前言:
通过第一阶段的学习,接下来简单的抓取一下网站更新的内容并且以邮件的方式提醒
代码:
一、简单抓取网站以邮件进行通知:
原理:
1、将需要使用的包导入
2、编写邮件发送模板,
3、分析需要抓取的网站
4、借助文件读写操作将对比抓取到的第一条与文件中存在的一条去比较
5、如果有则更新,则发送邮件
实现代码:
邮件模板:
import smtplib
from email.mime.text import MIMEText
from email.header import Headerdef email(csdn_article_title,csdn_article_url):sender = ' '#填写发件人pwd = ' '#登录密码,是邮件第三方登录的那个密码receivers = [' ']#填写收件人mainText="网站有内容更新,更新题目为:"+csdn_article_title+"更新网址为:"+csdn_article_urlmessage = MIMEText(mainText,"plain",'utf-8')# 三个参数:第一个为文本内容,第二个为plain设置文本格式,第三个为utf-8设置编码message ['From'] = "XXX <XX@qq.com>"message ['To'] = "XXX <XX@126.com>"subject = "CSDN网站有内容更新"#邮件主题message["Subject"] = subjecttry:# 使用非本地服务器,需要建立ssl连接smtpObj = smtplib.SMTP_SSL("smtp.qq.com",465)#发件箱邮件服务器smtpObj.login(sender,pwd)smtpObj.sendmail(sender,receivers,message.as_string())print("邮件发送成功")except smtplib.SMTPException as e:print("Error:无法发送邮件.Case:%s"%e)邮件测试模板:
#!/usr/bin/python
# -*- coding: UTF-8 -*-import smtplib
from email.mime.text import MIMEText
from email.utils import formataddrmy_sender = '@qq.com' # 发件人邮箱账号
my_pass = 'as' # 发件人邮箱密码
my_user = 'a@qq.com' # 收件人邮箱账号,我这边发送给自己def mail():ret = Truetry:msg = MIMEText('填写邮件内容', 'plain', 'utf-8')msg['From'] = formataddr(["FromRunoob", my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号msg['To'] = formataddr(["FK", my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号msg['Subject'] = "菜鸟教程发送邮件测试" # 邮件的主题,也可以说是标题server = smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是25server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码server.sendmail(my_sender, [my_user, ], msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件server.quit() # 关闭连接except Exception: # 如果 try 中的语句没有执行,则会执行下面的 ret=Falseret = Falsereturn retret = mail()
if ret:print("邮件发送成功")
else:print("邮件发送失败")抓取分析模板:
import requests
from lxml import etree
import time
import os
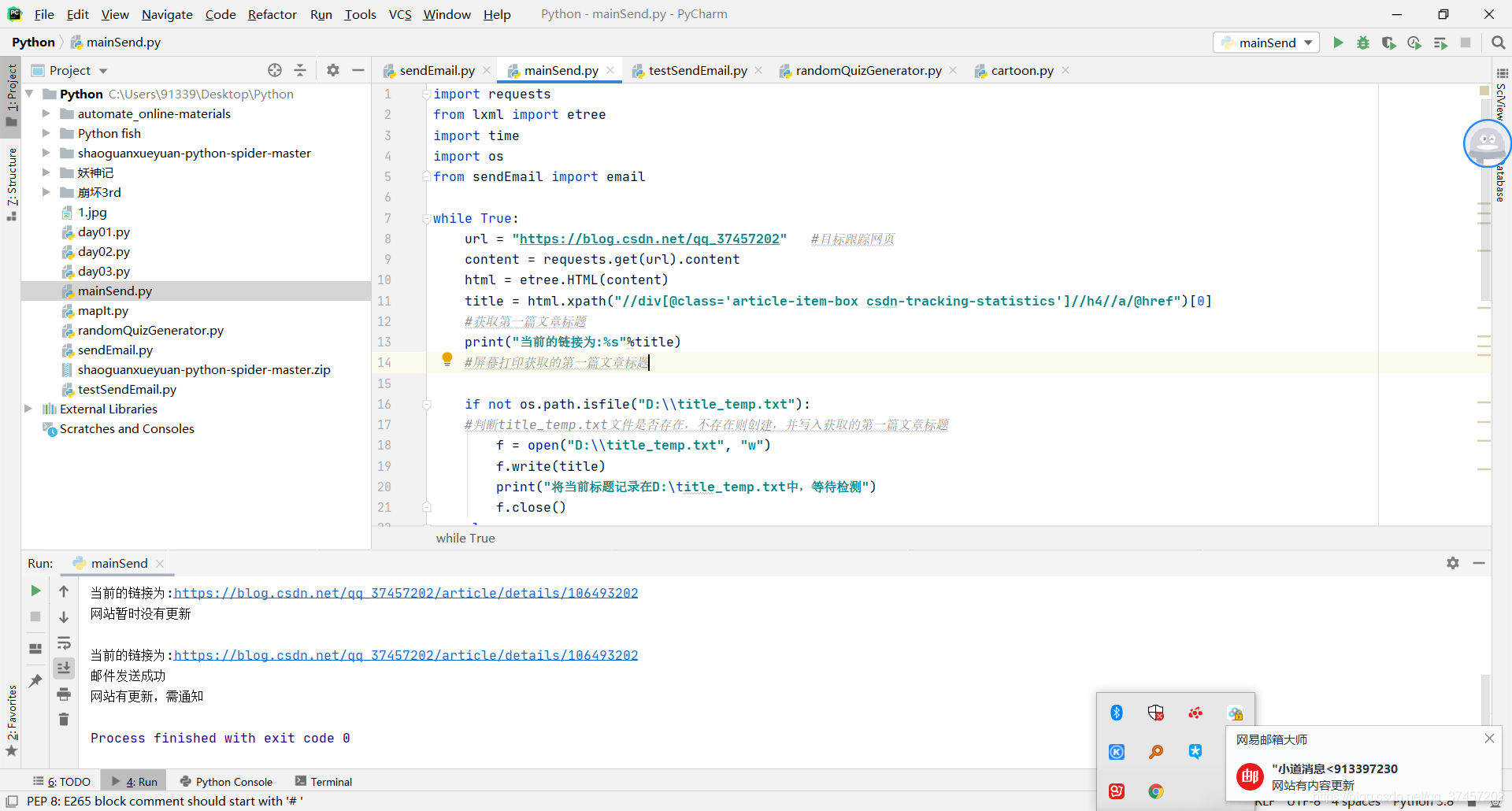
from sendEmail import emailwhile True:# 博主名字author_name = input("请输入博主的名字: ")# 博主博文页数page_num = int(input("请输入博客页数: "))url = "https://blog.csdn.net/"+author_name+"/article/list/"+str(page_num) #目标跟踪网页content = requests.get(url).contenthtml = etree.HTML(content)# 博客文章的标题# 博客文章的标题title = html.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/text()") #取0为空 暂时不清粗为什么csdn_article_url = html.xpath("//div[@class='article-item-box csdn-tracking-statistics']//h4//a/@href")[0]# 处理换行问题csdn_article_title = []for i in range(0, len(title)):csdn_article_title.append(title[i].strip())while "" in csdn_article_title:csdn_article_title.remove("")#获取第一篇文章标题print("当前的标题为:%s"%csdn_article_title[0]) #取第一个print("当前的链接为:%s" %csdn_article_url)#屏幕打印获取的第一篇文章标题#文件打印 转换为字符换类型csdn_article_title[0]=str(csdn_article_title[0])csdn_article_url=str(csdn_article_url)if not os.path.isfile("D:\\title_temp.txt"):#判断title_temp.txt文件是否存在,不存在则创建,并写入获取的第一篇文章标题f = open("D:\\title_temp.txt", "w")f.write(csdn_article_title[0])f.write(csdn_article_url)print("将当前标题、url记录在D:\title_temp.txt中,等待检测")f.close()else:#title_temp.txt文件存在的话,提取里面标题,和获取的标题对比with open("D:\\title_temp.txt", "r+") as f:old_url = f.read()if old_url !=csdn_article_url:#如果读取内容和获取的网站第一篇文章标题不一致,则表明网站更新#email(csdn_article_title[0],csdn_article_url)#发送qq邮件f.seek(0)f.truncate()print("网站有更新,需通知")f.write(csdn_article_title[0])f.write(csdn_article_url)#写入最新的标题内容,方便下一次比对break#退出循环else:#否则的话,表明网站没有更新print("网站暂时没有更新\n")time.sleep(5)#检测网页内容时间间隔,单位为秒(s)结果:

二、抓取存到EXCEL进行分析:
原理:
1、将需要使用的包导入
2、编写EXCEL存储模板,
3、分析需要抓取的网站
4、存入excel
Notes:
查了很多资料!!! 评论和阅读自从改成图片 类属性都是read-num后 一直抓不到阅读数和评论数
实现代码:
import requests
import xlrd
import xlwt
from lxml import etree
from lxml import html
from xlutils.copy import copy# 爬虫实战: 爬取CSDN博客的所有博客文章链接# 第1页: https://blog.csdn.net/cnds123321/article/list/1
# 第2页: https://blog.csdn.net/cnds123321/article/list/2
# 第3页: https://blog.csdn.net/cnds123321/article/list/3
# 故可以得出公式: url="https://blog.csdn.net/"+author_name+"/article/list/"+page_index
# author_name指的是博主的名字,page_index指的是页码当前是第几页# path指的是excel文件的路径;sheet_name指的是工作簿的名字;value指的是数据,是一个嵌套列表
def write_excel_xls(path, sheet_name, value):"""创建excel文件,并初始化一定的数据"""index = len(value) # 获取需要写入数据的行数workbook = xlwt.Workbook() # 新建一个工作簿sheet = workbook.add_sheet(sheet_name) # 在工作簿中新建一个表格for i in range(0, index):for j in range(0, len(value[i])):sheet.write(i, j, value[i][j]) # 像表格中写入数据(对应的行和列)workbook.save(path) # 保存工作簿# path指的是excel文件的路径;value指的是数据,是一个嵌套列表
def write_excel_xls_append(path, value):"""向excel表中增加数据"""index = len(value) # 获取需要写入数据的行数workbook = xlrd.open_workbook(path) # 打开工作簿sheets = workbook.sheet_names() # 获取工作簿中的所有表格worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格rows_old = worksheet.nrows # 获取表格中已存在的数据的行数new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格for i in range(0, index):for j in range(0, len(value[i])):new_worksheet.write(i + rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入new_workbook.save(path) # 保存工作簿# 请求头# 博主名字
author_name = input("请输入博主的名字: ")
# 博主博文页数
page_num = int(input("请输入博客页数: "))
# 写入表头数据
write_excel_xls("CSDN-" + author_name + ".xls", author_name, [["文章类型", "文章标题", "文章链接", "发表日期", "阅读数", "评论数"], ])
# 循环每页
for index in range(1, page_num + 1):# 拼接URL !!!不能有空格page_url = "https://blog.csdn.net/"+author_name+"/article/list/"+str(page_num)# 发送请求,获取响应content = requests.get(page_url).contentpage_html = etree.HTML(content)# 博客文章的标题title_list = page_html.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/text()")# 处理换行问题csdn_article_title_list = []for i in range(0, len(title_list)):csdn_article_title_list.append(title_list[i].strip())while "" in csdn_article_title_list:csdn_article_title_list.remove("")# 博客文章的类型csdn_article_type_list = page_html.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/span")# 博客文章的链接csdn_article_link_list = page_html.xpath("//div[@class='article-item-box csdn-tracking-statistics']//h4//a/@href")# 博客文章的发表日期csdn_article_publishDate_list = page_html.xpath("//div[@class='info-box d-flex align-content-center']/p/span[@class='date']")# 博客文章的阅读数csdn_article_readerCount_list = page_html.xpath("//div[@class='info-box d-flex align-content-center']/p/span[@class='read-num'][1]")# 博客文章的评论数csdn_article_commentCount_list = page_html.xpath("//div[@class='info-box d-flex align-content-center']/p/span[@class='read-num'][2]")for i in range(0, len(csdn_article_title_list)):print(csdn_article_type_list[i].text, csdn_article_title_list[i],csdn_article_publishDate_list[i].text,csdn_article_readerCount_list[i].text)# 将数据保存到excel表格中for i in range(0, len(csdn_article_title_list)):data = [[csdn_article_type_list[i].text, csdn_article_title_list[i], csdn_article_link_list[i],csdn_article_publishDate_list[i].text, csdn_article_readerCount_list[i].text,csdn_article_commentCount_list[i].text], ]print("正在保存: " + csdn_article_title_list[i] + "......")write_excel_xls_append("CSDN-" + author_name + ".xls", data)
print("CSDN-" + author_name + ".xls保存成功!")








![[转]一个普通网站发展成大型网站过程中的架构演变史](https://images.cnblogs.com/cnblogs_com/tudoux/29.png)