Scrapy是一个用于抓取网站和提取结构化数据的应用框架,可用于广泛的有用应用,如数据挖掘、信息处理或历史档案。也可以使用api提取数据,或者作为一个通用的web爬虫。
安装
C:\Users\lifeng01>pip install scrapy
Collecting scrapyDownloading Scrapy-2.5.1-py2.py3-none-any.whl (254 kB)|████████████████████████████████| 254 kB 58 kB/s
Requirement already satisfied: Twisted[http2]>=17.9.0 in d:\python\python37\lib\site-packages (from scrapy) (21.2.0)
Requirement already satisfied: itemloaders>=1.0.1 in d:\python\python37\lib\site-packages (from scrapy) (1.0.4)
Requirement already satisfied: w3lib>=1.17.0 in d:\python\python37\lib\site-packages (from scrapy) (1.22.0)
Requirement already satisfied: queuelib>=1.4.2 in d:\python\python37\lib\site-packages (from scrapy) (1.6.1)
Requirement already satisfied: parsel>=1.5.0 in d:\python\python37\lib\site-packages (from scrapy) (1.6.0)
Requirement already satisfied: protego>=0.1.15 in d:\python\python37\lib\site-packages (from scrapy) (0.1.16)
Requirement already satisfied: cssselect>=0.9.1 in d:\python\python37\lib\site-packages (from scrapy) (1.1.0)
Requirement already satisfied: h2<4.0,>=3.0 in d:\python\python37\lib\site-packages (from scrapy) (3.2.0)
Requirement already satisfied: zope.interface>=4.1.3 in d:\python\python37\lib\site-packages (from scrapy) (5.3.0)
Requirement already satisfied: pyOpenSSL>=16.2.0 in d:\python\python37\lib\site-packages (from scrapy) (20.0.1)
Requirement already satisfied: lxml>=3.5.0 in d:\python\python37\lib\site-packages (from scrapy) (4.5.0)
Requirement already satisfied: itemadapter>=0.1.0 in d:\python\python37\lib\site-packages (from scrapy) (0.3.0)
Requirement already satisfied: PyDispatcher>=2.0.5 in d:\python\python37\lib\site-packages (from scrapy) (2.0.5)
Requirement already satisfied: service-identity>=16.0.0 in d:\python\python37\lib\site-packages (from scrapy) (21.1.0)
Requirement already satisfied: cryptography>=2.0 in d:\python\python37\lib\site-packages (from scrapy) (3.4.7)
Requirement already satisfied: cffi>=1.12 in d:\python\python37\lib\site-packages (from cryptography>=2.0->scrapy) (1.14.5)
Requirement already satisfied: hyperframe<6,>=5.2.0 in d:\python\python37\lib\site-packages (from h2<4.0,>=3.0->scrapy) (5.2.0)
Requirement already satisfied: hpack<4,>=3.0 in d:\python\python37\lib\site-packages (from h2<4.0,>=3.0->scrapy) (3.0.0)
Requirement already satisfied: jmespath>=0.9.5 in d:\python\python37\lib\site-packages (from itemloaders>=1.0.1->scrapy) (0.9.5)
Requirement already satisfied: six>=1.6.0 in d:\python\python37\lib\site-packages (from parsel>=1.5.0->scrapy) (1.14.0)
Requirement already satisfied: attrs>=19.1.0 in d:\python\python37\lib\site-packages (from service-identity>=16.0.0->scrapy) (19.3.0)
Requirement already satisfied: pyasn1-modules in d:\python\python37\lib\site-packages (from service-identity>=16.0.0->scrapy) (0.2.8)
Requirement already satisfied: pyasn1 in d:\python\python37\lib\site-packages (from service-identity>=16.0.0->scrapy) (0.4.8)
Requirement already satisfied: hyperlink>=17.1.1 in d:\python\python37\lib\site-packages (from Twisted[http2]>=17.9.0->scrapy) (21.0.0)
Requirement already satisfied: Automat>=0.8.0 in d:\python\python37\lib\site-packages (from Twisted[http2]>=17.9.0->scrapy) (20.2.0)
Requirement already satisfied: constantly>=15.1 in d:\python\python37\lib\site-packages (from Twisted[http2]>=17.9.0->scrapy) (15.1.0)
Requirement already satisfied: incremental>=16.10.1 in d:\python\python37\lib\site-packages (from Twisted[http2]>=17.9.0->scrapy) (21.3.0)
Requirement already satisfied: twisted-iocpsupport~=1.0.0 in d:\python\python37\lib\site-packages (from Twisted[http2]>=17.9.0->scrapy) (1.0.1)
Requirement already satisfied: priority<2.0,>=1.1.0 in d:\python\python37\lib\site-packages (from Twisted[http2]>=17.9.0->scrapy) (1.3.0)
Requirement already satisfied: setuptools in d:\python\python37\lib\site-packages (from zope.interface>=4.1.3->scrapy) (41.2.0)
Requirement already satisfied: pycparser in d:\python\python37\lib\site-packages (from cffi>=1.12->cryptography>=2.0->scrapy) (2.20)
Requirement already satisfied: idna>=2.5 in d:\python\python37\lib\site-packages (from hyperlink>=17.1.1->Twisted[http2]>=17.9.0->scrapy) (2.9)
Installing collected packages: scrapy
Successfully installed scrapy-2.5.1
创建一个项目
C:\Users\lifeng01>scrapy startproject tutorial
New Scrapy project 'tutorial', using template directory 'D:\Python\Python37\lib\site-packages\scrapy\templates\project', created in:C:\Users\lifeng01\tutorialYou can start your first spider with:cd tutorialscrapy genspider example example.com
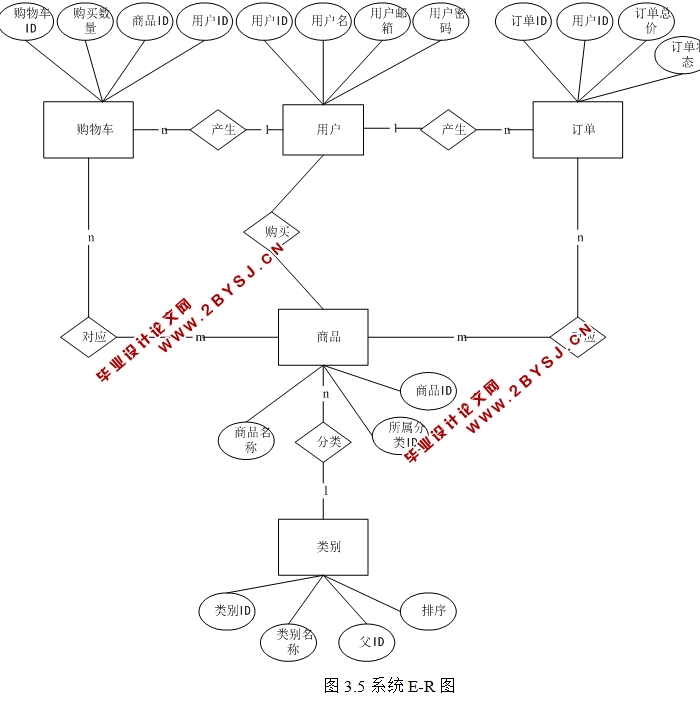
tutorial这个名称可自定义。最后创建的文件目录如下:
tutorial
│ scrapy.cfg
│
└─tutorial│ items.py│ middlewares.py│ pipelines.py│ settings.py│ __init__.py│ └─spiders__init__.py
- 新建主程序
D:\tutorial\tutorial\spiders>scrapy genspider basic www.baidu.com
Created spider 'basic' using template 'basic' in module:tutorial.spiders.basic
basic是自定义名称,www.baidu.com是指定的域名。最后创建的主程序如下:
import scrapyclass BasicSpider(scrapy.Spider):name = 'basic'allowed_domains = ['www.baidu.com']start_urls = ['http://www.baidu.com/']def parse(self, response):pass
开始编写爬虫
以上只是简单的介绍下安装和创建工程目录,具体细节的使用方法可参考官方文档。
scrap官方文档:https://docs.scrapy.org/en/latest/intro/install.html#supported-python-versions
- 以下是爬取某网站的美女图片,示例脚本如下:
properties\properties\spiders\basic.py主程序
import scrapy
from properties.items import PropertiesItemclass BasicSpider(scrapy.Spider):name = 'basic'allowed_domains = ['jandan.net/']start_urls = ['http://jandan.net/girl/MjAyMTEwMjUtOTk=#comments',]def parse(self, response):item = PropertiesItem()item['image_urls'] = response.xpath('//img//@src').extract()yield item
properties\properties\items.py为项目定义字段
import scrapyclass PropertiesItem(scrapy.Item):# define the fields for your item here like:image_urls = scrapy.Field()
properties\properties\settings.py设置配置项
# 处理媒体重定向,请将此设置设为True
MEDIA_ALLOW_REDIRECTS = True
# 存储路径
IMAGES_STORE = 'F:\project_gitee\Test\properties\image'
# 将目标存储设置配置为一个将用于存储下载的映像的有效值。否则,即使将管道包含在item_pipes设置中,它仍将被禁用。
ITEM_PIPELINES = {'properties.pipelines.PropertiesPipeline': 1,
}
properties\properties\pipelines.py处理返回数据
import os
import urllib.request
from properties import settings
from itemadapter import ItemAdapterclass PropertiesPipeline:def process_item(self, item, spider):DIR_PATH = os.path.join(settings.IMAGES_STORE, spider.name) # 存储路径if not os.path.exists(DIR_PATH):os.makedirs(DIR_PATH)for image_url in item['image_urls']:# 分割图片链接list_data = image_url.split('/')# 分割后,获取图片名称image_name = list_data[len(list_data)-1] # 图片名称# 判断图片名称是否存在if os.path.exists(image_name):continue# 利用urllib.request.urlopen库进行下载图片images = urllib.request.urlopen('http:'+image_url)# 根据路径,进行图片存储 with open(os.path.join(DIR_PATH, image_name),'wb') as w:w.write(images.read())return item
开始运行爬取数据
F:\project_gitee\Test\properties>scrapy crawl basic
2021-10-25 16:30:13 [scrapy.utils.log] INFO: Scrapy 2.5.1 started (bot: properties)
2021-10-25 16:30:13 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.2.0, Python 3.7.7 (tags/v3.7.7:d7c567b08f, Mar 10 2020, 10:41:24) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 20.0.1 (OpenSSL 1.1.1k 25 Mar 2021), cryptography 3.4.7, Platform Windows-10-10.0.18362-SP0
2021-10-25 16:30:13 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2021-10-25 16:30:13 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'properties','NEWSPIDER_MODULE': 'properties.spiders','ROBOTSTXT_OBEY': True,'SPIDER_MODULES': ['properties.spiders']}
2021-10-25 16:30:13 [scrapy.extensions.telnet] INFO: Telnet Password: 378683921570e9f2
2021-10-25 16:30:13 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats','scrapy.extensions.telnet.TelnetConsole','scrapy.extensions.logstats.LogStats']
2021-10-25 16:30:14 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware','scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware','scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware','scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware','scrapy.downloadermiddlewares.useragent.UserAgentMiddleware','scrapy.downloadermiddlewares.retry.RetryMiddleware','scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware','scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware','scrapy.downloadermiddlewares.redirect.RedirectMiddleware','scrapy.downloadermiddlewares.cookies.CookiesMiddleware','scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware','scrapy.downloadermiddlewares.stats.DownloaderStats']
2021-10-25 16:30:14 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware','scrapy.spidermiddlewares.offsite.OffsiteMiddleware','scrapy.spidermiddlewares.referer.RefererMiddleware','scrapy.spidermiddlewares.urllength.UrlLengthMiddleware','scrapy.spidermiddlewares.depth.DepthMiddleware']
2021-10-25 16:30:14 [scrapy.middleware] INFO: Enabled item pipelines:
['properties.pipelines.PropertiesPipeline']
2021-10-25 16:30:14 [scrapy.core.engine] INFO: Spider opened
2021-10-25 16:30:14 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2021-10-25 16:30:14 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-10-25 16:30:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://jandan.net/robots.txt> (referer: None)
2021-10-25 16:30:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://jandan.net/girl/MjAyMTEwMjUtOTk=#comments> (referer: None)
2021-10-25 16:30:17 [scrapy.core.scraper] DEBUG: Scraped from <200 http://jandan.net/girl/MjAyMTEwMjUtOTk=>
{'image_urls': ['//wx2.sinaimg.cn/mw600/0076BSS5ly8gvr79mpwbej60u00lx0vd02.jpg','//wx2.sinaimg.cn/mw600/0076BSS5ly8gvr73vsp3jj60u011iwk102.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvr6y1uf4oj60u011jjuy02.jpg','//wx1.sinaimg.cn/mw600/0076BSS5ly8gvr6lkv2fnj60u011e0vl02.jpg','//wx1.sinaimg.cn/mw2000/008dYDxugy1gvr3u9plfvj61kw1g0qlc02.jpg','//wx3.sinaimg.cn/mw2000/008dYDxugy1gvr3u8twb9j60tz12fwkq02.jpg','//wx4.sinaimg.cn/mw2000/008dYDxugy1gvr3u6f261j60u013n10z02.jpg','//wx2.sinaimg.cn/mw2000/008dYDxugy1gvr3u4xo03j60u0140qbq02.jpg','//wx2.sinaimg.cn/mw2000/008dYDxugy1gvr3u44ksaj60u0140wmq02.jpg','//wx2.sinaimg.cn/mw600/002iRMxrly1gvqvda2nwcj60ll0ss7am02.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvquam9sl3j60q10wj0wh02.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvqu54jb06j60go0p1my802.jpg','//wx1.sinaimg.cn/mw600/0076BSS5ly8gvqtz5oc7sj60u011cgon02.jpg','//wx1.sinaimg.cn/mw600/0076BSS5ly8gvqtskv7xrj60u0190acs02.jpg','//wx1.sinaimg.cn/mw600/0076BSS5ly8gvqtmlqesej60u0190dst02.jpg','//wx2.sinaimg.cn/mw600/002fU9sRly1gvqtkvuzbtj60rs15oq5y02.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvqtgft95xj60u011ijx802.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvqt9ybwmoj60u018z48002.jpg','//wx3.sinaimg.cn/mw600/0076BSS5ly8gvqsxu4gebj60u015xgu902.jpg','//wx3.sinaimg.cn/mw600/0076BSS5ly8gvqsrsi70gj61hc0u0jwf02.jpg','//wx3.sinaimg.cn/mw600/0076BSS5ly8gvqsltsprgj60u00gvn0802.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvqsftjou0j60jg0t677d02.jpg','//wx3.sinaimg.cn/mw600/0076BSS5ly8gvqs9tsmvaj60u01407bh02.jpg','//wx2.sinaimg.cn/mw600/0076BSS5ly8gvqs33sslqj60rs0ijmzv02.jpg','//wx3.sinaimg.cn/mw600/0076BSS5ly8gvqrw2tidoj60hs0qoq4p02.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvqrpx4tfaj61900u0qbd02.jpg','//wx4.sinaimg.cn/mw600/0076BSS5ly8gvqrka7219j60u011iwha02.jpg']}
2021-10-25 16:30:17 [scrapy.core.engine] INFO: Closing spider (finished)
2021-10-25 16:30:17 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 451,'downloader/request_count': 2,'downloader/request_method_count/GET': 2,'downloader/response_bytes': 14483,'downloader/response_count': 2,'downloader/response_status_count/200': 2,'elapsed_time_seconds': 3.762225,'finish_reason': 'finished','finish_time': datetime.datetime(2021, 10, 25, 8, 30, 17, 913551),'httpcompression/response_bytes': 92384,'httpcompression/response_count': 2,'item_scraped_count': 1,'log_count/DEBUG': 3,'log_count/INFO': 10,'response_received_count': 2,'robotstxt/request_count': 1,'robotstxt/response_count': 1,'robotstxt/response_status_count/200': 1,'scheduler/dequeued': 1,'scheduler/dequeued/memory': 1,'scheduler/enqueued': 1,'scheduler/enqueued/memory': 1,'start_time': datetime.datetime(2021, 10, 25, 8, 30, 14, 151326)}
2021-10-25 16:30:17 [scrapy.core.engine] INFO: Spider closed (finished)
运行后,image/basic文件下存入图片信息
image
│
└─basic002fU9sRly1gvqtkvuzbtj60rs15oq5y02.jpg002iRMxrly1gvqvda2nwcj60ll0ss7am02.jpg0076BSS5ly8gvqrka7219j60u011iwha02.jpg0076BSS5ly8gvqrpx4tfaj61900u0qbd02.jpg0076BSS5ly8gvqrw2tidoj60hs0qoq4p02.jpg0076BSS5ly8gvqs33sslqj60rs0ijmzv02.jpg0076BSS5ly8gvqs9tsmvaj60u01407bh02.jpg0076BSS5ly8gvqsftjou0j60jg0t677d02.jpg0076BSS5ly8gvqsltsprgj60u00gvn0802.jpg0076BSS5ly8gvqsrsi70gj61hc0u0jwf02.jpg0076BSS5ly8gvqsxu4gebj60u015xgu902.jpg0076BSS5ly8gvqt9ybwmoj60u018z48002.jpg0076BSS5ly8gvqtgft95xj60u011ijx802.jpg0076BSS5ly8gvqtmlqesej60u0190dst02.jpg0076BSS5ly8gvqtskv7xrj60u0190acs02.jpg0076BSS5ly8gvqtz5oc7sj60u011cgon02.jpg0076BSS5ly8gvqu54jb06j60go0p1my802.jpg0076BSS5ly8gvquam9sl3j60q10wj0wh02.jpg0076BSS5ly8gvr6lkv2fnj60u011e0vl02.jpg0076BSS5ly8gvr6y1uf4oj60u011jjuy02.jpg0076BSS5ly8gvr73vsp3jj60u011iwk102.jpg0076BSS5ly8gvr79mpwbej60u00lx0vd02.jpg008dYDxugy1gvr3u44ksaj60u0140wmq02.jpg008dYDxugy1gvr3u4xo03j60u0140qbq02.jpg008dYDxugy1gvr3u6f261j60u013n10z02.jpg008dYDxugy1gvr3u8twb9j60tz12fwkq02.jpg008dYDxugy1gvr3u9plfvj61kw1g0qlc02.jpg

以上总结或许能帮助到你,或许帮助不到你,但还是希望能帮助到你,如有疑问、歧义,直接私信留言会及时修正发布;非常期待你的点赞和分享哟,谢谢!
未完,待续…
一直都在努力,希望您也是!
微信搜索公众号:就用python