文章目录
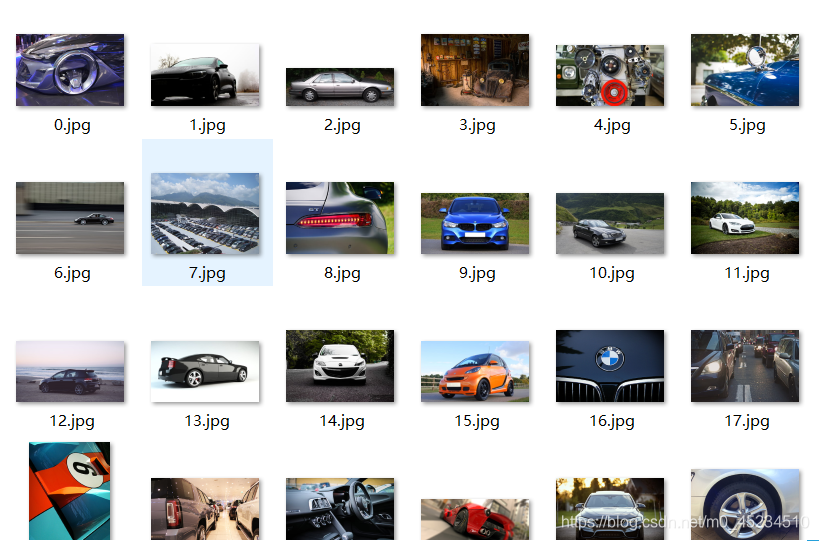
- 先看效果
- 1、环境准备
- 2、要爬取的网站
- 3、程序源代码(可直接运行)
先看效果

1、环境准备
import requests
import re
下载requests库:
pip install requests
2、要爬取的网站
https://www.hippopx.com
3、程序源代码(可直接运行)
E:\test 需要在E盘下准备一个test 文件夹,当然,也可以自己更改存储路径
import requests
import rekeyword = input("请输入中文关键字:")
baseurl = 'https://www.hippopx.com/zh/search?q='+ str(keyword) +'&page='
downpage = input("请输入页数:")
downpage = int(downpage) + 2picList = [] # 图片列表
pattern =[]
num = 0for i in range(2,downpage):url = baseurl + str(i)print(url)content = requests.get(url).content.decode('utf-8')pattern = re.compile('<link itemprop="thumbnail" href="(.+?)"').findall(content)# picList.append(pattern)picList = picList + patternprint(picList)
print(len(picList))# 下载图片
def dowmloadPicture():# 定义全局变量global numprint('找到的图片,即将开始下载图片...')for each in picList:print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))try:if each is not None:pic = requests.get(each, timeout=7)else:continueexcept BaseException:print('错误,当前图片无法下载')continueelse:# 保存路径string = 'E:\test\\' + str(num) + '.jpg'fp = open(string, 'wb')fp.write(pic.content)fp.close()num += 1# 调用下载图片方法
dowmloadPicture()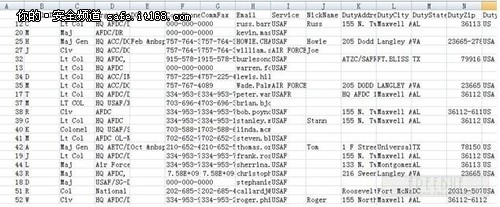





![[转]Asp.Net 网站多语言解决方案](https://images0.cnblogs.com/blog/105869/201301/23160602-e0927f513e9447a5b56ad0e436efe605.png)