我们在上一篇文章 跟我一起读源码 – 如何阅读开源代码 中详细讲解了
- 阅读开源代码的重要性
- 如何选取适合自己的Python开源库
- 如何搭建自己的代码阅读环境
- 阅读代码的方法和原则
在本篇文章,就请大家跟我一起将这些方法运用起来,读完一个完整的开源项目的代码。
1. 项目选择
我们本篇文章面向的是还没有太多代码阅读经验的人群,因此我们选取了一个高质量的小型Python库,它的名字叫Tablib,我们在 跟我一起读源码 – 如何阅读开源代码 中的最后也推荐过这个项目,这是一个处理表格数据的Python库,它支持的格式非常的多,包括csv,excel,json,yaml,html等等,它非常的轻量级,如果你只是做一些表格操作,而不是要做大量的数据科学数据分析工作,那么就不用动用Pandas这样的大杀器了。另外提一下,这是大神Kenneth Reitz的作品,用Python的人估计很少有人不知道Kenneth Reitz的大名吧,他的 https://github.com/psf/requests 库一度是GitHub最受欢迎的库,Kenneth Reitz出品必属精品,Tablib的代码非常的精炼,模块化也很好,运用了很多Python的基础特性,而又不炫技,非常值得一读。
- Tablib的仓库链接:https://github.com/jazzband/tablib
- Tablib的文档链接:https://tablib.readthedocs.io/en/stable/
在 跟我一起读源码 – 如何阅读开源代码 中我们有提过,阅读代码有时候从早期版本读起来会更容易一些,因为早期版本实现的是核心功能,代码量相对来说较小。但是在阅读Tablib库的时候,我们没有必要这么做,因为代码已经很简单,代码量已经很小了,我们直接下载最新的版本,大家可以从GitHub仓库上边直接使用download按钮下载,或者用Git工具克隆下来,我们之前提到过,在阅读的同时,我们可以将笔记记录到源码中,甚至我们可能会对源码进行修改来验证我们的理解,所以我们强烈建议大家在GitHub上将代码Fork到自己的工作空间,然后克隆下来。笔者就是采取了这种方式,而我阅读代码的笔记也已经提交到Fork出来的仓库中(阅读比较全部是中文),我的代码笔记仓库链接已经放在本篇文章的最后,大家有需要可以参考,希望能够帮到更多的人,觉得有帮助的帮忙加一个星标哦,谢谢啦。
在这篇文章中,我们不会细到对代码进行逐行或者逐函数方法的解释,大家可以在我们的阅读笔记中找到这些解释,可以在我们的Fork仓库代码中搜索 http://pythonlibrary.net就可以找到那些笔记了,而在本文中,我们将更多的侧重于如何把 跟我一起读源码 – 如何阅读开源代码中提到的方法运用起来,并结合代码中的多个难点进行解释,做到授人予渔,而非授人予鱼。
2. 阅读环境
这里的阅读环境包括阅读的工具,和Tablib源码结构的分析。我们将使用Visual Studio Code + MS Python插件 + Kite +Git-Fork + Beyond Compare这样的工具链组合,我们的侧重点是源码阅读,因此这里就不讲解如何安装和配置这些工具了,而Tablib库比较简单,这些工具也并不是都有用到。
拿到源码之后的第一件事情就是观察它的文件夹结构,因为Python的模块在文件层面的表现就是文件夹和文件夹里边的py文件,所以对项目的文件夹结构有一个认知以后,对于我们对代码的理解会有很大的帮助。另外在理解了模块结构以后,我们就可以建立一个测试源码文件,里边可以放我们的测试代码(一般可以用官方文档提供的教程中的示例代码),尝试把库运行起来,如果后边的阅读中遇到了问题,我们就可以通过运行代码的方式来帮助我们理解。
Tablib的文件夹结构是下边这样的:
- 根目录下的文件可以暂时不用管,主要包括一些说明文件,用于分发库的setup文件,以及GitHub上边做自动化测试的配置文件
- docs文件夹:存放了官方文档,可以不用理会,因为我们主要通过阅读官方文档网站上的文档就行,跟这里是一样的
- tests文件夹:存放了测试用例,像Tablib官方组织Jazzband提到的,Tablib是一个非常受欢迎而且稳定的项目,有许许多多的生产项目在使用这个库,因此,库的质量是至关重要的,测试用例就是保证库的质量,读者在未来阅读其他的开源项目的时候也一定会遇到类似于这样名字的文件夹。对于Tablib项目的阅读,去研究测试用例不是必须的,因为它够简单,但是我们还是强烈建议有时间的读者去阅读下测试用例,这不仅对理解库有帮助,对你未来写高质量代码的时候也是很有帮助的
- src文件夹:存放了Tablib的实现,是我们主要阅读的文件夹。更进一步,在src文件夹下有一个tablib的文件夹,其实所有的源代码都在tablib这个文件夹里边,我们关注的文件都在这里边。

刚我们讲了,我们推荐大家建立一个测试文件,用于写一些调用代码,帮助大家调试,如上图根目录所示,我们在其中建立了main.py文件,我们将使用这个文件运行我们对Tablib的调用,辅助阅读,因此在main.py中要导入Tablib库,跟使用库不一样,我们不希望通过pip安装的方式达到可以调用的目的,我们希望直接导入src文件夹下的库,因此,在main.py可以import tablib之前还有一个简单的工作要做,我们把src路径加入到系统路径下,因为Python在加载模块的时候其实是优先从系统路径中寻找的,这样我们目的就达到了。然后紧接着我们使用import导入tablib,再然后通过打印tablib.__version__的方式确认库是否导入成功。通过运行main.py,我们能够看到tablib的版本号可以正常被打印,意味着库已经可以导入了,我们的环境也就搭好了。
import 最后,参考 https://tablib.readthedocs.io/en/stable/ 上边的代码示例,我们增加一些代码进main.py,大家可以一步一步跟着官方示例,去熟悉一下这个库的简单实用,和提供的接口涨什么样子,最后,在阅读代码的过程中大家根据自己在阅读代码过程中遇到的不同问题,调整里边的内容,达到通过调试理解代码的目的。
3. 阅读代码
在本节内容中,我们将结合之前提到的阅读方法,对于Tablib中的重点代码进行一个说明。
3.1 理清依赖关系
理清代码中模块(内部和外部)的依赖关系是很重要的,对于简单项目我们可能最开始就能够通过文件夹结构,文件命名以及import语句理清楚,对于复杂项目可能要随着阅读的不断深入去调整我们的理解,因此,这是一个迭代循环的过程,理清关系能够帮助我们理解代码,深入理解代码又能够帮助我们修正之前对模块依赖的认知。
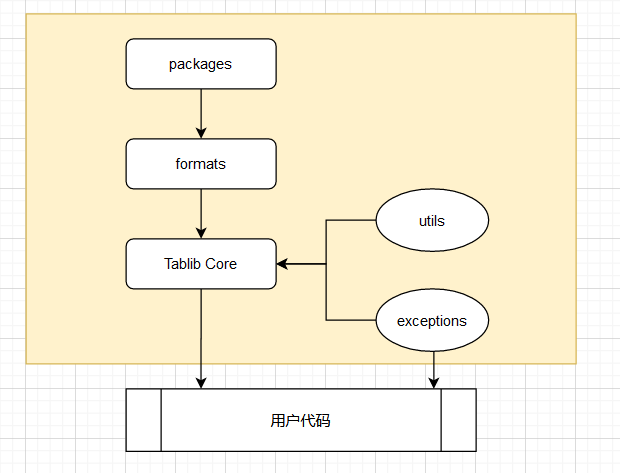
Tablib中模块的关系如下图,tablib core(也就是源代码中的core.py)提供了所有Tablib实现的核心代码,而对于不同格式的文件的支持都依赖于formats模块,formats模块通过对外部模块的调用(excel处理,pandas dataframe处理,HTML表格处理等等)实现对于不同表格格式的支持,而有的格式目前并没有其他外部库来做支持的,Tablib将会在packages中实现对它的支持(例如dbf)。而utils提供了一些常用的工具函数帮助core实现其功能,exceptions将Tablib自定义的异常集中在一起,这些异常一般会在core中抛出,而用户代码也可以导入exceptions在捕获相应的异常,从而实现更健壮的用户代码。
3.2 理清数据结构
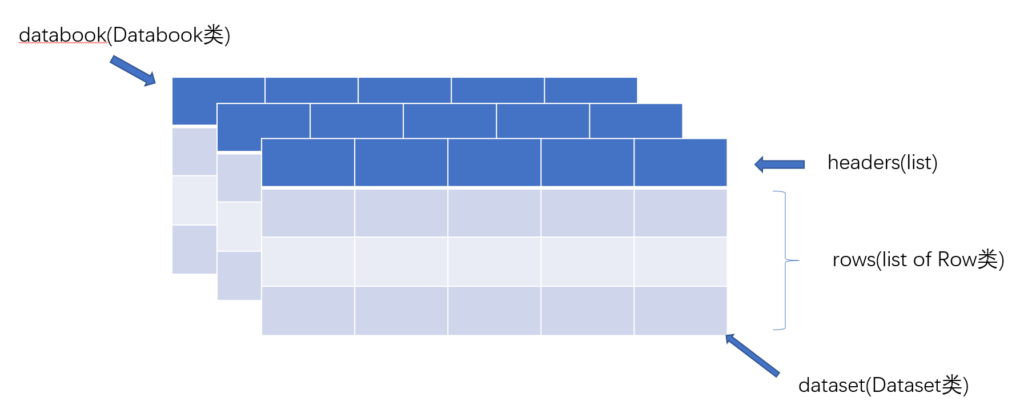
Tablib实现的是对表格数据的处理,因此其最重要的数据结构设计就是针对表格数据,表格数据结构都在core.py中(通过Row,Dataset和Databook三个类实现),理清数据结构也就是理清楚这三个类的成员变量。Tablib对表格的实现跟Excel中的表格概念是一致的,一个Databook可以类比成一个Excel文件,里边可以包含多个Dataset(可以类比于Excel中的sheet,代码中是self._datasets),而每一个Dataset中有可能会有表头headers(可选)是通过Python 的List存储的(代码中是self.__headers),每一个Dataset中会有很多行的数据(代码中是self._data),每一行都是一个Row的实例,而每一行中的元素则在Row的成员变量中用一个List来存储(代码中是self._row),该List中的每一个元素对应于一个单元里边的值。
3.3 重点代码
注:下边没有针对双下划线方法,以及setattr,import_module,find_spec这些高级的Python内置方法进行逐一解释,目的是防止将大家的注意力引入到太细节的Python知识,如果大家感觉需要了解这些方法到底是在做什么,我们的源码阅读笔记中进行了详细的讲解,因此这里强烈建议大家从 https://github.com/pythonlibrary/tablib-reading-notes 下载我们的源码阅读笔记。
Row类的实现:
Row的实现非常简单,主要就是通过self._row这一个成员变量来存储一行里边的所有元素,因此,它主要是实现了一些双下划线方法,用来支持通过Python的语法糖对Row中的单元格数据的存取,包括:
- __iter__方法让Row对象支持 for x in row这样的操作
- __len__方法支持通过len(row)来获取一行中的元素个数
- __getitem__,__setitem__和__delitem__方法来支持使用[]操作符来获取,修改和删除行中某一单元格的值
Row中还实现了append, insert, rpush, lpush等等这些方法,让我们对行有更多的操作选择。
Dataset类的实现:
Dataset类中的实现是整个Tablib的核心之一,另一个核心是formats的注册。按照我们其那边对数据结构的分析,一个Dataset其实是按行来存储表格数据的,因此对于按行的操作相对来说容易的很多,那么当用户代码需要按列来操作数据的时候就需要特殊处理。从功能上来说,Dataset类跟Row的相似点是,它也实现了很多双下划线方法,用来支持Python语法糖,让用户在使用这个库的时候更加方便,另外为了提供所有的针对Dataset的操作,还实现了表格的格式化,表格数据的验证(用于当有新数据存进来的时候,确保新数据的格式跟表格是匹配的),以及不同格式的数据的导入和导出(主要依赖于formats模块)
- __getitem__,__setitem__和__delitem__方法来支持通过[]来获取,修改和删除某一行或者某一列
- __str__方法来实现格式化打印,让用户在 使用print打印Dataset的的时候更美观(主要是处理了单元格数据长度不一带来的对其问题)
- _validate方法来对新增数据的格式校验
- _package方法来将Dataset转换为dict格式
- load和export方法来导入和导出csv, json, excel等格式的文件
此外Dataset也实现了append, insert, extend, pop, sort, filter等等方法,让我们对数据集的操作有更多的选择。
Databook类的实现:
多个Dataset组成一个Databook,Databook主要就是将多个Dataset集合起来,提供了访问每一个Dataset的接口。
格式处理器(formats)的支持:
Tablib中实现了一个格式注册表,用来支持和扩展不同的表格格式,核心代码在formats/__init__.py中,而formats文件夹下的其他代码为每一个个文件处理一种不同的格式的数据,他们类似于插件,如果想要支持更多的格式,只需要增加一个新的格式文件,在文件里实现定义好的接口,最后将新的格式处理类注册到注册表中就行。对于有些读者可能会觉得格式注册表类Registry的实现有点难懂,它其实是使用setattr动态的将formats的导入和导出加载到了Dataset和Databook类上边。由于不同的format处理器依赖于不同的第三方库,而且用户也不一定需要使用所有的格式处理器,因此Tablib聪明的使用了import_module方法,动态的加载第三方库,只有通过find_spec能够找到的库,也就是说被用户安装了依赖的格式处理器才会被加载进来。
这部分代码是这样写的,在register_builtins方法中,先通过find_spec查找某个模块是否被安装,比如用于处理xlsx格式的openpyxl,如果它被安装了就通过self.register将它放到注册表中:
if find_spec('openpyxl'):self.register('xlsx', 'tablib.formats._xlsx.XLSXFormat')注册的操作其实就是使用setattr来将两个描述器ImportExportSetDescriptor和ImportExportBookDescriptor动态绑定到Dataset和Databook
class Registry:_formats = OrderedDict()def register(self, key, format_or_path):from tablib.core import Databook, Dataset# Create Databook.<format> read or read/write properties# pythonlibrary.net:# 下边这些代码会直接修改到Dataset类和Databook类的类属性# 它们将会添加新的属性到这两个类,而新的属性就是前边的格式描述器# 描述器具有一个成员名为_format,描述器的setter和getter将会# 调用_format的import和exportsetattr(Databook, key, ImportExportBookDescriptor(key, format_or_path))# Create Dataset.<format> read or read/write properties,# and Dataset.get_<format>/set_<format> methods.setattr(Dataset, key, ImportExportSetDescriptor(key, format_or_path))try:setattr(Dataset, 'get_%s' % key, partialmethod(Dataset._get_in_format, key))setattr(Dataset, 'set_%s' % key, partialmethod(Dataset._set_in_format, key))except AttributeError:setattr(Dataset, 'get_%s' % key, partialmethod(Dataset._get_in_format, key))self._formats[key] = format_or_pat而库的动态导入则是在两个描述器中实现的,利用的就是import_module这个Python内置的方法。
3.3 带着问题阅读
最后这节,我们挑选了一段实现的特别巧妙地代码,让读者了解如何带着问题阅读代码。我们的main.py中有一段打印dataset的代码,它的输出是这样的:
这时候,我们就应该问自己,为什么这个库能够在每一个单元格中的元素长度未知的情况下,做到能够对其每一列的元素,然后带着这个问题去看代码。我们知道当用户使用print来打印dataset的时候,其实是调用的Dataset类的__str__方法,然后我们来看这个方法到底是怎么实现的,我们在代码只有一一解释了代码的实现思路。
def __str__(self):# pythonlibrary.net:# __str__ 方法用来支持 'print(dataset)',所以这里代码较多,因为在用户打印一个dataset的时候# tablib将按表格的形式将数据输出到终端result = []# Add str representation of headers.if self.__headers:result.append([str(h) for h in self.__headers])# Add str representation of rows.# pythonlibrary.net:# map函数将会把row里边的每一个元素作为参数传递给str()函数,最终每一行会变成一个字符串list被添加到result列表中result.extend(list(map(str, row)) for row in self._data)# pythonlibrary.net# 下边lens和fields_lens是用来调整输出格式,保证输出列的宽度足够放所有的列元素,美化输出lens = [list(map(len, row)) for row in result] # pythonlibrary.net: 获得每一行中每一个元素的长度field_lens = list(map(max, zip(*lens))) # pythonlibrary.net: 获得每一列中元素的最大宽度# delimiter between header and dataif self.__headers:result.insert(1, ['-' * length for length in field_lens])# pythonlibrary.net:# 使用每一个列的最大宽度,创建了一个格式化字符串,该字符串的内容类似于 {0:7}|{1:5}# 这是python格式化字符串的一种语法,它的含义是第一例的宽度为7,第二列的宽度为5format_string = '|'.join('{%s:%s}' % item for item in enumerate(field_lens))# pythonlibrary.net:# 使用上边生成的格式字符串来格式化每一行,然后放在一个list里边,最后通过 n 把他们连接起来,从而实现了# 换行的目的return 'n'.join(format_string.format(*row) for row in result)第一步,它先确认我们这个表格是否有表头(因为Tablib允许存储没有表头的表格数据),如果存在了,则把表头转换为字符串列表存在result中,接下来,使用了map函数和for循环,将dataset中的每一行的每一个单元格里边的值转换为字符串并存在result列表中。这是前置工作,目的是将数据统一转为字符串,因为表格中也许会储存数字,但是在打印的时候,所有的内容都被认为是字符串。
第二步,先使用map函数和for循环在reuslt中获取到每一行(包含了表头,因为前边将表头也加到了result中)中字符串元素的最大长度,然后利用map和zip函数,获取到每一列的中最长字符串的长度,然后它就被认为是那一列的宽度。注意:这里zip(*lens),是将lens这个以每一行中每个单元格长度的列表转换为一个每一列中每个单元格长度的列表,例如 lens = [[1,2,3], [2,5,8]] ,其中第一行为[1,2,3],第二行为[2,5,8],经过zip(*lens)之后会变成 [(1, 2), (2, 5), (3, 8)],分别为第一列的长度(1, 2),第二列的长度(2, 5),第三列的长度(3, 8),最终获得三列的宽度分别为2,5,8
第三步,生成一个叫format_string的输出模板,该模板针对一行的数据,用|将单元格隔开,并在每个单元格上填充字符串格式化表达式,类似于'{0:2}|{1:5}|{2:8}’,这样的字符串可以使用format方法来将要填入的数据代入进去并按照指定宽度输出。
第四步,利用for循环将所有的行利用format_string格式输出并用换行符连接在一起,就达到了上边看到的效果了。
最后,放上我们的源码阅读笔记仓库,欢迎下载,并加星号关注哦,谢谢,祝你阅读愉快。https://github.com/pythonlibrary/tablib-reading-notes
扫码关注微信公众号,或用电脑访问网页以获取更好的阅读体验:https://pythonlibrary.net/