写在前面
最近在学vue.js,看到一个网站上有很多视频教程,但在线观看不能倍速播放,就想着用python爬虫批量下载到本地。
安装依赖
pip3 install requests
测试样例
加上序言总共有16个视频,我们用python爬虫技术批量下载到本地。
https://learning.dcloud.io/#/?vid=0
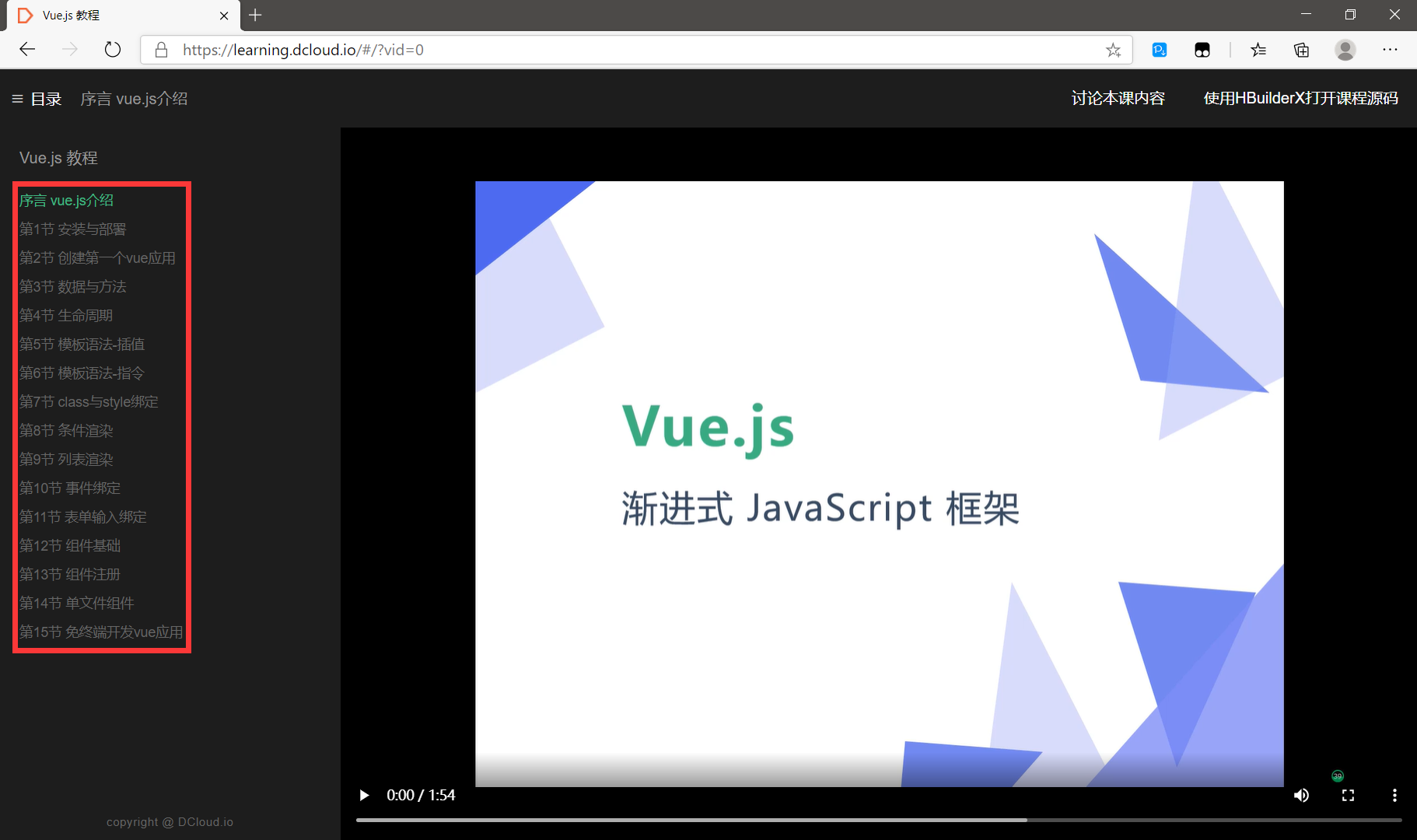
获取直链
首先我们要获取视频的下载直链。鼠标右击检查,可以直接看到视频的直链。
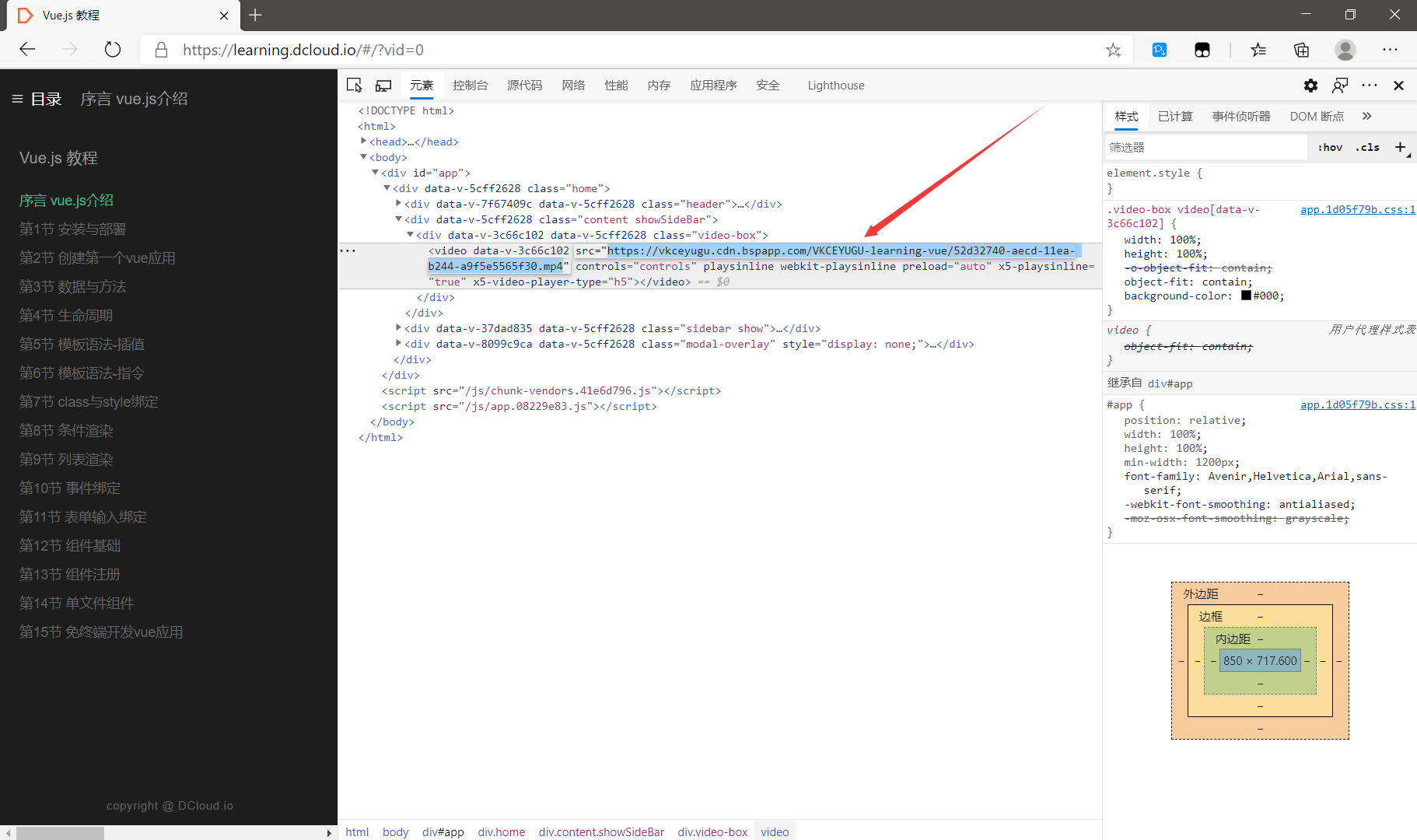
再看一下页面的源代码,发现视频的直链不见了,原来视频直链的位置变成了一个js脚本。

如果我们直接用requets库请求url的话得到的是源代码,但是源代码里面并没有视频直链,所以我们要考虑换个思路。为什么视频直链的位置会被js替换呢?
爬虫多了你就会知道,这是网页的动态加载,一定有一个js文件里面保存了视频的直链,然后每次加载网页的时候,通过js脚本将视频直链动态加载到html中。
点击网络,筛选js文件,找到了3个js文件,我们先看第一个js文件里面有没有视频直链。搜索视频的标题,直接找到了视频的直链,发现所有的视频直链都被保存到一个名为lesson_list的变量。
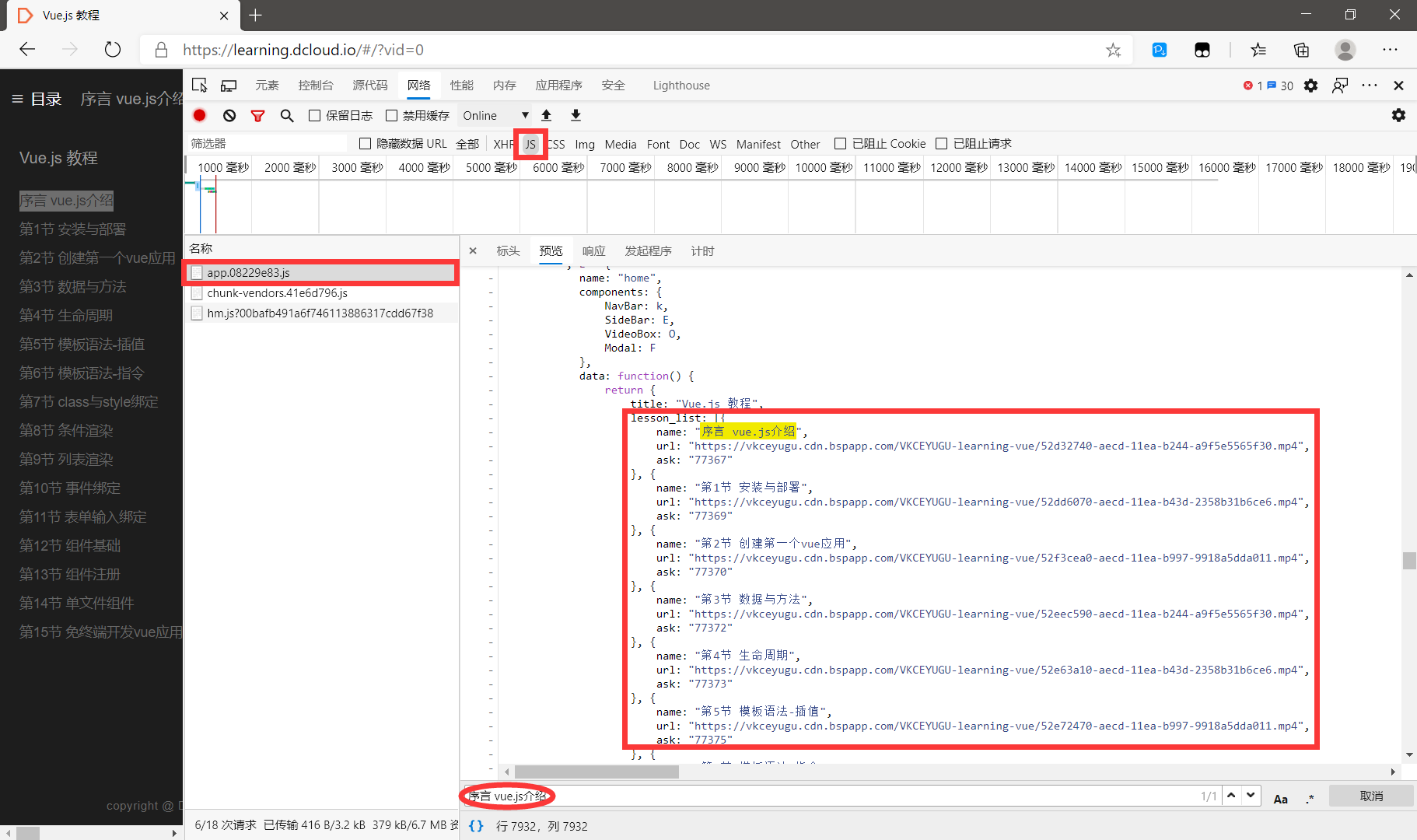
lesson_list里面保存了所有的视频名称和视频直链信息,这里为了统一,将序言改为第0节。
# lesson_list.py
lesson_list = [{
"name": "第0节 vue.js介绍",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/52d32740-aecd-11ea-b244-a9f5e5565f30.mp4",
"ask": "77367"
}, {
"name": "第1节 安装与部署",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/52dd6070-aecd-11ea-b43d-2358b31b6ce6.mp4",
"ask": "77369"
}, {
"name": "第2节 创建第一个vue应用",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/52f3cea0-aecd-11ea-b997-9918a5dda011.mp4",
"ask": "77370"
}, {
"name": "第3节 数据与方法",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/52eec590-aecd-11ea-b244-a9f5e5565f30.mp4",
"ask": "77372"
}, {
"name": "第4节 生命周期",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/52e63a10-aecd-11ea-b43d-2358b31b6ce6.mp4",
"ask": "77373"
}, {
"name": "第5节 模板语法-插值",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/52e72470-aecd-11ea-b997-9918a5dda011.mp4",
"ask": "77375"
}, {
"name": "第6节 模板语法-指令",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/98c18710-aecd-11ea-b43d-2358b31b6ce6.mp4",
"ask": "77376"
}, {
"name": "第7节 class与style绑定",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/4fe81fd0-aece-11ea-b997-9918a5dda011.mp4",
"ask": "77377"
}, {
"name": "第8节 条件渲染",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/98bad050-aecd-11ea-b680-7980c8a877b8.mp4",
"ask": "77378"
}, {
"name": "第9节 列表渲染",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/5da98c30-aece-11ea-b244-a9f5e5565f30.mp4",
"ask": "77380"
}, {
"name": "第10节 事件绑定",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/98bd6860-aecd-11ea-8bd0-2998ac5bbf7e.mp4",
"ask": "77381"
}, {
"name": "第11节 表单输入绑定",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/656e12b0-aece-11ea-a30b-e311646dfaf2.mp4",
"ask": "77382"
}, {
"name": "第12节 组件基础",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/98a06a80-aecd-11ea-8bd0-2998ac5bbf7e.mp4",
"ask": "77383"
}, {
"name": "第13节 组件注册",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/98ed7910-aecd-11ea-b997-9918a5dda011.mp4",
"ask": "78520"
}, {
"name": "第14节 单文件组件",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/79db90b0-aece-11ea-8a36-ebb87efcf8c0.mp4",
"ask": "78521"
}, {
"name": "第15节 免终端开发vue应用",
"url": "https://vkceyugu.cdn.bspapp.com/VKCEYUGU-learning-vue/7e3b8f70-aece-11ea-8ff1-d5dcf8779628.mp4",
"ask": "81004"
}]
批量下载
这里用for循环遍历每一个下载链接,然后使用之前写的一个多线程下载器下载。
from concurrent.futures import ThreadPoolExecutor
from lesson_list import lesson_list
from requests import get, head
import time
class downloader:
def __init__(self, url, num, name):
self.url = url
self.num = num
self.name = name
self.getsize = 0
r = head(self.url, allow_redirects=True)
self.size = int(r.headers['Content-Length'])
def down(self, start, end, chunk_size=10240):
headers = {'range': f'bytes={start}-{end}'}
r = get(self.url, headers=headers, stream=True)
with open(self.name, "rb+") as f:
f.seek(start)
for chunk in r.iter_content(chunk_size):
f.write(chunk)
self.getsize += chunk_size
def main(self):
start_time = time.time()
f = open(self.name, 'wb')
f.truncate(self.size)
f.close()
tp = ThreadPoolExecutor(max_workers=self.num)
futures = []
start = 0
for i in range(self.num):
end = int((i+1)/self.num*self.size)
future = tp.submit(self.down, start, end)
futures.append(future)
start = end+1
while True:
process = self.getsize/self.size*100
last = self.getsize
time.sleep(1)
curr = self.getsize
down = (curr-last)/1024
if down > 1024:
speed = f'{down/1024:6.2f}MB/s'
else:
speed = f'{down:6.2f}KB/s'
print(f'process: {process:6.2f}% | speed: {speed}', end='\r')
if process >= 100:
print(f'process: {100.00:6}% | speed: 00.00KB/s', end=' | ')
break
end_time = time.time()
total_time = end_time-start_time
average_speed = self.size/total_time/1024/1024
print(f'total-time: {total_time:.0f}s | average-speed: {average_speed:.2f}MB/s')
if __name__ == '__main__':
for lesson in lesson_list:
url = lesson['url']
name = lesson['name']
down = downloader(url, 8, name+'.mp4')
down.main()
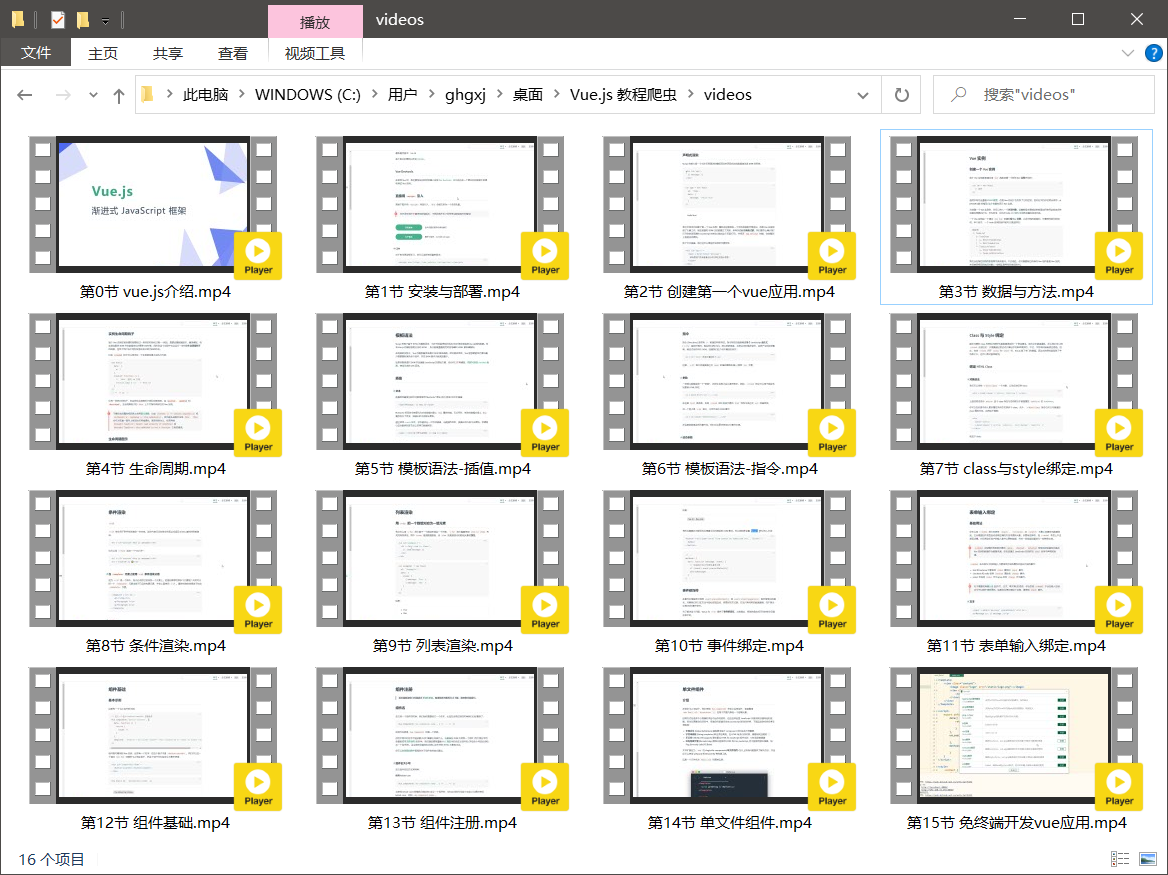
结果打印
16个视频,总计339MB,用了56s就下载完了。
process: 100.0% | speed: 00.00KB/s | total-time: 2s | average-speed: 2.47MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 6.62MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 3.72MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 4s | average-speed: 7.72MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 4s | average-speed: 5.85MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 7s | average-speed: 7.01MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 4.65MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 4s | average-speed: 6.69MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 5.88MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 4s | average-speed: 5.01MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 6.60MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 4s | average-speed: 6.20MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 5.96MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 2s | average-speed: 4.64MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 3s | average-speed: 6.02MB/s
process: 100.0% | speed: 00.00KB/s | total-time: 4s | average-speed: 6.80MB/s
总结展望
有时候视频或图片的直链不一定需要爬取,在网页加载的js文件里面说不定就能找到。既然能直接找到,我们何必爬呢?然后下载的时候一定要采用多线程,因为多线程可以占满宽带实现满速下载。
引用参考
https://blog.csdn.net/qq_42951560/article/details/108785802