无聊的练习。。。貌似网站真的有毒,我的电脑多了一个广告。。。fuck
换做好几年前我们看电子书都是在网上下载txt文件的书籍,现在各种APP阅读软件实在方便太多。
那么txt的文件就没用了吗?不呀,可以下载放kindle阅读呀!
部分网站不提供整本书籍下载,想想也是麻烦哎!既然不提供,那么,自己动手,风衣足食呀!
目标网站:http://www.136book.com/
首先 需要的库文件
import re
import os
import requests
import time
import threading
from multiprocessing import Pool
from requests import RequestException
from urllib import request
from bs4 import BeautifulSoup根据网页链接获取整个网页代码
通过此方法获取整个网页内容,这样我们才可以做下面的页面解析
#获取页面内容
def get_page(url):user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'myheader = {'User-Agent':user_agent}try:response = requests.get(url,headers=myheader)if response.status_code == 200:return response.textreturn Noneexcept RequestException:print( '出错',url)return None分析网页获取所有章节链接
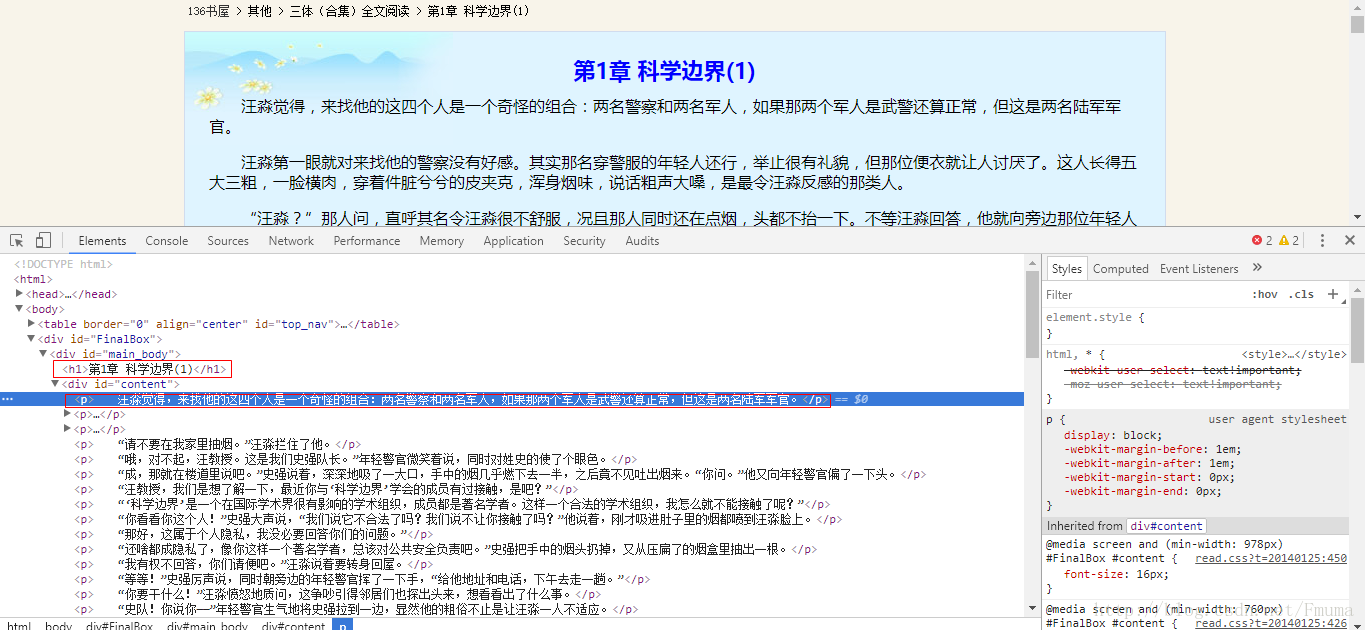
打开网址http://www.136book.com/santiheji 用chrome浏览器右键检查查看信息
可以发现所有章节都在div id=”box1” class=”book_detail” 一共有两个这样的div标签,而我们所需要的信息是需要第二个,因为第二个包含了第一个的所有内容
代码如下
#解析页面 获取所有链接
def get_all_link(html):#用来保存所有的章节链接link_title = []soup = BeautifulSoup(html,'lxml')#获取所有章节 不要最新章节的内容all_chapter = soup.find_all('div',attrs={'class':'box1'})#在以all_chapter为内容提取所有a标签soup_all_chapter = BeautifulSoup(str(all_chapter[1]),'lxml')# print( soup_all_chapter )#获取所有的li标签all_li = soup_all_chapter.find_all('ol',attrs={'class':'clearfix'})#在获取所有a标签soup_a = BeautifulSoup(str(all_li),'lxml')all_a = soup_a.find_all('a')for a in all_a:link_title.append( a.get('href') )# print( ( a.get('href'),a.text ) )# print( link_title )return link_title分析网页获取文本内容
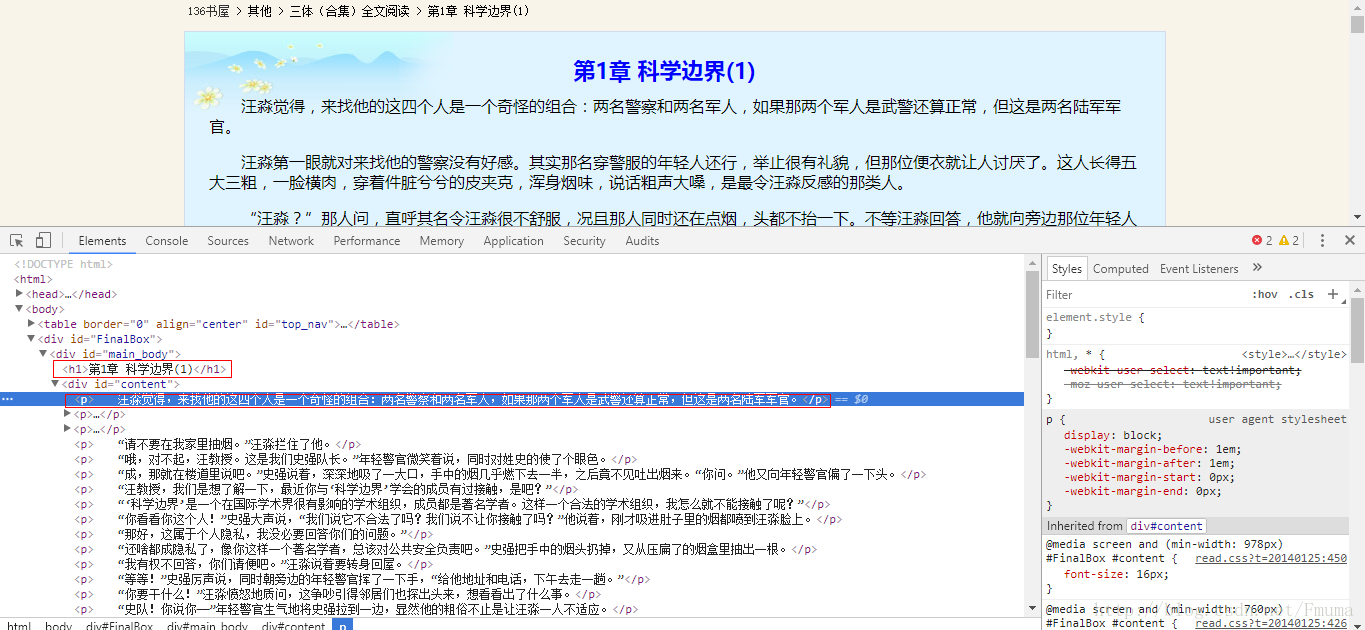
首先顺便打开一本书,比如《三体》 用chrome浏览器右键检查查看信息
可以看出章节标题在 h1第1章 科学边界(1) p标签里面就是每章节的内容只要取出div id=”content”中所有的p标签里面的内容即可!
代码如下
#解析页面提取所有TXT文本 并写入文件
def get_txt_content_and_write_file(url):#获取网页文本内容html = get_page(url)# print( html )#提取文本内容soup = BeautifulSoup(html,'lxml')#获取每章节标题soup_title = soup.find('h1')# print( soup_title.text )#获取所有trsoup_tr = soup.find('tr')soup_a = BeautifulSoup(str(soup_tr),'lxml')#获取书籍名称book_name = soup_a.find_all('a')[2].text[:-4]#将标题写入文件write_file( str(soup_title.text)+'\n',book_name ) #写入数据并换行# 找出div中的内容soup_text = soup.find('div', id='content')# 输出其中的文本soup_p = BeautifulSoup(str(soup_text),'lxml')for x in (soup_p.find_all('p')):#去掉 p 标签x = str(x).replace('<p>','').replace('</p>','')#写入TXT文件write_file( x,book_name )# print( x )获取整本书籍名称
这样后面写入文件就可以根据书籍名来创建文件夹了
#解析页面获取整本书籍名称
def get_title(html):soup = BeautifulSoup(html,'lxml')title = soup.find('h1')return title.text写入txt文件
获取了网页上所有我们所需的内容,接下来就是写入文件
def write_file(content,book_name):file_path = 'D:\{}/{}.txt'.format(book_name,book_name)#首先创建文件夹file_directories = 'D:\{}'.format(book_name)if not os.path.exists(file_directories):os.mkdir(file_directories)#写入文件with open(file_path,'a') as f:f.flush()f.write(content+'\n') #写入数据并换行f.close()主函数运行函数执行操作
if __name__ == '__main__':url = 'http://www.136book.com/santiheji' #程序计时start_time = time.time()html = get_page(url)#获取书籍名称title = get_title(html )#获取所有章节链接link_title = get_all_link(html) #返回的数据是一个列表 列表内容为所有章节链接t = 0for lt in link_title:t = t+1print( lt,'已经完成',t/len(link_title)*100,'%' )#根据每个链接去拿取数据并写入文件get_txt_content_and_write_file( lt )#结束时间end_time = time.time()print( '耗时:',end_time-start_time )一两分钟就搞定了一本电子书,是不是很过瘾?想想如果是手动ctrl+c ctrl+v估计会想死吧…
提示,换一本书的链接也可以下载哦,哈哈哈 不放过此网站上的任何一本书籍!