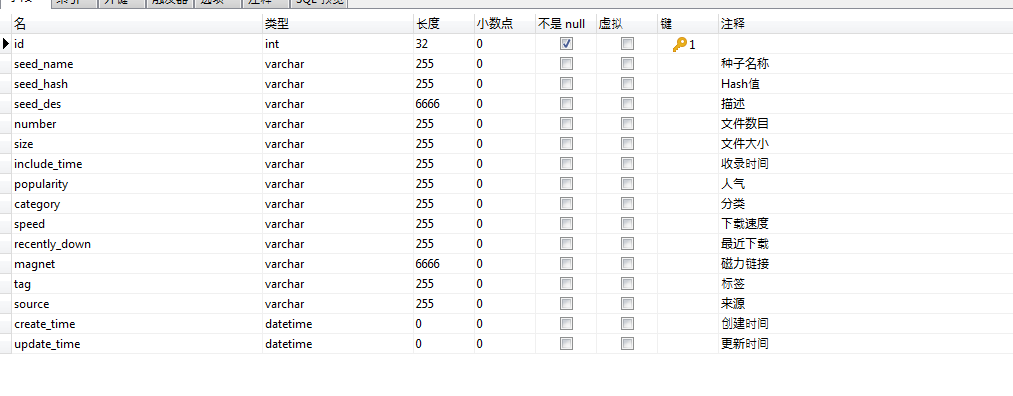
参考众多的种子网站,找到描述种子的常用属性,如下:
4. 程序实现
1. 爬虫配置
在抓取种子之前,首先要确定所要抓取的网站地址、编码、抓取时间间隔、重试次数等信息,如下:
//设置网站源
private static String netSite="PushBT";
private Site site = Site.me().setDomain("http://www.pushbt.com")
.setCharset("UTF-8").setSleepTime(1000)//编码
.setRetryTimes(3);//重试次数
private static String BASE_URL="http://www.pushbt.com";
2. 逻辑编写
process方法是爬虫的核心接口,所有的属性抽取都在此方法中实现
@Override
public void process(Page page) {
//定义如何抽取页面信息,并保存下来
List links = page.getHtml().xpath("//table[@class='items']//tr[@class='odd']/td[2]/a/@href").all();
//将需要待爬的网页地址都存下来,以待后续从中取出
targetUrlList=StringUtil.linkURL(BASE_URL, links);
page.addTargetRequests(targetUrlList);
Seeds seed = new Seeds();
// 获取名称
String name = page.getHtml().xpath("//ul[@id='filelist']//li/span/@title").toString();
if (name==null||"".equals(name)||service.isExistByName(name)) {//名称为空,则跳过;已存在(true),则跳过
page.setSkip(true);
count++;
LOG.info("skip the "+count+" ,title : "+name);
return;
}
page.putField("name", name);
seed.setSeedName(name);
// 获取hash值(无hash值,默认为null)
//String hash = page.getHtml().xpath("//p[@class='dd desc']//b[2]/text()").toString();
page.putField("hash", null);
seed.setSeedHash(null);
// 描述(没有描述信息,则默认为名称)
//String desc = page.getHtml().xpath("//div[@class='dd filelist']/p/text()").toString();
page.putField("desc", name);
seed.setSeedDes(name);
// 文件个数
String number = page.getHtml().xpath("//ul[@class='params-cover']/li[4]/div[@class='value']/text()").toString();
page.putField("number", number);
seed.setNumber(number);
// 文件大小
String size = page.getHtml().xpath("//ul[@class='params-cover']/li[5]/div[@class='value']/text()").toString();
page.putField("size", size);
seed.setSize(size);
// 获取收录时间
String includeDate = page.getHtml().xpath("//ul[@class='params-cover']/li[2]/div[@class='value']/text()").toString();
page.putField("includeDate", includeDate);
seed.setIncludeTime(includeDate);
//最近下载时间
String recentlyDown = page.getHtml().xpath("//ul[@class='params-cover']/li[3]/div[@class='value']/text()").toString();
page.putField("recentlyDown", recentlyDown);
seed.setRecentlyDown(recentlyDown);
// 人气
String popularity = page.getHtml().xpath("//ul[@class='params-cover']/li[6]/div[@class='value']/text()").toString();
page.putField("popularity", popularity);
seed.setPopularity(popularity);
// 下载速度
//String speed = page.getHtml().xpath("//p[@class='dd desc']//b[7]/text()").toString();
page.putField("speed", SpiderUtil.getSpeed(popularity));
seed.setSpeed(SpiderUtil.getSpeed(popularity));
// 获取磁力链接
String magnet = page.getHtml().xpath("//ul[@class='params-cover']/li[9]/div[@class='value']/a/@href").toString();
page.putField("magnet", magnet);
seed.setMagnet(magnet);
// 标签(在详情页面没有tag,暂时以热门搜索为tag)
List tags = page.getHtml().xpath("//div[@class='block oh']/a/span/text()").all();
page.putField("tags", tags);
seed.setTag(tags.toString());
seed.setCreateTime(new Date());
seed.setUpdateTime(new Date());
seed.setSource(netSite);
seed.setCategory("movies");
//保存到数据库
service.insert(seed);
}
3. 其它部分编写
例子用到的其他部分代码,如MVC,数据库操作等,不是本章节的重点,所以不一一介绍了
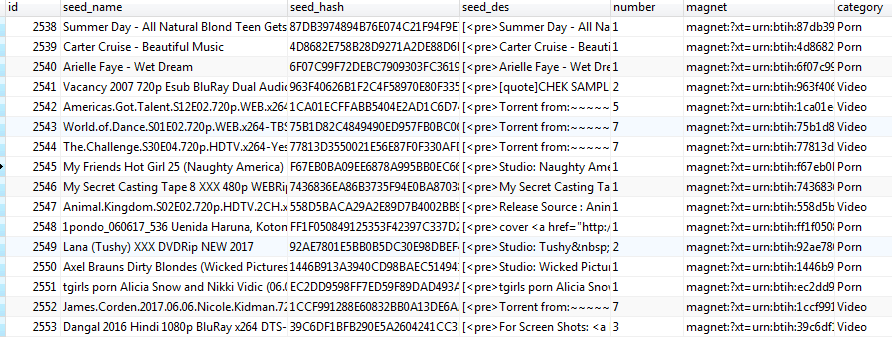
5. 成果展示
 基于webmagic的种子网站爬取
基于webmagic的种子网站爬取
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权