鼎鼎大名的乌云网站,仅存在6年左右,就停摆,真是可惜。。。
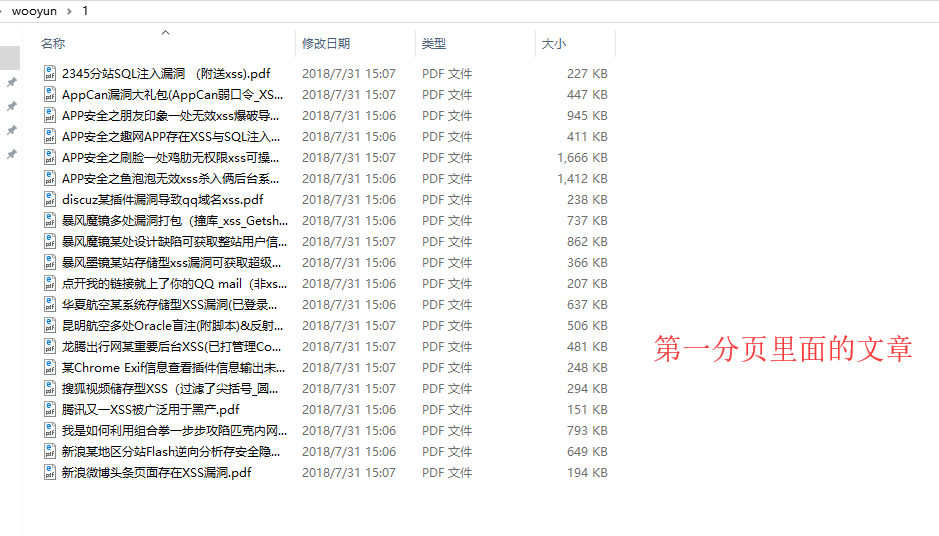
从某网站爬取所有公开的乌云漏洞文章,保存为pdf格式,以作纪念学习使用
首先创建一个文件夹wooyun,把下面代码保存为test.py,然后放在该文件夹
# -*- coding: utf-8 -*-
import urllib2
import pdfkit
from lxml import etree
import time
import random
import os
import shutildef modify_filename(file1,file2,filename,m):'''更改文件名函数如有多个同名文件,自动在文件名末尾加上数字,从2开始。方法递归'''if os.path.exists(file2):m += 1file2 = filename + str(m) + '.pdf'modify_filename(file1,file2,filename,m)else:os.rename(file1,file2)returndef main():'主函数:爬取所有乌云文章,以漏洞标题作为文件名'# 外循环控制页数for i in range(1,167):# 创建一个文件夹来存放该页所有文章,文件夹名字为分页数字os.mkdir(str(i))url = "http://xsspt.com/index.php?do=blist&page=" + str(i)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36','Cookie': '__cfduid=db29c8ab99daaf6824f89ff256974cc131532950162; bdshare_firstime=1532950162131; UM_distinctid=164eaf6ebae83c-0945623eb9d7ee-47e1039-1fa400-164eaf6ebaf67b; Hm_lvt_c12f88b5c1cd041a732dea597a5ec94c=1532950162,1532950477; CNZZDATA1260224584=5670'}req = urllib2.Request(url,headers=headers)res = urllib2.urlopen(req)# print(res.getcode())# print(res.url)html = res.read()content = etree.HTML(html)# 获取每页的文章链接列表links = content.xpath('//td/a/@href')n = 0# 遍历该分页里面的文章链接for each in links:each = 'http://xsspt.com' + eachreq2 = urllib2.Request(each,headers=headers)html2 = urllib2.urlopen(req2).read()content2 = etree.HTML(html2)# 获取文章章标题title = content2.xpath("//h3[@class='wybug_title']/text()")[0]# 设置保存的文件名,由于windows环境对文件名命名有'/'、'\'、'?'、'|'、'<'、'>'、'"'、'*'有限制,所以要有如下过滤filename = title[5:].strip().replace('/','_').replace('\\','_').replace('<','').replace('>','').replace('"','').replace('(','').replace(')','').replace('[','').replace(']','').replace('\\','').replace('%','').replace(';','').replace('*','').replace('?','').replace(':','').replace('|','')# file = filename + ".pdf"n += 1# 初始文件名file1 = str(n) + '.pdf'# 保存文件名file2 = filename + '.pdf'# 保存pdf文件到本地path_wk = r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'config = pdfkit.configuration(wkhtmltopdf = path_wk)pdfkit.from_url(each, file1, configuration=config)# m变量值用来区分同名文件m = 1# 由于文件名有重复,所以使用递归函数来处理,文件重名的,文件名末尾加递增数字保存。如a.pdf,a2.pdfmodify_filename(file1,file2,filename,m)time.sleep(random.randint(1,3))# 把当前分页里面的所有的文章文件移动到对应的分页文件里面for d in os.listdir('.'):if d.split('.')[-1] == 'pdf':shutil.move(d,str(i))if __name__ == '__main__':main()
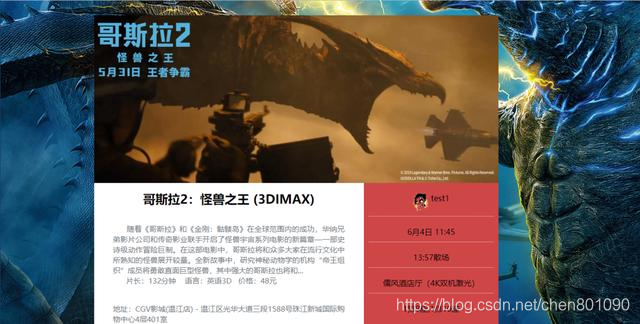
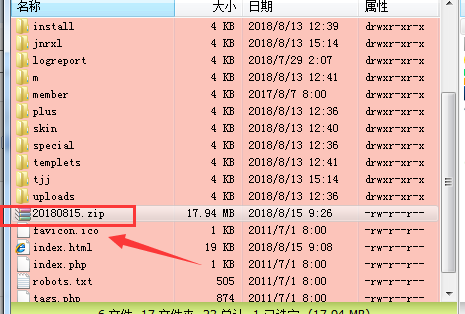
测试效果如下