在线教育网站学习,是很多人利于闲余时间进行充电的一种选择。本篇文章利用python抓取在线教育网站课工场课程页面的数据,进行简要分析。
通过使用requests库对课工场课程列表页进行抓取。
通过BeautifulSoup对课工场课程列表页面进行解析,并从中获课程名称,课程类型,付费类型,课程学习人次的数据。
最后再利用python的pandas,matplotlib,seaborn模块对数据进行处理和分析。
0,工作环境搭建
环境:win10+Anaconda +jupyter Notebook
模块:
爬虫和网页解析相关的模块:requests,BeautifulSoup,time
数据分析模块:Numpy,pandas
画图模块:matplotlib,seaborn
1,构建爬虫,抓取需要的信息
构造爬虫是需要注意
- 开始抓取前先观察下目标页面或网站的结构,其中比较重要的是URL的结构
- 在抓取网页时,为了尽量伪装成正常的请求,我们需要在http请求中设置一个头部信息,否则很容易被封。头部信息网上有很多现成的。并手动设置每次请求的时间间隔。
A,构造爬虫
import requests,time
from bs4 import BeautifulSoupurl = 'http://www.kgc.cn/list/230-'+str(i)+'-6-9-9-0.shtml'
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Referer':'http://www.baidu.com/link?url=_andhfsjjjKRgEWkj7i9cFmYYGsisrnm2A-TN3XZDQXxvGsM9k9ZZSnikW2Yds4s&wd=&eqid=c3435a7d00006bd600000003582bfd1f'
}for i in range(1,64):if i==1:url = 'http://www.kgc.cn/list/230-'+str(i)+'-6-9-9-0.shtml'r = requests.get(url=url,headers=headers)html = r.textelse:url = 'http://www.kgc.cn/list/230-'+str(i)+'-6-9-9-0.shtml'r = requests.get(url=url,headers=headers)html2 = r.texthtml = html + html2time.sleep(0.8)B,解析页面,提取信息
kgc = BeautifulSoup(html,"html.parser")# 提取课程名称
name= kgc.find_all("a",attrs={"class":"yui3-u course-title-a"})c_name = []
for n in name:course_name = n.string.split()[0]c_name.append(course_name)#提取课程参加人数
number = kgc.find_all("span",attrs={"class":"course-pepo"})p_number=[]
for p in number:people_number = p.stringp_number.append(people_number)#提取付费信息
price = kgc.find_all(class_=['view0-price f16','view0-old f14'])p_type = []
for p in price:price_type = p.stringp_type.append(price_type)#提取课程类别
category = kgc.find_all(class_="yui3-u course-title-a")c_category = []for c in category:soup=BeautifulSoup(str(c),"html.parser")tag = soup.ahref = tag.attrs['href']c_category.append(href)C,写入pandas数据框中
import pandas as pdcourse = pd.DataFrame({"course_name":c_name,"student_number":p_number,"pay_type":p_type,"course_info":c_category})#检查下数据集构造的情况
course.head(10)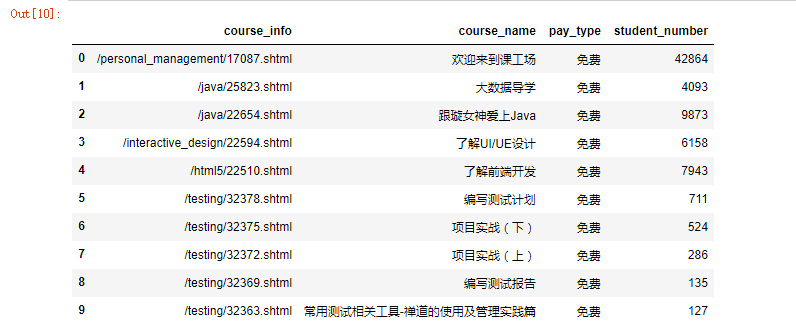
虽然我们已经把提取的信息构造为DataFarme结构的数据,但明显能看到,这个数据集有些粗糙。所以我们还需要,对数据集进行进一步的处理。
2,数据处理(特征构造)
数据处理的内容主要是对数据集进行数据清洗和加工。
数据处理的的目的是为了让数据集变得更利于下一步分析。
#从course_info字段中提取课程类别信息
course["category"] = course["course_info"].apply(lambda x:x.split("/")[1].strip())#从course_pay字段中提取付费信息
import re
def get_num(string):return (re.findall("d+.?d*",string))[0]
course["course_pay"] = course["pay_type"].apply(get_num).astype(float)#将“pay_type”字段中的“免费”替换为“0.00”
course.replace({'pay_type': {'免费': '¥0.00', }}, inplace=True)#数据类型转换
course['student_number'] = course['student_number'].astype(float)import matplotlib.pyplot as plt
plt.style.use("ggplot")
plt.rc('font',family='STXihei')
import missingno as msno
import seaborn as sns
sns.set()%matplotlib inline
%config InlineBackend.figure_format="retina"#缺失值检查
msno.matrix(course,figsize=(12,5))
3,数据分析(数据探索和可视化)
探索性数据分析(Exploratory Data Analysis,简称EDA)目的是最大化对数据的直觉,完成这个事情的方法只能是结合统计学的图形以各种形式展现出来。通常涉及以下几种方法的组合:
- 原始数据集中每个字段的单变量可视化和汇总统计
- 数据集中每个自变量与目标变量之间的关系的双变量可视化和汇总统计
- 多元可视化以了解数据中不同字段之间的交互作用
- 让观察值聚类成有区别的小组
这里对处理后的数据简要的探索性分析。
A.学习人次以及付费人次
作为在线教育产品,知道有多少人次在学习课程,有多少人次学习付费课程,有多少人次是学习免费课程,是必须要关注的数据。
course.student_number.sum()
#输出:11611136.0no_pay = course.loc[course["course_pay"] == 0].student_number.sum()
#输出:3519971.0paid = course.loc[course["course_pay"] != 0].student_number.sum()
#输出:8091165.0付费学习与免费学习两种类型占比
plt.rc('font', family='STXihei', size=20)
plt.figure(figsize= (12,8))#创建画布
plt.pie([no_pay, paid],labels=['No Pay','Paid'],autopct='%1.0f%%')
plt.title('Paid rate')
plt.axis("equal")
从数据中看出,该网站的课程,达到1100万学习人次,付费人次达到800多万,占比70%。
B,课程价格分布
course.course_pay.describe()#输出
count 1557.000000
mean 17.608863
std 17.697668
min 0.000000
25% 0.000000
50% 19.000000
75% 29.000000
max 299.000000
Name: course_pay, dtype: float64价格分布直方图
course.course_pay.hist(bins=20)
课程价格多集中在20—30元左右,付费课程的平均价格是17元人民币,按照800万的付费人次计算,目前为止,课程销售额不低于1.36亿人民币。
insight:
在千万级学习人次中,付费学习人次达到800多万,占比70%,课程销售额不低于1.36亿人民币。很厉害的转化。
作为北大青鸟旗下的在线教育平台,除了依托北大青鸟自身的流量扶持。应该还在有流量引入能力的垂直领域类容分发平台,进行卡位。
经过验证发现,课工场,在国内比较有知名度的在线课程内容分发平台如百度传课,网易云课堂,腾讯课堂都进行了内容分发和卡位。但在淘宝同学上,却没有找到课工场。
而且在知乎这个知识社区分享平台中搜“课工场”品牌名称时,却没有关于它的内容,不知道为什么课工场在各个在线课程内容分发平台都进行了卡位,却在知乎上没有行动。我觉得在这样的知识分享社区,无论是从社区氛围,还是从知乎社区用户的角度看,最有利的广告主就是做在线教育的,尤其是做IT培训在线教育的。
C,课程类型分布
plt.rc('font', family='STXihei', size=15)
plt.figure(figsize= (12,8))#创建画布
sns.countplot(y='category', data=course)
plt.title('Course_category Count' )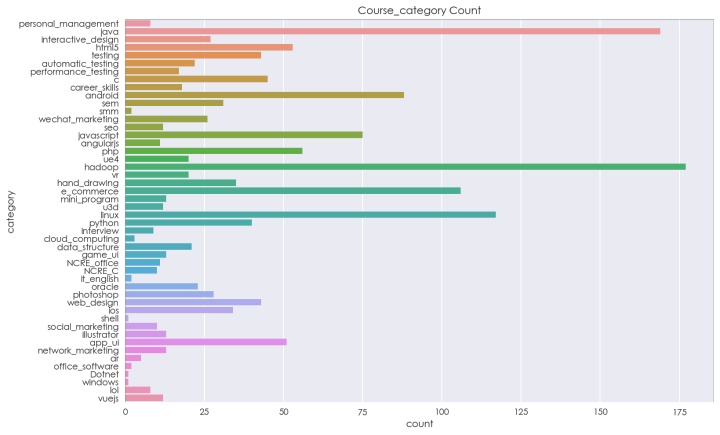
网站中课程类型,多是偏向于编程技术如Java,handoop,android,linux
再来看看,用户参喜欢学习的课程多是哪些类型?
D,用户参与学习课程类型分布
plt.rc('font', family='STXihei', size=15)
plt.figure(figsize= (12,8))#创建画布
sns.barplot(data=course,x="student_number",y="category",ci=None)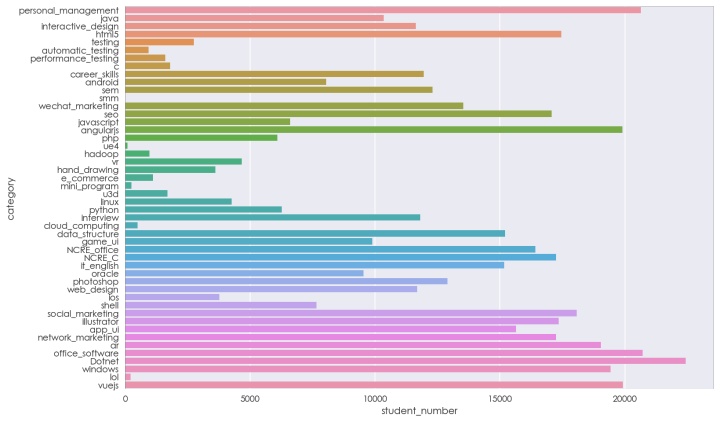
位于前三的是Dotnet,office_software,personal_management,除了编程技术之外,职场办公,个人管理的课程也是很受欢迎的。但网站中关于office_software,personal_management的课程太少。
insight:
上面的数据表现,说明网站用户中除了技术岗位的学习群体,还有不少是普通岗位(非技术向)的。在下一步的内容运营中,应该有意识的增加职场办公,个人管理这两个方向上的课程。
网站推广中增加对普通职场(非技术向)群体的覆盖。如果是选择某类型的单品课程,针对这类群体推广,应该把选择方向上锚定在这两个方向上职场办公,个人管理类型的课程。
E,课程价格种类分布
course.course_pay.value_counts().plot(kind="bar",figsize=(12,8))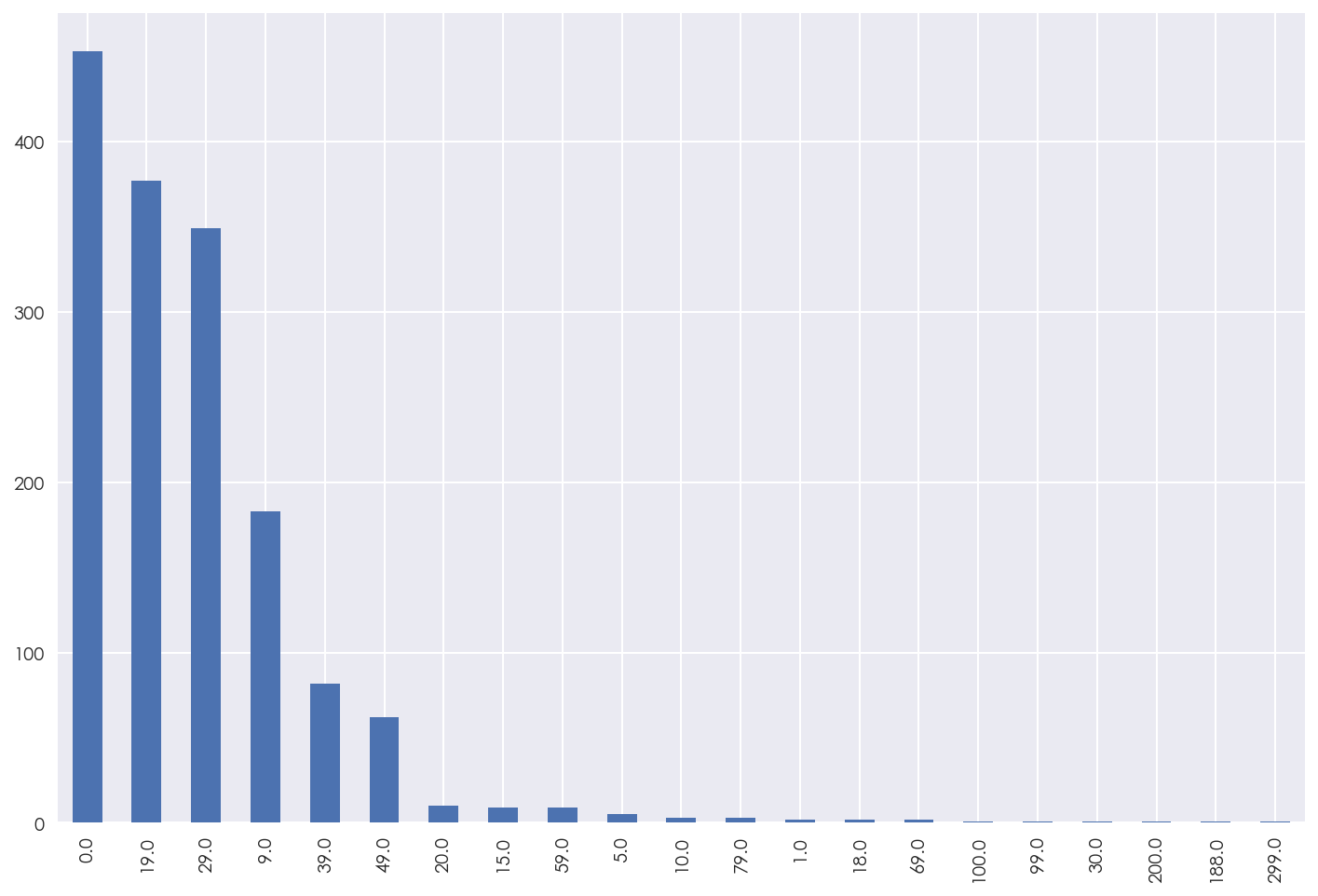
可以看到,付费课程的价格主要集中在9,19,29 ,这三个类别。
insight:
在上一步的分析中,可以看到,在参与学习人数最多的课程中,有两类课程:职场办公,个人管理
根这两个方向的课程学习人数,我们也或可推断,网站用户,多集中在职场白领群体,这部分群体是有较高的付费能力和购买能力的。
对于职场白领群体,课程的价格多不超过30元,是太过偏低的,还有可提升的空间。
当然,因为课程定价跟课程质量,数量,和学习时间周期都是相关的,所以定价也需要考虑这些因素。因为所得数据有限,这样的思考是基于这份数据而进行的假设,实际情况仍需要去通过更多的数据信息进行交叉验证。
再来看看在付费课程类型中,购买人数最多的课程是哪些。
F,付费课程类型中,平均购买人数最多的课程
course.loc[course["course_pay"] != 0]/
.groupby(["category","course_pay"])[["student_number"]].mean()/
.sort_values(by="student_number",ascending=False)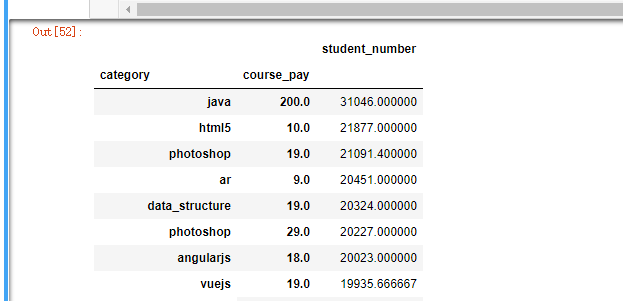
可以看到,平均购买人数最多的课程多是偏于编程技术的,其中java 位居首位,其次是H5,
然后是AR。
在平均购买人数最多的课程中,属于前端开发的课程占据了3门:angularjs,vuejs,html5,这也说明web开发,的确很火热。
但却没有看到,这两年火热程度,一直以火箭速度蹿升的python的身影。
G,免费课程中,平均参与学习人数最多的课程
course.loc[course["course_pay"] == 0]./
groupby(["category","course_pay"])[["student_number"]].mean()./
sort_values(by="student_number",ascending=False)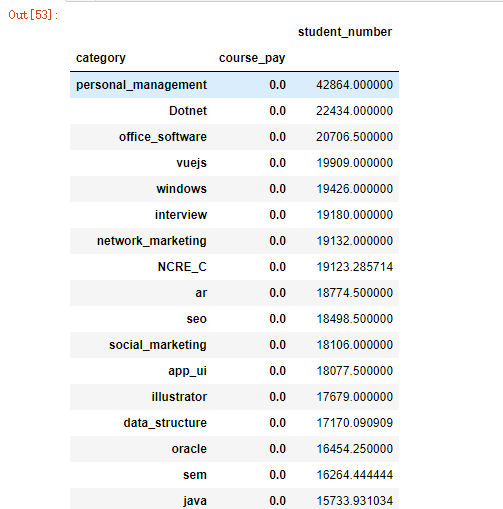
在免费课程中,参与学习人数最多的是个人管理的课程,排名前3的课程中,有2门课程是关于职场办公通用技能提升的课程:个人管理,office办公软件。
insight:
在后续的付费课程中,可以针对个人管理,office办公软件的方向上,出一些收费精品课程,
尝试对非编程技术学习群体进行商业付费的转化。
总结:
与应用相结合,让数据产生商业价值,永远是数据生命的所在,也是数据驱动业务优化的价值所在。