import pandas as pd
from sqlalchemy import create_engine
engine = create_engine( 'mysql+pymysql://root:@localhost/wangye?charset=utf8' )
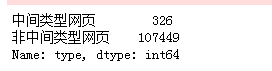
sql = pd. read_sql( 'all_gzdata' , engine, chunksize = 10000 ) def countmidques ( i) : j = i[ [ 'fullURL' , 'fullURLId' , 'realIP' ] ] . copy( ) j[ 'type' ] = u'非中间类型网页' j[ 'type' ] [ j[ 'fullURL' ] . str . contains( 'midques_' ) ] = u'中间类型网页' return j[ 'type' ] . value_counts( )
counts1 = [ countmidques( i) for i in sql]
counts1 = pd. concat( counts1) . groupby( level= 0 ) . sum ( )
counts1
engine = create_engine( 'mysql+pymysql://root:@localhost/wangye?charset=utf8' )
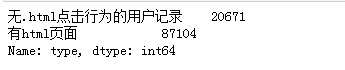
sql = pd. read_sql( 'all_gzdata' , engine, chunksize = 10000 ) def countnohtml ( i) : j = i[ [ 'fullURL' , 'pageTitle' , 'fullURLId' ] ] . copy( ) j[ 'type' ] = u'有html页面' j[ 'type' ] [ j[ 'fullURL' ] . str . contains( '\.html' ) == False ] = u'无.html点击行为的用户记录' return j[ 'type' ] . value_counts( )
counts2 = [ countnohtml( i) for i in sql]
counts2 = pd. concat( counts2) . groupby( level= 0 ) . sum ( )
counts2
engine = create_engine( 'mysql+pymysql://root:@localhost/wangye?charset=utf8' )
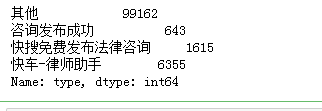
sql = pd. read_sql( 'all_gzdata' , engine, chunksize = 10000 ) def countothers ( i) : j = i[ [ 'fullURL' , 'pageTitle' , 'fullURLId' ] ] . copy( ) j[ 'type' ] = u'其他' j[ 'pageTitle' ] . fillna( u'空' , inplace= True ) j[ 'type' ] [ j[ 'pageTitle' ] . str . contains( u'快车-律师助手' ) ] = u'快车-律师助手' j[ 'type' ] [ j[ 'pageTitle' ] . str . contains( u'咨询发布成功' ) ] = u'咨询发布成功' j[ 'type' ] [ ( j[ 'pageTitle' ] . str . contains( u'免费发布法律咨询' ) ) | ( j[ 'pageTitle' ] . str . contains( u'法律快搜' ) ) ] = u'快搜免费发布法律咨询' return j[ 'type' ] . value_counts( )
counts3 = [ countothers( i) for i in sql]
counts3 = pd. concat( counts3) . groupby( level= 0 ) . sum ( )
counts3
engine = create_engine( 'mysql+pymysql://root:@localhost/wangye?charset=utf8' )
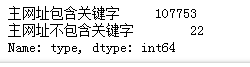
sql = pd. read_sql( 'all_gzdata' , engine, chunksize = 10000 ) def deletquesafter ( i) : j = i[ [ 'fullURL' ] ] . copy( ) j[ 'fullURL' ] = j[ 'fullURL' ] . str . replace( '\?.*' , '' ) j[ 'type' ] = u'主网址不包含关键字' j[ 'type' ] [ j[ 'fullURL' ] . str . contains( 'lawtime' ) ] = u'主网址包含关键字' return jcounts4 = [ deletquesafter( i) for i in sql]
counts4 = pd. concat( counts4)
len ( counts4)
counts4[ 'type' ] . value_counts( )
engine = create_engine( 'mysql+pymysql://root:@localhost/wangye?charset=utf8' )
sql = pd. read_sql( 'all_gzdata' , engine, chunksize = 10000 ) def countduplicate ( i) : j = i[ [ 'fullURL' , 'timestamp_format' , 'realIP' ] ] . copy( ) return jcounts5 = [ countduplicate( i) for i in sql]
counts5 = pd. concat( counts5)
print ( counts5. head( ) ) print ( len ( counts5[ counts5. duplicated( ) == True ] ) )
print ( len ( counts5. drop_duplicates( ) ) )
a = counts5. drop_duplicates( )