需要爬取 1622 个高校的数据 , 序号 ,地区 学校代码 , 学校名称 , 选课科目要求 , 学校网址 。
因为此网站禁用了右键, 所以直接用 python 代码分析 网站html 。

form 表格的 一行 html代码如上 。 都是在 td 标签下, 直接改中国大学排名定向爬虫实例 代码。
(1) 获取 html 信息
def getHTMLText(url):# 获取html的所有信息try:headers = {'User-Agent': 'Mozilla/5.0(Macintosh; Intel Mac OS X 10_11_4)\AppleWebKit/537.36(KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36'}r = requests.get(url,headers=headers, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:print("异常")
(2) 获取除了选课科目要求之外的其他列信息
def fillUnivList(ulist, html,url):# 解析htmlsoup = BeautifulSoup(html, 'lxml')for tr in soup.find('tbody').children:linklist = []# isinstance()函数来判断一个对象是否是一个已知的类型,类似if isinstance(tr, bs4.element.Tag):# 过滤tr的类型tds = tr('td') # 所有的td标签hraf = tr('a') # 获取学校网址# print(hraf[1].get('href'))ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string,hraf[1].get('href')])
(3) 分析每个学校选课科目要求url的相同点
发现都是
http://xkkm.sdzk.cn/zy-manager-web/gxxx/searchInfor查看html
<input name="dm" type="hidden" value="10293"/>
<input name="mc" type="hidden" value="%E5%8D%97%E4%BA%AC%E9%82%AE%E7%94%B5%E5%A4%A7%E5%AD%A6"/>url 和 这两个有关系。
分析出 url = http://xkkm.sdzk.cn/zy-manager-web/gxxx/searchInfor + ? dm = 值 &mc = 值
所以只需要提取出来dm 和mc 即可
fillUnivList 增加代码 :
lista = []for i, input in enumerate(soup.find_all(name='input')):# print(i,input)if i %2 == 0 :lista.append([input['value']])# print(i, input['name'], '\t', input['value'])j = 1urllists = []for u in ulist :p = url+'?'+'dm='+u[2]+'&'+'mc='+lista[j][0]j+=1urllists.append(p)return urllistsurllists 就是所有学校的 选课科目要求的url 。
(4) 爬取所有学校的考试科目要求

在提取类中所含专业时处理起来不同容易。
<tr style="width:100%;">
<td width="5%" style="text-align:center; white-space: nowrap;display:table-cell; vertical-align:middle;">3</td>
<td width="10%" style="text-align:center; white-space: nowrap;display:table-cell; vertical-align:middle;">本科</td>
<td width="25%" align="left"style="display:table-cell; vertical-align:middle;">
中国语言文学类
</td>
<td width="30%" align="left" style="display:table-cell; vertical-align:middle;">不提科目要求</td>
<td width="30%" align="left" style="white-space: nowrap;" >
<!-- 用jstl的fn标签库对传过来的专业中的'、'进行替换成<br/> -->
汉语言文学(中国文学)<br/>汉语言(汉语语言学)<br/>古典文献学
</td>
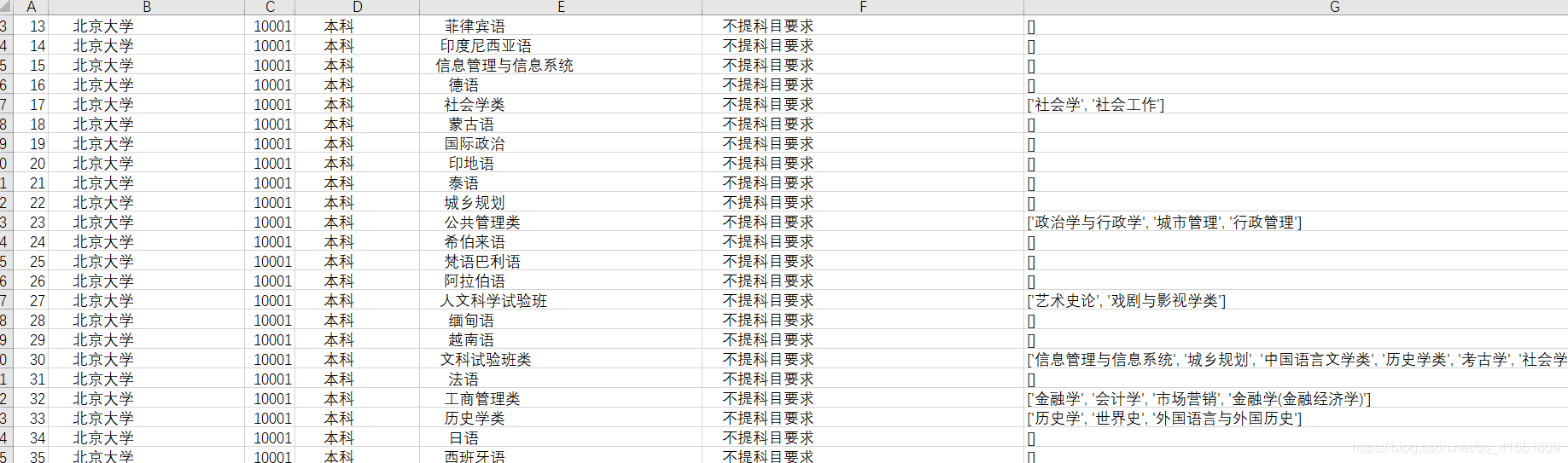
</tr>def getcontent(html):unilist = []soup = BeautifulSoup(html, 'lxml')j = 1bf = BeautifulSoup(html, 'html.parser')# 提取 学校名称和代码articles = bf.find_all("div", {"class": "center"})j = 1for i in articles :if j == 2 :ans = ibreakj+=1# print(type(ans))name = "".join(ans.get_text()).split()[0][5:]code = "".join(ans.get_text()).split()[1][5:]#提取其他信息for tr in soup.find('tbody').children:# isinstance()函数来判断一个对象是否是一个已知的类型,类似# type()# tdList = re.findall(r'<td[^>]*>(.*?)</td>', html, re.I | re.M)# print(tdList)if isinstance(tr, bs4.element.Tag):tds = tr('td')tds0 = tds[0].stringtds1 = tds[1].stringtds2 = "".join(tds[2].string.split())tds3 = "".join(tds[3].string.split())# print(tds0 , tds1 ,tds2 ,tds3 )tl = []for tds4_ in tds[4] :if isinstance(tds4_, bs4.element.Comment):passelse:if isinstance(tds4_, bs4.element.Tag):passelse:tlo = "".join(tds4_.string.split()) tl.append("".join(str(tlo)))tl = [x for x in tl if x != '']tl = [x for x in tl if x != '']unilist.append([tds0,name,code,tds1,tds2,tds3,tl])return unilist(5)结果
(6) 全部代码
import requests
from bs4 import BeautifulSoup ,Comment
import bs4
import re
import csv
import codecs
import jieba
from w3lib.html import remove_commentsimport xlwt
def getHTMLText(url):# 获取html的所有信息try:headers = {'User-Agent': 'Mozilla/5.0(Macintosh; Intel Mac OS X 10_11_4)\AppleWebKit/537.36(KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36'}r = requests.get(url,headers=headers, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:print("异常")def fillUnivList(ulist, html,url):# 解析htmlsoup = BeautifulSoup(html, 'lxml')for tr in soup.find('tbody').children:linklist = []# isinstance()函数来判断一个对象是否是一个已知的类型,类似if isinstance(tr, bs4.element.Tag):# 过滤tr的类型tds = tr('td') # 所有的td标签hraf = tr('a') # 获取学校网址# print(hraf[1].get('href'))ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string,hraf[1].get('href')])lista = []for i, input in enumerate(soup.find_all(name='input')):# print(i,input)if i %2 == 0 :lista.append([input['value']])# print(i, input['name'], '\t', input['value'])j = 1urllists = []for u in ulist :p = url+'?'+'dm='+u[2]+'&'+'mc='+lista[j][0]j+=1urllists.append(p)return urllistsdef printUniveList(ulist, num):# 格式化输出 chr12288 中文填充tplt = "{0:^5}\t{1:{4}^5}\t{2:^5}\t{3:{5}^5}\t{4:{5}^5}" # {4},{5}表示用第三种方式填充# print(tplt.format("排名", "学校名称", "省份", "总分", chr(12288), chr(12288)))for i in range(num):u = ulist[i]print(u[0],'\t' ,u[1],'\t', u[2],'\t' ,u[3],'\t\t\t', u[4])# print(tplt.format(u[0], u[1], u[2], u[3],u[4], chr(12288), chr(12288)))# 将数据写入新文件
def data_write(file_path, datas,index):f = xlwt.Workbook()sheet1 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) # 创建sheet# 将数据写入第 i 行,第 j 列i = indexfor data in datas:for j in range(len(data)):sheet1.write(i, j, data[j])i = i + 1f.save(file_path) # 保存文件def getcontent(html):unilist = []soup = BeautifulSoup(html, 'lxml')j = 1bf = BeautifulSoup(html, 'html.parser')articles = bf.find_all("div", {"class": "center"})j = 1for i in articles :if j == 2 :ans = ibreakj+=1# print(type(ans))name = "".join(ans.get_text()).split()[0][5:]code = "".join(ans.get_text()).split()[1][5:]for tr in soup.find('tbody').children:# isinstance()函数来判断一个对象是否是一个已知的类型,类似# type()# tdList = re.findall(r'<td[^>]*>(.*?)</td>', html, re.I | re.M)# print(tdList)if isinstance(tr, bs4.element.Tag):tds = tr('td')tds0 = tds[0].stringtds1 = tds[1].stringtds2 = "".join(tds[2].string.split())tds3 = "".join(tds[3].string.split())# print(tds0 , tds1 ,tds2 ,tds3 )tl = []for tds4_ in tds[4] :if isinstance(tds4_, bs4.element.Comment):passelse:if isinstance(tds4_, bs4.element.Tag):passelse:# print(tds4_.string.split())tlo = "".join(tds4_.string.split())# print(tlo)tl.append("".join(str(tlo)))tl = [x for x in tl if x != '']# kp = ",".join(tl)# print(kp)# print(tl)tl = [x for x in tl if x != '']unilist.append([tds0,name,code,tds1,tds2,tds3,tl])return unilist# for u in unilist :# print(u)def data_write_csv(file_name, datas):#file_name为写入CSV文件的路径,datas为要写入数据列表file_csv = codecs.open(file_name,'w+','utf-8')#追加writer = csv.writer(file_csv, delimiter=' ', quotechar=' ', quoting=csv.QUOTE_MINIMAL)for data in datas:writer.writerow(data)print("保存文件成功,处理结束")def main():urls = []url = "http://xkkm.sdzk.cn/zy-manager-web/html/xx.html#"html = getHTMLText(url)uinfo = []up = 'http://xkkm.sdzk.cn/zy-manager-web/gxxx/searchInfor'u = "http://xkkm.sdzk.cn/zy-manager-web/gxxx/searchInfor?dm=10001&mc=%25E5%258C%2597%25E4%25BA%25AC%25E5%25A4%25A7%25E5%25AD%25A6"urllist = fillUnivList(uinfo,html,up)# http: // xkkm.sdzk.cn // zy - manager - web / gxxx / searchInfor?id = 10300j = 1index = 0'''f = xlwt.Workbook()sheet1 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) # 创建sheetg = 1for i in range(3):html = getHTMLText(urllist[i])cp = getcontent(html)# 将数据写入第 i 行,第 j 列for data in cp:for j in range(len(data)):sheet1.write(index, j, data[j])index = index + 1# print(index)print(g ,"爬取成功 !")g+=1f.save("data.xls") # 保存文件'''with open("data5.txt" ,"w",encoding='utf-8') as f :for i in range(len(urllist)):try:html = getHTMLText(urllist[i])# print(html)cp = getcontent(html)for con in cp :line = "{0:^15}\t{1:^15}\t{2:^15}\t{3:^15}\t{4:^15}\t{5:^15}\t".format(con[0],con[1],con[2],con[3],con[4],con[5])# f.write(con[0]+'\t'+ con[1]+'\t'+ con[2]+ '\t'+ con[3]+ '\t'+con[4]+'\t\t\t'+con[5]+'\t\t')f.write(line)f.write(str(con[6]))f.write("\n")f.write("\n")print(j, " 爬取成功!")j+=1except:print("异常")main()爬取的文件:
链接:https://pan.baidu.com/s/1j3HQbjPNlLnef0DqaluzGw
提取码:hu6e