一.目的
还是Python的基础应用。这次用一下爬虫。然后看后面有没有时间,结合上一篇的可视化(需要继续深入)。试一下爬虫+可视化。弄一个东西出来,下面先弄个爬虫入门。
二 .思路分析
1.模拟发起
2.根据需求处理数据(编码处理、正则匹配)
3.存储数据
(这里补充点,要具体网址这里不放出来了)
三.具体分析(包括代码)
1.明确要爬的数据,查看其结构
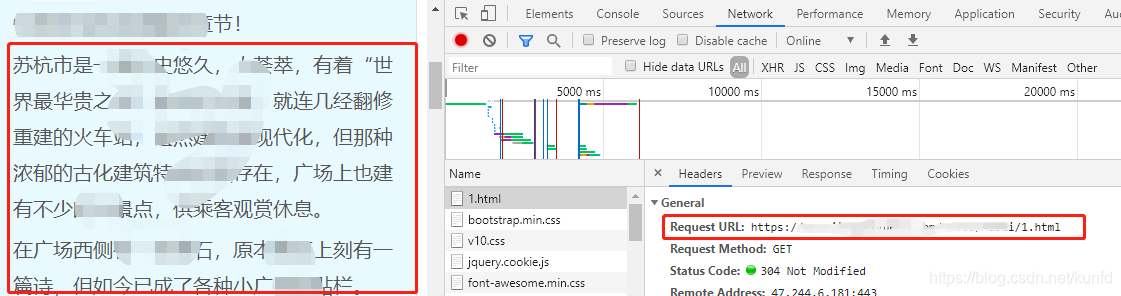
1.1.这次我们要爬的是一个小说网站具体的某本小说,结构是这样的。首先我们进入它的list页面,然后该页面会有所有章节的链接和章节名

1.2.通过浏览器的编辑模式,我们可以看到发生请求的链接,当然还有下面的文件头
1.3.这里我们可以看到,服务器返回的网页代码中,有对应的url和章节的

对应的代码
#网页地址
#文件头模拟,模拟是浏览器发起的
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3",}
url='https://xxxx/xxxxx/xxxxx/list.html'
#模拟浏览器发出,所以要加headers
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
html = response.text
2.这里的html就是我们获取到了list.html网页的所有东西,然后我们可以发现我们要的标题,和我们要的所有章节对应的东西都在特定字符串之间。然后我们可以通过正则表达式来进行匹配
#匹配取出文章题目
title = re.findall(r'<h1>(.*?)</h1>',mainContext[0])
#这里()的作用
#一方面,如果没有(),那么<h1></h1>也会被存入到title中
#另一方面,下面的()是元组的意思,就是把匹配到的内容,封装到元组中
chapter_lists = re.findall(r'<a href="(.*?)">(.*?)</a>',mainContext[0])
for chapter_single in chapter_lists:#取出每个元组chapter_single中的url,和titlechapter_url,chapter_title = chapter_single
3.获取到每个章节以后,我们来看看具体每个章节的内容。同样我们可以看到网页的代码,然后我们同样在某个字符串中获取到具体内容,然后再去掉一些多余的符号
chapter_allcontext = requests.get(chapter_url, headers=headers)chapter_allcontext.encoding = 'utf-8'chapter_context = re.findall(r'最新章节!(.*?)</p> <div>',chapter_allcontext.text)#处理数据,去掉多余的符号,得到想要的内容chapter_context = chapter_context[0].replace(' ','').replace('</p><p>','')
4.存储,我们这里是将得到的内容存储到文件中。通过
fb = open('%s.txt' % title[0],'w',encoding='utf-8')
5.完全的代码()
import requests
import re
#网页地址
#文件头模拟,模拟是浏览器发起的
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3",}
url='https://xxxxxxxxxx/list.html'
#模拟浏览器发出
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
#通过查看网页代码,可以知道主要的数据在<h1>......</dl>之间,
html = response.text
mainContext = re.findall(r'<h1>.*?</dl>',html)
#匹配取出文章题目
title = re.findall(r'<h1>(.*?)</h1>',mainContext[0])
#这里要用()???,这里()的作用
#一方面,如果没有(),那么<h1></h1>也会被存入到title中
#另一方面,下面的()是元组的意思,就是把匹配到的内容,封装到元组中
chapter_lists = re.findall(r'<a href="(.*?)">(.*?)</a>',mainContext[0])
fb = open('%s.txt' % title[0],'w',encoding='utf-8')
#循环获取每一个章节内容
for chapter_single in chapter_lists:#取出每个元组chapter_single中的url,和titlechapter_url,chapter_title = chapter_single#list中的url并没有前缀,因此要加前缀得到连接chapter_url = 'https://www.jingcaiyuedu.com/%s' % chapter_urlchapter_allcontext = requests.get(chapter_url, headers=headers)chapter_allcontext.encoding = 'utf-8'chapter_context = re.findall(r'最新章节!(.*?)</p> <div>',chapter_allcontext.text)#处理数据,去掉多余的符号chapter_context = chapter_context[0].replace(' ','').replace('</p><p>','')fb.write(chapter_title.replace('\r\r',''))fb.write('\n')fb.write(chapter_context)fb.write('\n')补充:我这里补充一下,因为我爬到的数据基本上都是在一行的,所以我正则匹配的时候少了re.S这个参数,如果你们爬到的数据,回来是有换行的,那么正则匹配需要加re.S这个参数。
mainContext = re.findall(r'<h1>.*?</dl>',html,re.S)
原因如下:
正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。a字符串有每行的末尾有一个“\n”,不过它不可见。
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。




![html5 不容易被百度收录,[百度不收录]百度不收录网站发布的文章的原因有哪些?...](https://www.nnxun.com/seo/%5Cd/filed/2020-05-19/2018101714324536.jpg)