阅读时间约8分钟
在爬取中文网站时,相信大家或多或少会遇到返回的是一堆乱七八糟、人类无法读懂的字符(如下图)。

刚入门的菜鸟可能花大量时间在网上各种搜索、或者各种尝试后仍然和原来一样,甚至有些人可能以为返回内容被加密了,花大量时间搜索与解密相关的内容,仍没有解决乱码的问题。
其实对于爬取内容出现乱码的原因,基本是使用错误编码将爬取内容(二进制字符)解码为字符串,只需使用正确编码就能将其转换为人类能正常读取的文字。
这个知识点可能大部分程序员都知道,但很多人不知道怎样处理爬取内容乱码的问题,本文将以requests库为例提供一种解决思路。
使用环境
requests 2.22
python 3.7.6
注意: 如果没有安装requests库,需在命令行执行pip install requests进行安装
实战案例
话不多说,看下面的中文网站实例,在浏览器下所有文字都可以正常显示。
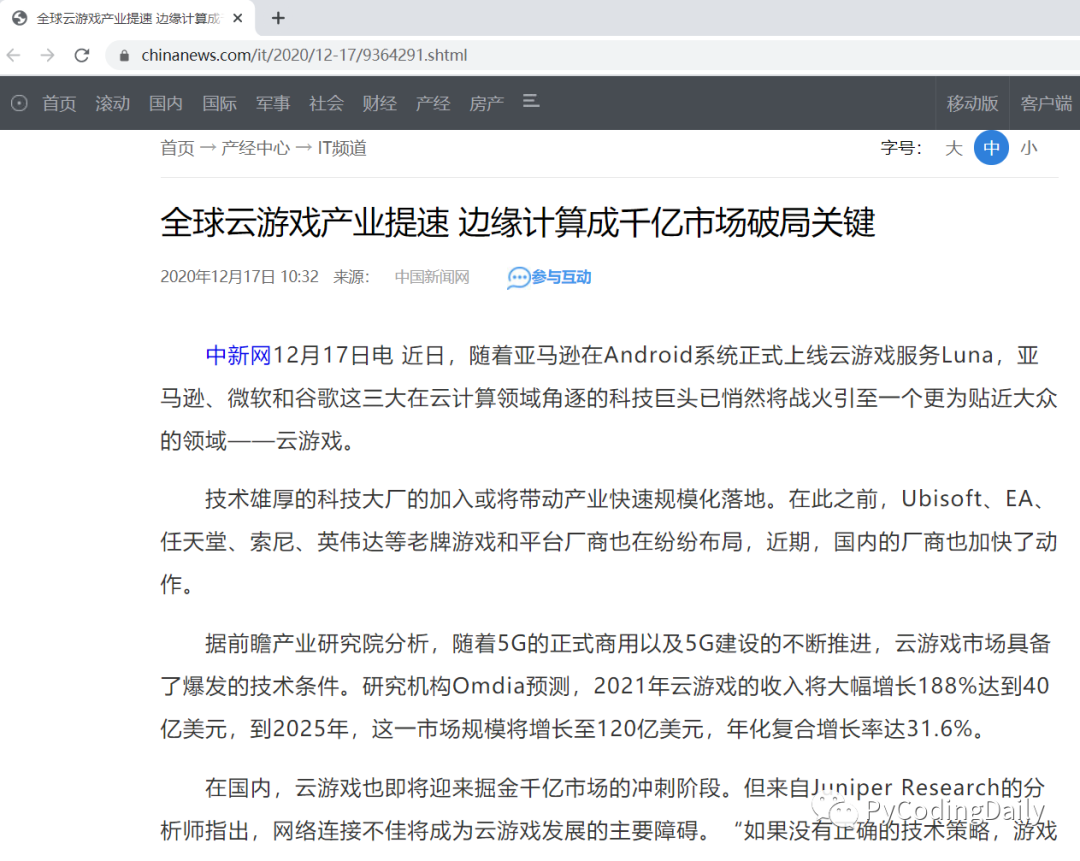
一般情况下,下面几行就能达到数据爬取的目的。
import requestsurl = 'https://www.chinanews.com/it/2020/12-17/9364291.shtml'headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.60 Safari/537.17'}response = requests.get(url, headers=headers)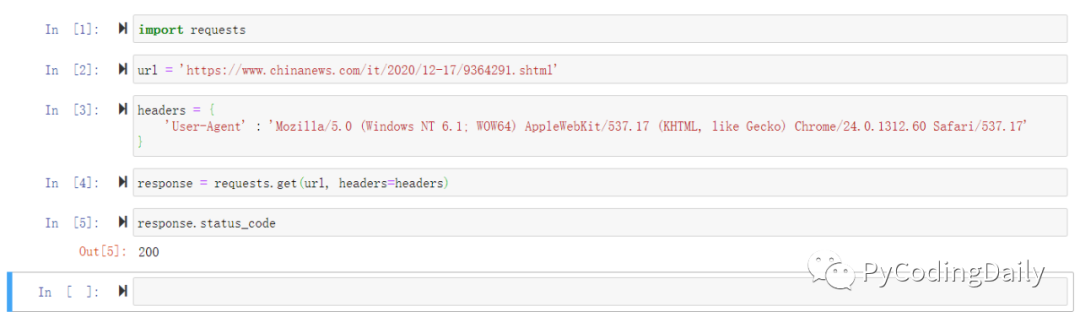
到这里代码没有错误提示,而且响应状态码也是200,大部分情况下可以使用lxml、beautiful soup或正则表达式等解析resposne.text返回的字符串。
但是本着谨慎的态度,使用response.text检查下返回的内容。
response.text# response.text 获取字符串形式的返回内容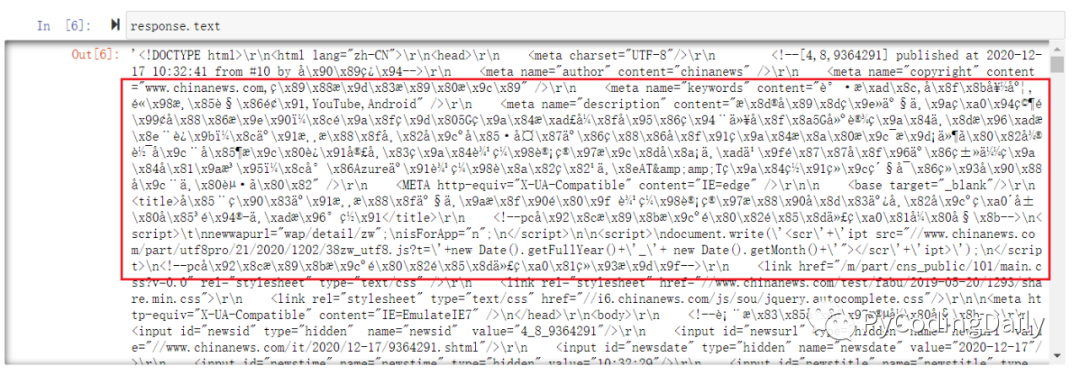
怎么输出结果与预期不一致呢??其实这一堆乱码就是上文提到的使用错误编码解码二进制字符的结果。
那如何解决乱码的问题呢?眼尖的人或有经验的人会发现到meta标签有个charset属性。
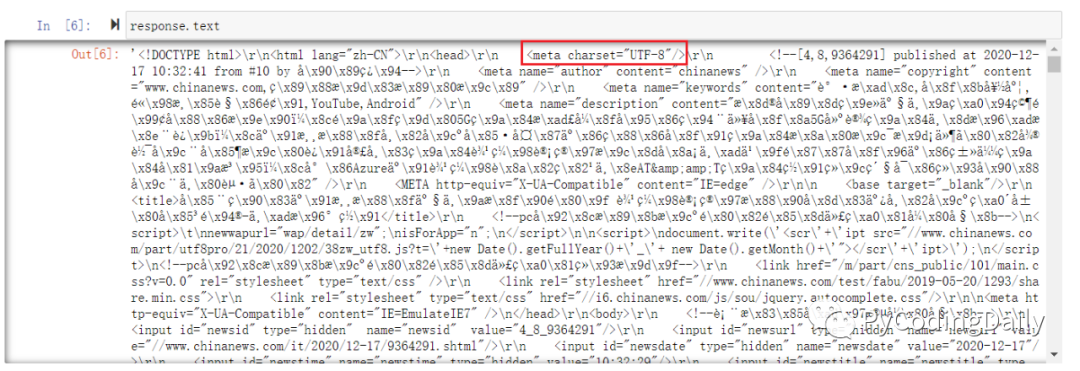
那用这个属性值的编码,试试解码结果是怎样的。
response.content.decode('utf-8')# response.content 获取二进制形式的返回内容# resposne.content.decode() 用utf-8编码将二进制字符转换为字符串
怎么出错了,难道编码不对吗?到这里不了解decode[1]语法的同学,可能又要在网上搜索一轮。
我们先看下官方文档关于decode语法的介绍。
bytes.``decode(encoding="utf-8", errors="strict")
bytearray.``decode(encoding="utf-8", errors="strict")Return a string decoded from the given bytes.
Default encoding is
'utf-8'.errors may be given to set a different error handling scheme.
The default for errors is
'strict', meaning that encoding errors raise aUnicodeError.Other possible values are
'ignore','replace'and any other name registered viacodecs.register_error(), see section Error Handlers.
重点关注第二个参数errors="strict",它是解码时出现异常的默认处理方式,它的特点是出现任何的解码异常都是直接抛出UnicodeError. 也就是说在处理过程有异常,无法继续处理。
我们留意到最后一句话Other possible values are `'ignore'`, `'replace'..., 用其中一个尝试下。
response.content.decode('utf-8', errors='replace')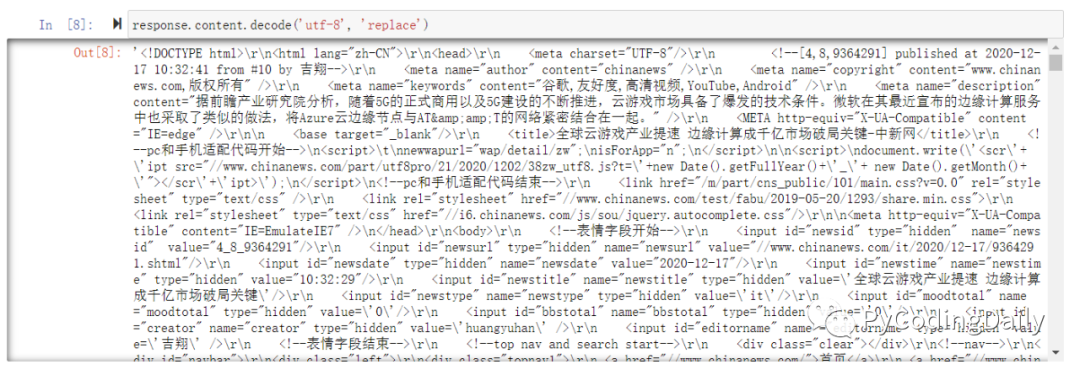
终于成功解码二进制返回内容了。但对于新手来说,需要掌握的知识点有点多,稍微忽略一些细节就马上出错了。有没有更加简答的方法呢?答案当然是有的。
在调用response.text属性前,先指定response.encoding属性。
response.encoding = 'utf-8'response.text
总结
爬取中文网站出现乱码最主要的原因是使用错误编码进行解码
一般情况下,head标签里的是网页正确的编码,但并不是所有网页都是这样(下篇文章会介绍到,敬请留意)
以requests为例,介绍了爬取中文网站出现乱码时的解决方法
仅仅两行代码就解决了因编码错误而造成的乱码问题。
response.encoding = 'utf-8'response.text下篇文章将结合requests的官方文档和源码,深入分析request.text这一行代码为何这么强大、以及使用request.text需要注意什么。
参考资料
[1] https://docs.python.org/3/library/stdtypes.html#bytes.decode
欢迎搜索关注本号