这段时间在学习python,接触到了网络编程中的socket这块,加上自己在用的Linux服务器都是原生支持python的,于是乎有了个做文件传输功能程序的想法。
毕竟python语言中,有下载功能的框架一抓一大把,但是主机与主机间快速搭建文件(夹)传输通道的程序似乎不常见,因为我刚接触python不久,但是我不知道也不奇怪,总得来说,自己做一个练手,成就感满满。
项目地址
https://github.com/Ccapton/python-stuff/tree/master/filetransporter
实操预览
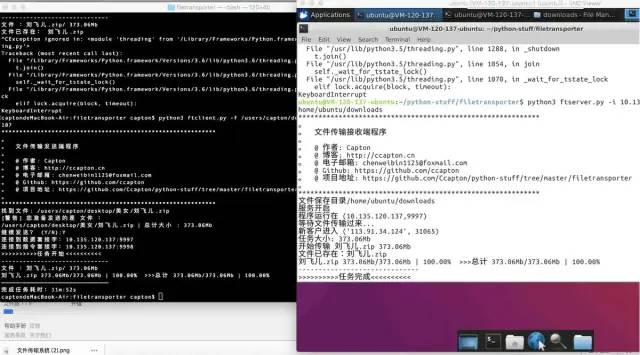
本地主机发送文件到远端服务器主机。
思维导图
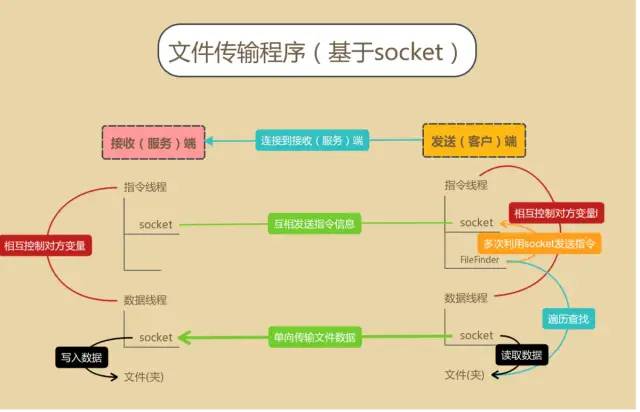 文件传输系统
文件传输系统以上思维导图仅供参考,毕竟表达能力有限,具体功能要追究到代码处才能分析其原理。
原理
基于socket的通信,相信会编程的朋友都不陌生,而通过socket来传输文件也是很常见的,但是这仅仅是对于单个文件来说很容易实现。
如果是多文件呢?
我在实现本系统之前尝试了几次,用单一socket通道来传输多文件不切实际,因为调用socket.recv()方法的时候,返回的数据格式是原始数据str类型,要分割不同文件的数据有很大难度。
因为涉及到接收、发送方两端文件数据接收和发送进度的统一性,就要用另外的指令来控制传输工作不乱套,于是我想到多开一个socket作为传输指令的通道,这样指令和数据就分离了,也就容易控制传输工作了!所以有了指令线程和数据线程之分。
要实现传输整个文件夹,首先要遍历这个文件夹,把在其内的所有文件结构准确无误的还原出来;因为是通过一个socket通过传输数据,所以传输文件只能一个接一个来,这样,文件的遍历工作只能等前一个文件传输完毕后才能继续进行,于是又要对遍历工作设计一番。
经过改造,我在文件查找(遍历)器内加入了while循环体和供外界继承的回调类,这样就能达到我想要的文件通过socket按顺序传输的效果了。
文件查找器FileFinder(阻塞型)源码:
import os,time# 文件、文件夹寻找类 (阻塞型)# 阻塞的设计:为了等待调用者的耗时操作【否则很快就完成了文件的遍历任务,调用者达不到顺序操作文件(夹)的意图】class FileFinder: def __init__(self,finderCallback): self.finderCallback = finderCallback # 文件(夹)路径下所有文件的总大小 self.sum_size = 0 # 调用者控制的参数,若为False,则遍历工作继续进行,若为True,则阻塞任务,等待调用者完成它的其他耗时操作后在考虑是否改变此值 self.recycle = True # 调用者控制的参数,若为False,则正常工作,若为True,则当recycle为False时遍历工作不阻塞快速完成,recycle为True时遍历工作阻塞 self.off = False # 文件(夹)找到时的回调类 class FinderCallback: # 找到文件夹 def onFindDir(self,dir_path): pass # 找到文件 def onFindFile(self,file_path,size): pass # 预留的刷新函数 def onRefresh(self): pass # 查找文件(夹)方法 def list_flie(self,root_dir): if os.path.isfile(root_dir): while self.recycle: time.sleep(0.05) if self.finderCallback: self.finderCallback.onFindFile(root_dir,os.path.getsize(root_dir)) self.finderCallback.onRefresh() if not self.off: self.recycle = True else: dirlist = os.listdir(root_dir) # 列出文件夹下所有的目录与文件 for dir in dirlist: path = os.path.join(root_dir, dir) if os.path.isfile(path): while self.recycle: time.sleep(0.05) if self.finderCallback: self.finderCallback.onFindFile(path,os.path.getsize(path)) self.finderCallback.onRefresh() if not self.off: self.recycle = True else: while self.recycle: time.sleep(0.05) if self.finderCallback: self.finderCallback.onFindDir(path) self.finderCallback.onRefresh() if not self.off: self.recycle = True # 递归调用(当遍历到文件夹时,继续遍历,直到当前文件夹下没有文件夹为止) self.list_flie(path)注意
运行接收端程序,需要一个能访问的地址,也即是说最好是局域网内进行文件传输工作,因为局域网本地ip都是可以直接访问的,若是在公共网络传输文件,必须知道接收方主机的公网ip和内网ip。例如我现在用到接收方主机是腾讯云的主机,内网ip是10.135.xxx.xxx,公网ip是111.120.xxx.xxx。该主机内,运行接收(服务)端程序python3 ftserver.py -i 10.135.xxx.xxx -d /home/ubuntu/downloadspython3 ftclient.py -i 111.120.xxx.xxx -f /Users/capton/desktop/bilibili- END -
原文链接:
https://www.jianshu.com/p/07ff2a7d22f4文源网络,仅供学习之用,如有侵权,联系删除。
往期精彩
◆ 50款开源工具你都用过吗?
◆ python+C、C++混合编程的应用
◆ python网络爬虫的基本原理详解