当你希望向用户提供满足其要求的相关数据时,相关性至关重要。这是任何企业的关键功能。吸引受众的一个好的营销策略是通过向他们提供他们正在搜索的内容来满足客户的需求。
糟糕的搜索可能会导致你平台上的流量明显减少。这是因为用户已经接受过培训,可以期待类似于 Google 搜索的结果,这并不容易获得,但是使用 Elasticsearch,你可以通过调整搜索结果的多个因素来实现它。
在 Elasticsearch 中评分
Elasticsearch 使用评分系统对显示给用户的查询结果进行过滤和排名。评分是基于与搜索查询和其他应用配置的字段匹配完成的,我们将在本文后面讨论。Elasticsearch 计算文档的分数并将其用作相关因素来对文档进行排序。分数越高意味着文档的相关性越高。查询中的每个子句都会影响文档的分数。
实用评分功能
由于 Elasticsearch 是基于 Lucene 库构建的,因此计算相关性分数时,Elasticsearch 使用 Lucene 的 Practical Scoring Function。这将布尔模型、词频 (TF)、逆文档频率 (IDF) 和向量空间模型用于多词查询,并将它们组合起来以组装匹配的文档并随时对它们进行评分。
例如,一个多词查询就像:
PUT /my_index/_doc/1
{"text": "The quick brown fox jumps over the lazy dog"
}GET /my_index/_search
{"query": {"match": {"text": "quick fox"}}
}上面的查询在内部被重写为:
GET /my_index/_search
{"query": {"bool": {"should": [{"term": { "text": "quick" }},{"term": { "text": "fox" }}]}}
}当文档与查询匹配时,Lucene 通过组合每个匹配词的得分来计算得分。 该评分计算由实际评分功能完成。
score(q,d) = queryNorm(q) · coord(q,d) · ∑ ( tf(t in d) · idf(t)² · t.getBoost() · norm(t,d) ) (t in q) 解释如下:
- score(q,d) 是文档 d 对查询 q 的相关性得分。
- queryNorm(q) 是查询规范化因子。
- coord(q,d) 是协调因子。
- 文档 d 的查询 q 中每个术语 t 的权重总和。
- tf(t in d) 是文档 d 中术语 t 的术语频率。
- idf(t) 是术语 t 的逆文档频率。
- t.getBoost() 是已应用于查询的提升。
- norm(t,d) 是字段长度范数,结合索引时间字段级提升(如果有)。
现在,让我们来熟悉构成实用评分函数的每个评分机制:
- 词频 (Term frequency - tf):查找词在文档字段中出现的次数并返回它的平方根:
tf = sqrt(termFreq)计算词频背后的想法是,词在文档中出现的时间越多,文档的相关性就越高。

- 逆文档频率 (Inverse document frequency - idf):
idf = 1 + ln(maxDocs/(docFreq + 1))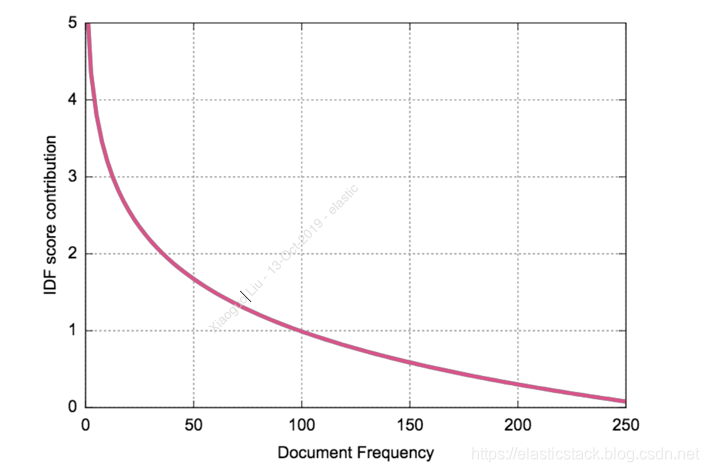
一个常见的术语,例如:“the”,几乎出现在所有文档中,应该被认为不如包含在较少文档中的其他术语重要。 这就是计算逆文档频率的原因。
- 协调(Coordination - coord):计算查询中出现在文档中的术语数。 使用协调机制,如果我们有 3 个术语查询并且文档包含其中 2 个术语,那么它的得分将高于只有其中 1 个术语的文档。
- 字段长度归一化(norm):这是字段中术语数的平方根的倒数
norm = 1/sqrt(numFieldTerms)对于字段长度归一化,包含较少数量的术语并且查询术语被认为比包含更多术语以及搜索术语的文档更相关的文档。
- Query normalization (queryNorm):这通常是查询中术语的平方权重之和。 这样做是为了比较不同的查询。
- Index boost:这是一个百分比或绝对数字,用于在索引时提升任何字段。 请注意,在实践中,索引提升与字段长度归一化相结合,以便在索引中仅存储一个数字; 但是,Elasticsearch 强烈建议不要使用索引级别的提升,因为这种机制会产生许多不利影响。
- Query boost:这是一个百分比或绝对数字,可用于在查询时提升任何查询子句。 查询提升允许我们指出查询的某些部分应该比其他部分更重要。
Explain API
现在我们知道了 elasticsearch 的实用评分功能是如何工作的。 在继续之前,让我们先谈谈我们将用于调试 Elasticsearch 中任何查询的分数的一个重要工具——“explain”。
为了说明问题方便,我们再追加一个文档:
PUT my_index/_doc/2
{"text": "a quick running horse"
}Explain API 返回有关特定文档为何匹配(或不匹配)查询的信息。 例如 :
GET my_index/_search?filter_path=**.hits
{"query": {"match": {"text": "quick"}},"explain": true,"fields": ["text"]
}上面的命令返回如下的结果:
{"hits" : {"hits" : [{"_shard" : "[my_index][0]","_node" : "ACcSMYOXRpSYHLYylHOg0g","_index" : "my_index","_id" : "2","_score" : 0.21636502,"_source" : {"text" : "a quick running horse"},"fields" : {"text" : ["a quick running horse"]},"_explanation" : {"value" : 0.21636502,"description" : "weight(text:quick in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.21636502,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.18232156,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 2,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.53941905,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 4.0,"description" : "dl, length of field", // ”text“ 字段的长度 a quick running horse, 共4个单词 "details" : [ ]},{"value" : 6.5,"description" : "avgdl, average length of field", // 两个文档的长度的平均值 (9+4)/2 = 6.5"details" : [ ]}]}]}]}},{"_shard" : "[my_index][0]","_node" : "ACcSMYOXRpSYHLYylHOg0g","_index" : "my_index","_id" : "1","_score" : 0.15753466,"_source" : {"text" : "The quick brown fox jumps over the lazy dog"},"fields" : {"text" : ["The quick brown fox jumps over the lazy dog"]},"_explanation" : {"value" : 0.15753466,"description" : "weight(text:quick in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.15753466,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.18232156,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 2,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.39274925,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 9.0,"description" : "dl, length of field","details" : [ ]},{"value" : 6.5,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}}]}
}如你所见,这是如何对查询的所有因素进行评分的详细视图。 因此,“explain”API 可以帮助了解文档是否与搜索查询匹配。
影响相关性的因素
现在让我们看看其他有助于我们调整相关性的因素。
Boosting
可以提升字段以提高相关性分数,从而在特定场景中获得最相关的文档。 考虑一个博客网站示例,你希望标题与搜索查询匹配,而不是正文与查询匹配。 对于这样的场景,提升领域可以发挥重要作用。
提升可以在索引时和查询时进行。 请参见下面的示例:
索引时间提升:
PUT blog-index
{"mappings": {"properties": {"title": {"type": "text","boost": 2 },"body": {"type": "text"}}}
}查询时间提升:
POST blog-index/_search
{"query": {"match": {"title": {"query": "quick brown fox","boost": 2}}}
}在这两种情况下,当查询与标题字段匹配时,分数将比正文字段的分数高一倍。
由于以下原因,通常不建议在索引时提升:
- 要更改索引时的提升值(boost value),需要重新索引所有文档,而你可以在查询时更改提升值以满足所需的相关性。
- 索引时提升作为归一化的一部分存储,只有一个字节。 这会降低字段长度归一化因子的分辨率,从而导致相关性计算质量降低。
同义词
在你希望多个单词在相同的上下文并搜索到相同的文档的情况下,设置同义词可能很有用。 例如,当用户搜索术语 [‘water’, ‘rain’, ‘ocean’ ] 时,你希望它们具有与查询结果相同的文档集,因为它们在你的案例中具有相同的含义。
与 boosting 类似,同义词可以在索引时或查询时完成。 让我们找出差异:
- 索引时同义词会产生更大的索引,因为必须对所有同义词进行索引,而查询时同义词对索引大小没有影响。
- 依赖于术语统计的搜索评分可能会受到影响,因为同义词也被计算在内,并且在索引时同义词期间不太常见单词的统计信息会出现偏差,但在查询时间,语料库中的术语统计信息保持不变。
- 针对索引时完成的同义词,如果需要改变同义词规则,我们需要重新索引(reindex),而查询时构建的情况就不需要。
![大型互联网网站架构心得[转]](https://images.cnblogs.com/cnblogs_com/lovecherry/asdh9awsdj.jpg)