此篇博客先对音频基础知识进行简要叙述,然后帮助读者入门 esp-sr SDK。
1 音频的基本概念
1.1 声音的本质
声音的本质是波在介质中的传播现象,声波的本质是一种波,是一种物理量。 两者不一样,声音是一种抽象的,是声波的传播现象,声波是物理量。
1.2 声音的三要素
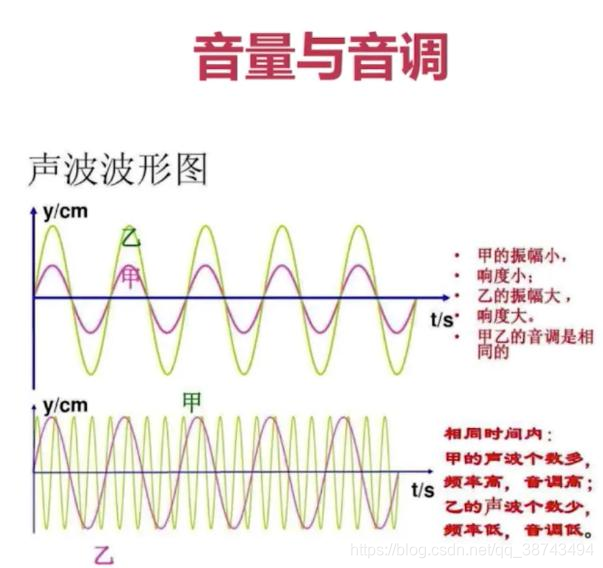
- 响度:人主观上感觉声音的大小(俗称音量),由振幅和人离声源的距离决定,振幅越大响度越大,人和声源的距离越小,响度越大。
- 音调:频率的不同决定了声音的高低(高音、低音),频率越高音调越高(频率单位为 Hz,赫兹),人耳听觉范围 20~20000 Hz。20 Hz 以下称为次声波,20000 Hz 以上称为超声波)。
- 音色:由于不同对象材料的特点,声音具有不同的特性,音色本身就是抽象的东西,但波形就是把这种抽象和直观的性能。波形因音调而异,不同的音调可以通过波形来区分。
1.3 数字音频的几个基本概念
1.3.1 采样
所谓采样就是只在时间轴上对信号进行数字化。
- 根据奈奎斯特定律(也称为采样定律),按照比声音最高频率的 2 倍上进行采样。人类听觉的频率(音调)范围为 20 Hz–20 KHz 。所以至少要大于 40 kHz。采样频率一般为 44.1 kHz,这样可保证声音达到 20 kHz 也能被数字化。44.1 kHz 就是代表 1 秒会采样 44100 次。
乐鑫AI语音采用的是 16 kHz 采样率,16 kHz 的采样频率的一半合好对应人类语音的常用频段上限约 8 kHz, 此外 44.1 kHz 采样率是另一种常用的采样率,44.1 kHz 的采样频率的一半对应人耳的可听声频率上限约 20 kHz。因为在同等时间长度内,采样率越高,数据量越大,所以:通常即时通讯类的音频会采用 16 kHz 甚至更低的采样率,以保证信号传输的及时性,但是也会对音频质量造成一定损失(比如声音发闷);而主打高质量音声的记录类音频资源会采用 44.1 kHz 甚至 48 kHz 的采样率,以更多的数据存储量为代价,保证重放信号的高保真度。

因此这部分主要包含以下三个参数:
- 比特率:比特率是每秒传输的比特数。单位为比特(bps 位/秒)。
- 采样:采样是把连续的时间信号,变成离散的数字信号。
- 采样率:采样率是每秒采集多少个样本。
1.3.2 量化
量化是指在幅度轴上对信号进行数字化。如果用 16 比特位的二进制信号来表示一个采样,那么一个采样所表示的范围即为【-32768,32767】。
乐鑫 AI 语音采用的是 16 比特的量化。
1.3.3 通道数
通道数即声音的通道数目,常见的有单声道、双声道和立体声道。
-
单声道的声音只能使用一个扬声器发声,或者也可以处理成两个扬声器输出同一个声道的声音,当通过两个扬声器回放单声道信息的时候,我们可以明显感觉到声音是从两个音箱中间传递到我们耳朵里的,无法判断声源的具体位置。
-
双声道就是有两个声音通道,其原理是人们听到声音时可以根据左耳和右耳对声音相位差来判断声源的具体位置。声音在录制过程中被分配到两个独立的声道,从而达到了很好的声音定位效果。
1.3.4 音频大小的计算
如:录制一段,时间为:1 s,采样率为 16000 HZ,采样大小为 16,通道数为 2 的音频,所占用的空间大小为 : 16000 * 16 * 2 * 1 s= 500 k
2 声学前端(Audio Front-End ,AFE)
一套乐鑫 AFE 算法框架,可基于功能强大的 ESP32 和 ESP32-S3 SoC 进行声学前端处理,使用户获得高质量且稳定的音频数据,从而构建性能卓越且高性价比的智能语音产品。
2.1 声学回声消除(AEC)
声学回声消除算法通过自适应滤波的方法,消除使用麦克风输入音频时的回声。此算法适用于语音设备通过扬声器播放音频等场景。
算法最多支持双麦处理,能够有效的去除 mic 输入信号中的自身播放声音。从而可以在自身播放音乐的情况下进行很好的语音识别等应用。
2.2 盲源分离(BSS)
盲源分离算法使用多个麦克风检测传入音频的方向,并强化某个方向的音频输入。此算法在噪音环境中提高了所需音频源的声音质量。
2.3 噪声抑制(NS)
噪声抑制算法支持单通道音频信号处理,能够有效消除无用的非人声(如吸尘器或空调声),从而改善所需处理的音频信号。
3 乐鑫 AFE 支持的场景
乐鑫 AFE 的功能针对以下两种不同场景:
-
语音识别场景
-
语音通话场景
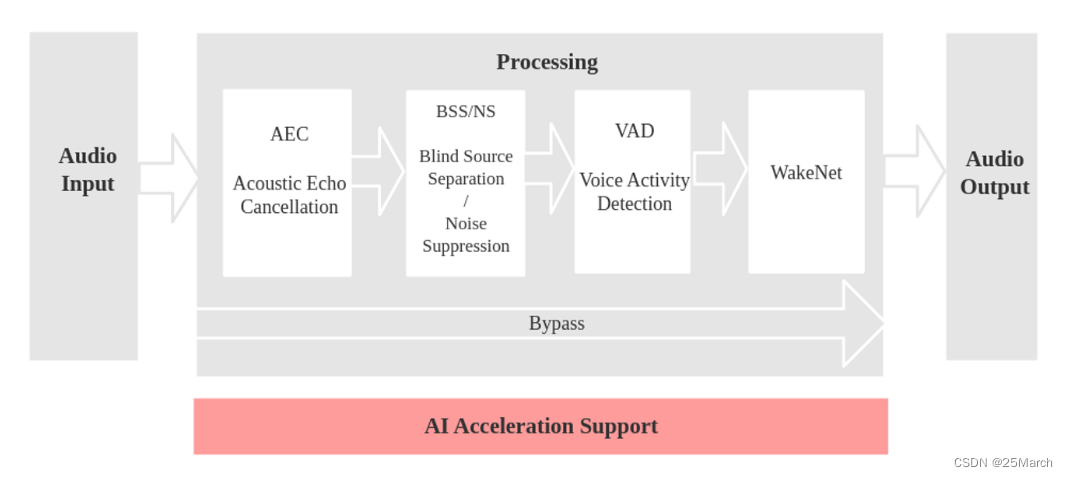
3.1 语音识别场景
模型步骤:
-
音频输入
-
AEC 进行回声消除(消除自身的音频播报,这需要回采通道)
- 硬回采:通过 IIS 直接读取写入扬声器的数据(可以和麦克风共用一路 IIS)
- 软回采:软件 copy 写入扬声器的数据(暂未支持,等待开发)
-
BSS/NS
- BSS (Blind Source Separation) 算法支持双通道处理,能够很好的将目标声源和其余干扰音进行盲源分离,从而提取出有用音频信号,保证了后级语音的质量。
- NS (Noise Suppression) 算法支持单通道处理,能够对单通道音频中的非人声噪声进行抑制,尤其针对稳态噪声,具有很好的抑制效果。
- 具体采用哪一个算法,根据配置的麦克风数量定义。
-
VAD
- VAD (Voice Activity Detection) 算法支持实时输出当前帧的语音活动状态
-
WakeNet
唤醒词
对应的流程图如下:
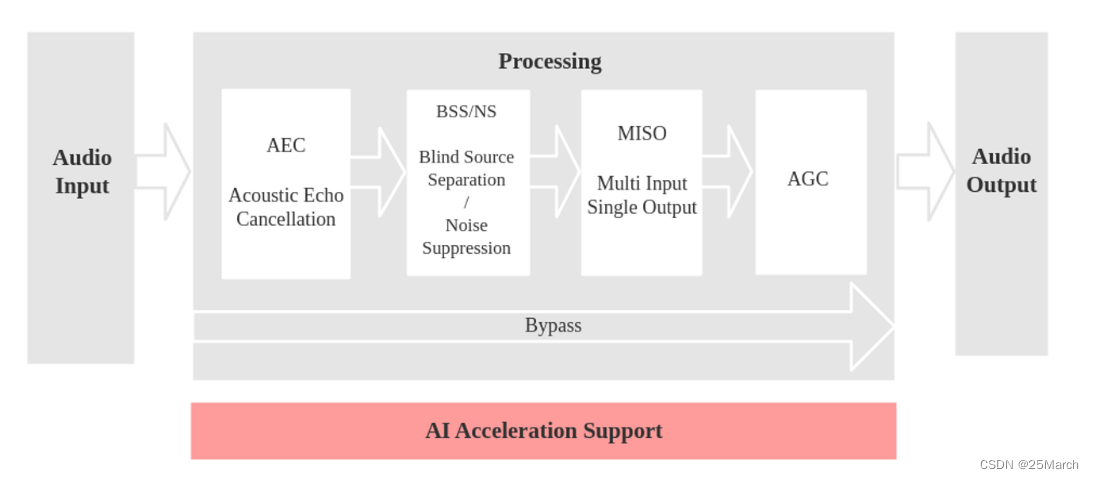
3.2 语音通话场景
模型步骤:
- 音频输入
- AEC 进行回声消除(消除自身的音频播报,这需要回采通道)
- 硬回采:通过 IIS 直接读取写入扬声器的数据(可以和麦克风共用一路 IIS)
- 软回采:软件 copy 写入扬声器的数据(暂未支持,等待开发)
- BSS/NS
- BSS (Blind Source Separation) 算法支持双通道处理,能够很好的将目标声源和其余干扰音进行盲源分离,从而提取出有用音频信号,保证了后级语音的质量。
- NS (Noise Suppression) 算法支持单通道处理,能够对单通道音频中的非人声噪声进行抑制,尤其针对稳态噪声,具有很好的抑制效果。
- 具体采用哪一个算法,根据配置的麦克风数量定义。
- MISO
- MISO (Multi Input Single Output) 算法支持双通道输入,单通道输出。用于在双麦场景,没有唤醒使能的情况下,选择信噪比高的一路音频输出。
- AGC
- AGC (Automatic Gain Control) 动态调整输出音频的幅值,当弱信号输入时,放大输出幅度;当输入信号达到一定强度时,压缩输出幅度。
对应的流程图如下:
3.3 配置代码参考
#define AFE_CONFIG_DEFAULT() { \.aec_init = true, \ //AEC 算法是否使能.se_init = true, \ //BSS/NS 算法是否使能.vad_init = true, \ //VAD 是否使能 ( 仅可在语音识别场景中使用 ).wakenet_init = true, \ //唤醒是否使能..voice_communication_init = false, \ //语音通话是否使能。与 wakenet_init 不能同时使能..voice_communication_agc_init = false, \ //语音通话中AGC是否使能.voice_communication_agc_gain = 15, \ //AGC的增益值,单位为dB.vad_mode = VAD_MODE_3, \ //VAD 检测的操作模式,越大越激进.wakenet_model_name = NULL, \ //选择唤醒词模型.wakenet_mode = DET_MODE_2CH_90, \ //唤醒的模式。对应为多少通道的唤醒,根据mic通道的数量选择.afe_mode = SR_MODE_LOW_COST, \ //SR_MODE_LOW_COST: 量化版本,占用资源较少。 //SR_MODE_HIGH_PERF: 非量化版本,占用资源较多。.afe_perferred_core = 0, \ //AFE 内部 BSS/NS/MISO 算法,运行在哪个 CPU 核.afe_perferred_priority = 5, \ //AFE 内部 BSS/NS/MISO 算法,运行的task优先级。.afe_ringbuf_size = 50, \ //内部 ringbuf 大小的配置.memory_alloc_mode = AFE_MEMORY_ALLOC_MORE_PSRAM, \ //绝大部分从外部psram分配.agc_mode = AFE_MN_PEAK_AGC_MODE_2, \ //线性放大喂给后续multinet的音频,峰值处为 -4dB。.pcm_config.total_ch_num = 3, \ //total_ch_num = mic_num + ref_num.pcm_config.mic_num = 2, \ //音频的麦克风通道数。目前仅支持配置为 1 或 2。.pcm_config.ref_num = 1, \ //音频的参考回路通道数,目前仅支持配置为 0 或 1。
}
4 AI语音模型
4.1 WakeNet
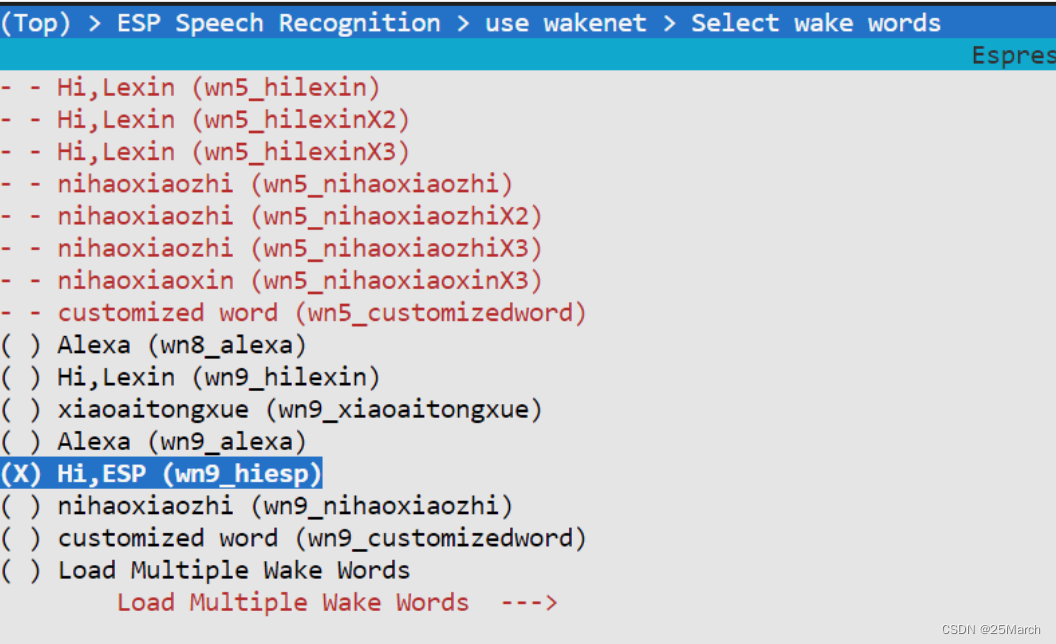
4.1.1 通过 menuconfig 选择模型
wn9_hiesp(最新的 wn9 都是默认 8 bit 量化): 版本 9 ,唤醒词是 hi,esp
4.2 multinet
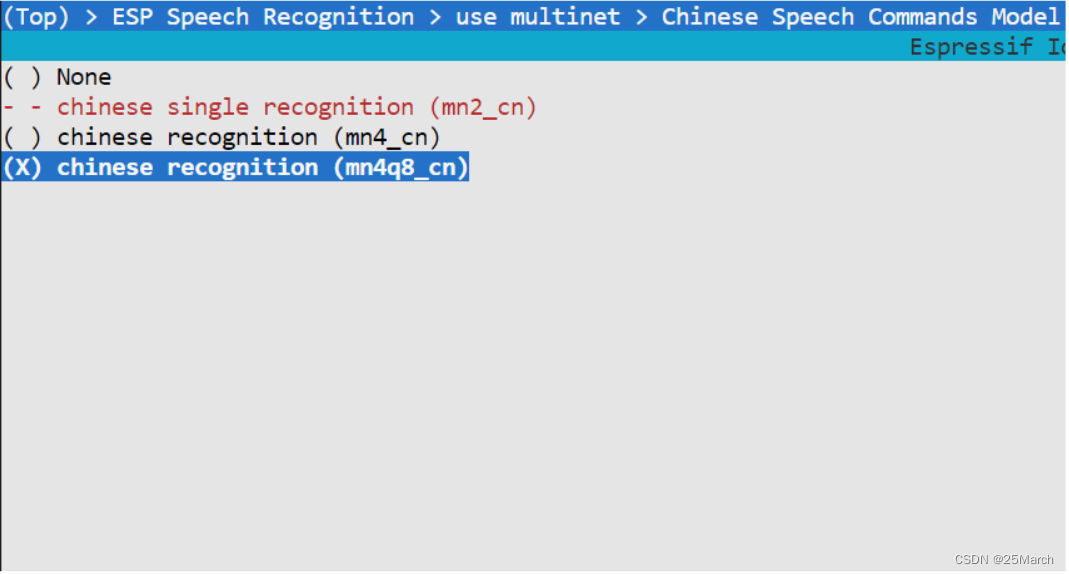
4.2.1 通过 menuconfig 选择模型
mn4q8_cn : 版本 4 ,8 bit 量化,中文命令词
4.3 添加命令词
4.3.1 通过 menuconfig 添加命令词
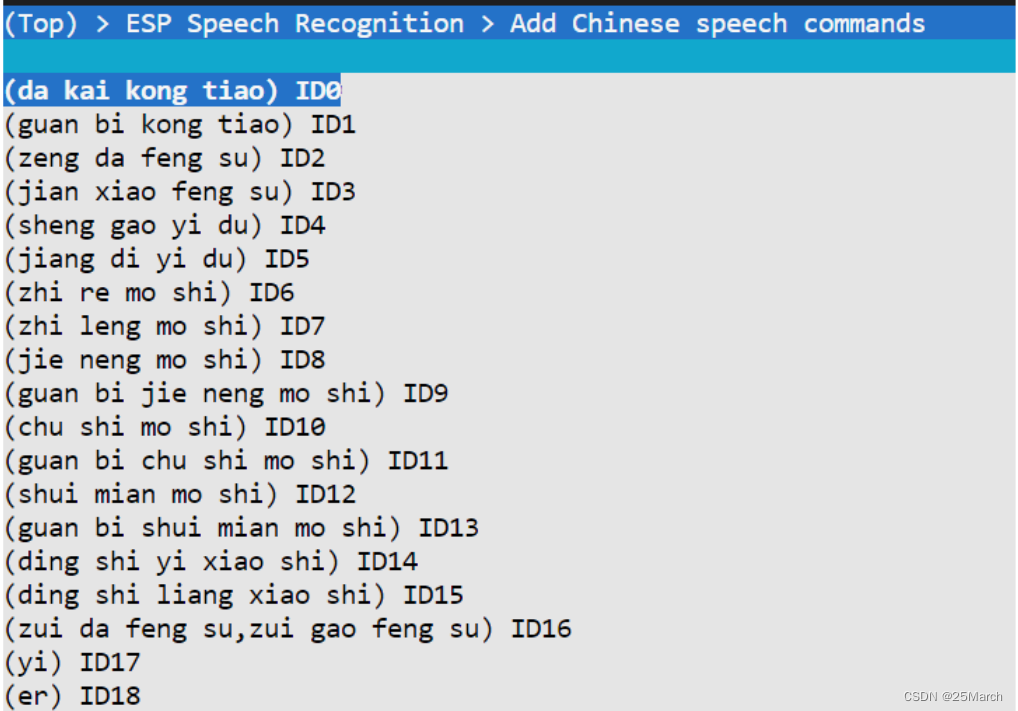
-
中文命令词直接添加拼音:打开空调(da kai kong tiao),也支持多句话支持同一个 COMMAND ID , 最大风速/最高风速
添加方言命令词:添加对应的发音
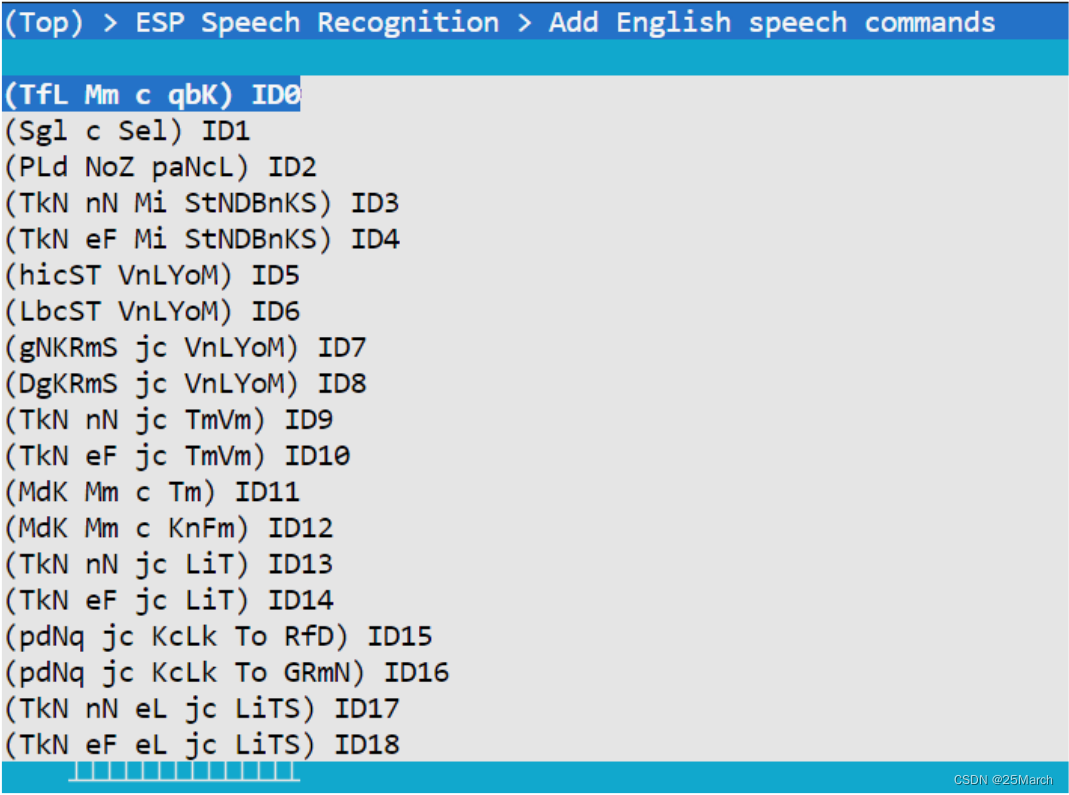
-
英文命令词需要添加对应的音素,通过 python 脚本生成
4.3.2 代码中动态添加命令词
esp_mn_commands_add(i, token);
通过调用 api 实现动态添加命令词。
算法性能
仅消耗约 20% CPU, 30 KB SRAM 和 500 KB PSRAM
5 麦克风设计
5.1 麦克风性能推荐
-
麦克类型:全向型 MEMS ⻨克⻛。
-
灵敏度:
- 1 Pa 声压下模拟⻨灵敏度不低于 -38 dBV,数字⻨灵敏度要求不低于 -26 dB
- 公差控制在 ±2 dB,对于⻨克阵列推荐采⽤ ±1 dB 公差
-
信噪比
信噪⽐不低于 62 dB,推荐 >64 dB :
信噪比越高声音越保真
- Frequency response:频率响应在 50 ~16 kHz 范围内的波动在 ±3 dB 之内
- 电源抑制比(PSRR):n >55 dB(MEMS MIC)
6 结构设计建议
-
⻨克孔孔径或宽度推荐⼤于 1 mm,拾⾳管道尽量短,腔体尽可能⼩,保证⻨克和结构组件配合的谐振频 率在 9 KHz 以上。
-
拾⾳孔深度和直径⽐⼩于 2:1,壳体厚度推荐1 mm,如果壳体过厚,需增⼤开孔⾯积。
-
⻨克孔上需通过防尘⽹进⾏保护。
-
⻨克⻛与设备外壳之间必须加硅胶套或泡棉等进⾏密封和防震,需进⾏过盈配合设计,以保证⻨克的密封性。
-
⻨克孔不能被遮挡,底部拾⾳的⻨克孔需结构上增加凸起,避免⻨克孔被桌⾯等遮挡。
-
⻨克需远离喇叭等会产⽣噪⾳或振动的物体摆放,且与喇叭⾳腔之间通过橡胶垫等隔离缓冲。
7 代码讲解(CN_SPEECH_COMMANDS_RECOGNITION)
7.1 头文件
#include "esp_wn_iface.h" //唤醒词模型的一系列API
#include "esp_wn_models.h" //根据输入的模型名称得到具体的唤醒词模型
#include "esp_afe_sr_iface.h" //语音识别的音频前端算法的一系列API
#include "esp_afe_sr_models.h" //语音前端模型的声明
#include "esp_mn_iface.h" //命令词模型的一系列API
#include "esp_mn_models.h" //命令词模型的声明
#include "esp_board_init.h" //开发板硬件初始化
#include "driver/i2s.h" //i2s 驱动
#include "speech_commands_action.h" //根据识别到的 command 进行语音播报/闪烁 LED
#include "model_path.h" //从 spiffs 文件管理中返回模型路径等 API
7.2 app_main
void app_main()
{models = esp_srmodel_init("model"); //spiffs 中的所有可用模型或 model 默认是从`flash`读ESP_ERROR_CHECK(esp_board_init(AUDIO_HAL_08K_SAMPLES, 1, 16)); //Special config for dev board // ESP_ERROR_CHECK(esp_sdcard_init("/sdcard", 10)); //初始化 SD card
#if defined CONFIG_ESP32_KORVO_V1_1_BOARDled_init(); //LED 初始化
#endifafe_handle = &ESP_AFE_SR_HANDLE; afe_config_t afe_config = AFE_CONFIG_DEFAULT(); //音频前端的配置项afe_config.wakenet_model_name = esp_srmodel_filter(models, ESP_WN_PREFIX, NULL);; //从有所可用的模型中找到唤醒词模型的名字
#if defined CONFIG_ESP32_S3_BOX_BOARD || defined CONFIG_ESP32_S3_EYE_BOARDafe_config.aec_init = false;
#endif//afe_config.aec_init = false; //关闭 AEC//afe_config.se_init = false; //关闭 SE//afe_config.vad_init = false; //关闭VAD//afe_config.pcm_config.total_ch_num = 2; //设置为单麦单回采//afe_config.pcm_config.mic_num = 1; //麦克风通道一esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(&afe_config);xTaskCreatePinnedToCore(&feed_Task, "feed", 4 * 1024, (void*)afe_data, 5, NULL, 0); //feed 从 i2s 拿到音频数据xTaskCreatePinnedToCore(&detect_Task, "detect", 8 * 1024, (void*)afe_data, 5, NULL, 1); //将音频数据喂给模型获取检测结果#if defined CONFIG_ESP32_S3_KORVO_1_V4_0_BOARD || defined CONFIG_ESP32_KORVO_V1_1_BOARDxTaskCreatePinnedToCore(&led_Task, "led", 2 * 1024, NULL, 5, NULL, 0); //开启LED
#endif
#if defined CONFIG_ESP32_S3_KORVO_1_V4_0_BOARD || CONFIG_ESP32_S3_KORVO_2_V3_0_BOARD || CONFIG_ESP32_KORVO_V1_1_BOARDxTaskCreatePinnedToCore(&play_music, "play", 2 * 1024, NULL, 5, NULL, 1); //开启语音播报
#endif
}
7.2 feed 操作
void feed_Task(void *arg)
{esp_afe_sr_data_t *afe_data = arg;int audio_chunksize = afe_handle->get_feed_chunksize(afe_data);int nch = afe_handle->get_channel_num(afe_data);int feed_channel = esp_get_feed_channel(); //3;int16_t *i2s_buff = malloc(audio_chunksize * sizeof(int16_t) * feed_channel);assert(i2s_buff);size_t bytes_read;while (1) {//第一种方式 //audio_chunksize:音频时间 512->32ms 256->16ms//int16_t:16位量化//feed_channel:两麦克风通道数据一回采通道数据esp_get_feed_data(i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel);//第二种方式i2s_read(I2S_NUM_1, i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel, &bytes_read, portMAX_DELAY);afe_handle->feed(afe_data, i2s_buff);}afe_handle->destroy(afe_data);vTaskDelete(NULL);
}
7.3 detect 操作
void detect_Task(void *arg)
{esp_afe_sr_data_t *afe_data = arg;int afe_chunksize = afe_handle->get_fetch_chunksize(afe_data);int nch = afe_handle->get_channel_num(afe_data);char *mn_name = esp_srmodel_filter(models, ESP_MN_PREFIX, ESP_MN_CHINESE); //从模型队列中获取命令词模型名字printf("multinet:%s\n", mn_name);esp_mn_iface_t *multinet = esp_mn_handle_from_name(mn_name); //获取命令词模型model_iface_data_t *model_data = multinet->create(mn_name, 5760); //创建esp_mn_commands_update_from_sdkconfig(multinet, model_data); // Add speech commands from sdkconfigint mu_chunksize = multinet->get_samp_chunksize(model_data);int chunk_num = multinet->get_samp_chunknum(model_data);assert(mu_chunksize == afe_chunksize);printf("------------detect start------------\n");// FILE *fp = fopen("/sdcard/out1", "w");// if (fp == NULL) printf("can not open file\n");while (1) {afe_fetch_result_t* res = afe_handle->fetch(afe_data); //获得AEF的处理结果if (!res || res->ret_value == ESP_FAIL) {printf("fetch error!\n");break;}
#if CONFIG_IDF_TARGET_ESP32if (res->wakeup_state == WAKENET_DETECTED) { printf("wakeword detected\n");play_voice = -1;detect_flag = 1;afe_handle->disable_wakenet(afe_data);printf("-----------listening-----------\n");}
#elif CONFIG_IDF_TARGET_ESP32S3if (res->wakeup_state == WAKENET_DETECTED) { printf("WAKEWORD DETECTED\n"); //如果被唤醒将唤醒标志置位True} else if (res->wakeup_state == WAKENET_CHANNEL_VERIFIED) {play_voice = -1;detect_flag = 1;printf("AFE_FETCH_CHANNEL_VERIFIED, channel index: %d\n", res->trigger_channel_id);}
#endifif (detect_flag == 1) {esp_mn_state_t mn_state = multinet->detect(model_data, res->data); //将AFE处理后的音频数据给命令词模型if (mn_state == ESP_MN_STATE_DETECTING) {continue;}if (mn_state == ESP_MN_STATE_DETECTED) {esp_mn_results_t *mn_result = multinet->get_results(model_data); //得到结果for (int i = 0; i < mn_result->num; i++) {printf("TOP %d, command_id: %d, phrase_id: %d, prob: %f\n", i+1, mn_result->command_id[i], mn_result->phrase_id[i], mn_result->prob[i]);}printf("\n-----------listening-----------\n");}if (mn_state == ESP_MN_STATE_TIMEOUT) { //超时关闭afe_handle->enable_wakenet(afe_data);detect_flag = 0;printf("\n-----------awaits to be waken up-----------\n");continue;}}}afe_handle->destroy(afe_data);vTaskDelete(NULL);
}
8 乐鑫 AI 相关 Github 参考
- esp-sr:同时可以参考 esp-sr 文档
- esp-skainet