爬取后保存的图片效果图
步骤入下(三步):
-
- 先去要爬取的目标网站(https://pixabay.com/)去注册一个账号。
- 2.注册后登录,浏览器右键鼠标,打开检查,找到登录后的cookies值。
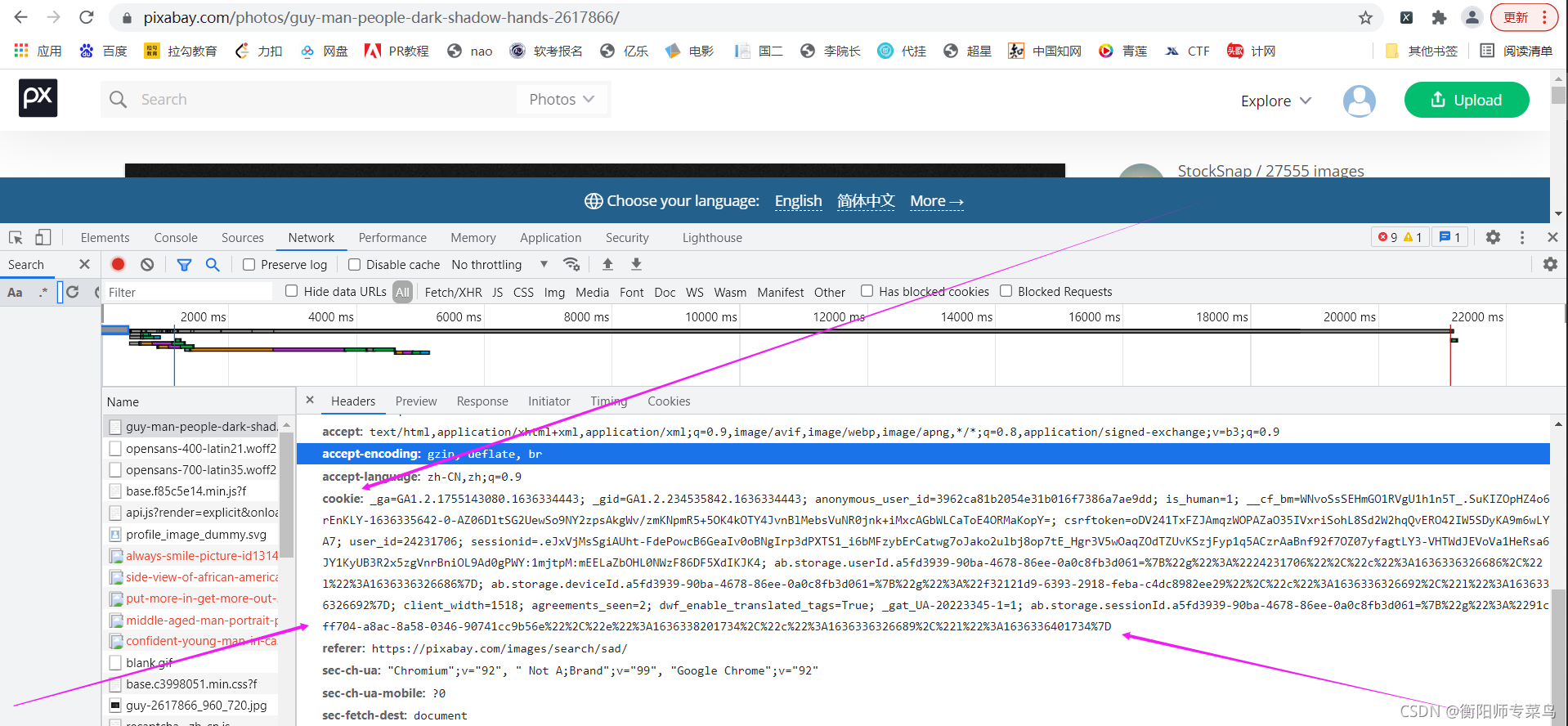
- 3.运行源代码(源代码在文末给出)
输入登录后的cookies值,以及要开始爬取的页面数。回车即可。
(文件爬取的下载路径可以自行在源代码中修改)

源代码
import httpx
from bs4 import BeautifulSoup
import os
import zipfile
import time
import randomcookies = str(input("请输入登陆后的cookie值:")).replace('\n', '').replace('\t', '')
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','accept-language': 'zh-CN,zh;q=0.9','cookie': cookies,'referer': 'https://pixabay.com/photos/search/?pagi=2&','sec-ch-ua': '"Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}def getimgindex(page):url = f"https://pixabay.com/zh/photos/search/?pagi={page}&"client = httpx.Client(http2=True,verify=False)res = client.get(url,headers=headers,timeout=20)html = BeautifulSoup(res.content,'lxml')imgurl = html.find_all('div',class_="row-masonry-cell-inner")for img in imgurl:photo = img.find_all('img')[0]title = photo['alt']if 'Sponsored image' not in title:try:data_lazy = photo['data-lazy']except:data_lazy = photo['src']data_lazy = str(data_lazy).split('/')[-1].split('_')[0]downloadUrl = f'https://pixabay.com/zh/images/download/container-ship-{data_lazy}.jpg?attachment'filename = data_lazy.split('-')[-1]downloadpath = f"data/{filename}" createFile(downloadpath) taginfo = str(title).replace(', ',"_")downloadfilename = f"data/{filename}/{filename}_{taginfo}" download(downloadUrl, downloadfilename)def download(url,filename):client = httpx.Client(http2=True, verify=False)res = client.get(url, headers=headers, timeout=20)with open(f'{filename}.jpg', 'wb') as f:f.write(res.content)f.close()print(f'{filename} Download successful!')def zipDir(dirpath,outFullName):"""压缩指定文件夹:param dirpath: 目标文件夹路径:param outFullName: 压缩文件保存路径+xxxx.zip:return: 无"""zip = zipfile.ZipFile(outFullName,"w",zipfile.ZIP_DEFLATED)for path,dirnames,filenames in os.walk(dirpath):fpath = path.replace(dirpath,'')for filename in filenames:zip.write(os.path.join(path,filename),os.path.join(fpath,filename))zip.close()def createFile(filename):"""创建文件夹"""while True:filepath = f"{filename}"if os.path.isdir(filepath):breakelse:os.makedirs(filepath)
def wirteTxt(filename,content):"""写入数据"""with open(f'{filename}', 'a+', encoding='utf-8') as f:f.write(str(content) + '\n')f.close()print(f'{content} 正在写入')def runs():while True:try:p = int(input("请输入开始页码:"))except:passelse:n = 0for x in range(p,12221):n += 1if n % 15 == 0:randomTime = random.randint(10, 30)print(f"休息{randomTime}秒后继续爬取!")time.sleep(randomTime)randomTime = random.randint(1,5)print(f"{randomTime}秒后开始爬取")time.sleep(randomTime)nowtime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())text = f"{nowtime} ———————— 第{x}页"wirteTxt('loging.txt',text)getimgindex(x)breakif __name__ == '__main__':runs()
结束语





![大型网站系统架构分析[转]](https://images.cnblogs.com/cnblogs_com/Mainz/WindowsLiveWriter/7d1bb181b447_CD48/%E5%A4%A7%E5%9E%8B%E7%BD%91%E7%AB%99%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84_thumb.png)