前言:本文用到了窗口函数 range between,可以参考这篇博客进行了解——窗口函数rows between 、range between的使用
创建数据环境
在 MySQL 中创建数据测试表 log_data:
create table if not exists log_data(
log_id varchar(200) comment '日志id',
user_id varchar(200) comment '用户id',
log_time datetime NULL DEFAULT NULL comment '登录时间');
插入数据:
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('1', '2022-03-10 10:08:13', '1000');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('2', '2022-03-18 10:33:22', '1000');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('3', '2022-03-26 18:59:19', '1000');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('4', '2022-03-03 20:59:13', '1001');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('5', '2022-03-10 05:53:49', '1001');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('6', '2022-02-26 02:27:51', '1001');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('7', '2022-03-01 20:59:13', '1002');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('8', '2022-03-07 05:53:49', '1002');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('9', '2022-02-28 02:27:51', '1002');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('10', '2022-02-27 20:59:13', '1003');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('11', '2022-03-05 05:53:49', '1003');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('12', '2022-03-12 02:27:51', '1003');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('13', '2022-02-28 20:59:13', '1004');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('14', '2022-03-05 05:53:49', '1004');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('15', '2022-03-18 02:27:51', '1004');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('16', '2022-02-25 20:59:13', '1005');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('17', '2022-03-04 05:53:49', '1005');
insert into `log_data` (`log_id`, `log_time`, `user_id`) values ('18', '2022-03-11 02:27:51', '1005');
需求介绍
求 login_time 字段值为 2022-03-10 的最近连续三周登录的用户数,最终使用 Spark 中的 show 算子输出如下字段:
| 字段名 | 介绍 | 备注 |
|---|---|---|
| end_date | 数据统计日期 | 2022-03-10 |
| active_total | 活跃用户数 | |
| date_range | 统计周期 | 格式:统计开始时间_结束时间 |
需求分析
根据 login_time 字段值为 2022-03-10 的最近连续三周登录的用户数,想要完成这个需求,我们得先拿到最近三周的开始时间和结束时间,然后筛选范围数据,最后利用窗口函数计算其连续性。
- 确定当前
2022-03-10是周几,然后求得周日的日期(也就是这三周的最后一天)。 - 拿到
2022-03-10这周的周日时间后,获取两周前的开始日期(也就是这三周的第一天)。 - 筛选范围,计算每位用户是否符合三周的连续性。
需求实现
import org.apache.spark.sql.SparkSessionobject Get3WeekUserCnt {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("Get3WeekUserCnt").master("local[*]").getOrCreate()// 1.读取 MySQL 数据spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url","jdbc:mysql://master:3306/test").option("user","root").option("password","123456").option("dbtable","log_data").load().createTempView("data")// 2.获取 2022-03-10 这周的周日时间spark.sql("""|select| user_id,| log_time, | date_add("2022-03-10",if(pmod(datediff("2022-03-10","1970-01-01")-3,7)=0,0,7-pmod(datediff("2022-03-10","1970-01-01")-3,7))) date_end|from| data|""".stripMargin).createTempView("first_data")// 3.获取两周前的日期,筛选符合要求的数据spark.sql("""|select| *|from| (select| user_id,| date(log_time) log_date,| date_end,| date_sub(date_end,20) date_begin| from| first_data)t1|where| log_date <= date_end| and| log_date >= date_begin|""".stripMargin).createTempView("second_data")// 4.计算各个用户三周连续性spark.sql("""|select| end_date,| count(distinct user_id) active_total,| date_range|from| (select| "2022-03-10" end_date,| user_id,| concat(date_begin,"_",date_end) date_range,| count(user_id) over(partition by user_id order by unix_timestamp(log_date,"yyyy-MM-dd") range between current row and 6*3600*24 following) cnt_1week,| count(user_id) over(partition by user_id order by unix_timestamp(log_date,"yyyy-MM-dd") range between 7*3600*24 following and 13*3600*24 following) cnt_2week,| count(user_id) over(partition by user_id order by unix_timestamp(log_date,"yyyy-MM-dd") range between 14*3600*24 following and 20*3600*24 following) cnt_3week| from| second_data)t1|where| cnt_1week >= 1| and| cnt_2week >= 1| and| cnt_3week >= 1|group by| end_date,| date_range|""".stripMargin).show()spark.stop()}}
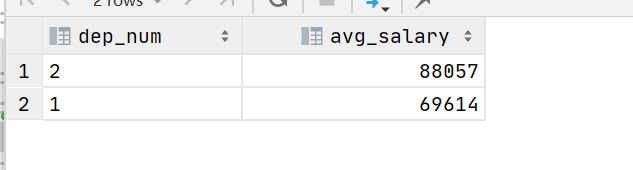
输出结果如下:
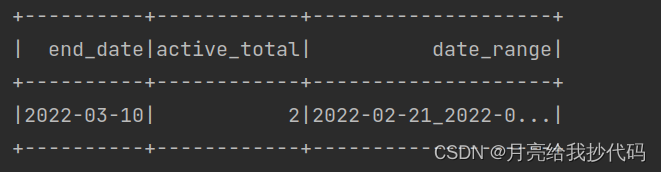
结果验证:
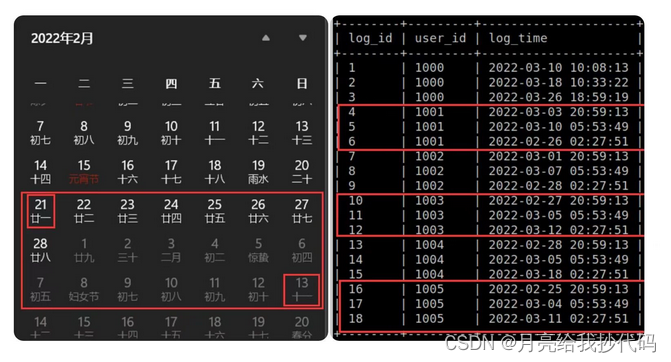
输出结果有误!
通过对日历与日期进行对比,我们可以发现,实际上一共有3位用户满足连续登录三个月的请求。那么这是什么原因呢?首先,我们主要来看一下日期计算的这部分代码:
count(user_id) over(partition by user_id order by unix_timestamp(log_date,"yyyy-MM-dd") range between current row and 6*3600*24 following) cnt_1week,count(user_id) over(partition by user_id order by unix_timestamp(log_date,"yyyy-MM-dd") range between 7*3600*24 following and 13*3600*24 following) cnt_2week,count(user_id) over(partition by user_id order by unix_timestamp(log_date,"yyyy-MM-dd") range between 14*3600*24 following and 20*3600*24 following) cnt_3week
其中,第一行 cnt_1week 统计的是各个用户第一周登录的次数,后面两行以此类推。我们将用户 1001 代入其中,很快就发现了问题,如下:
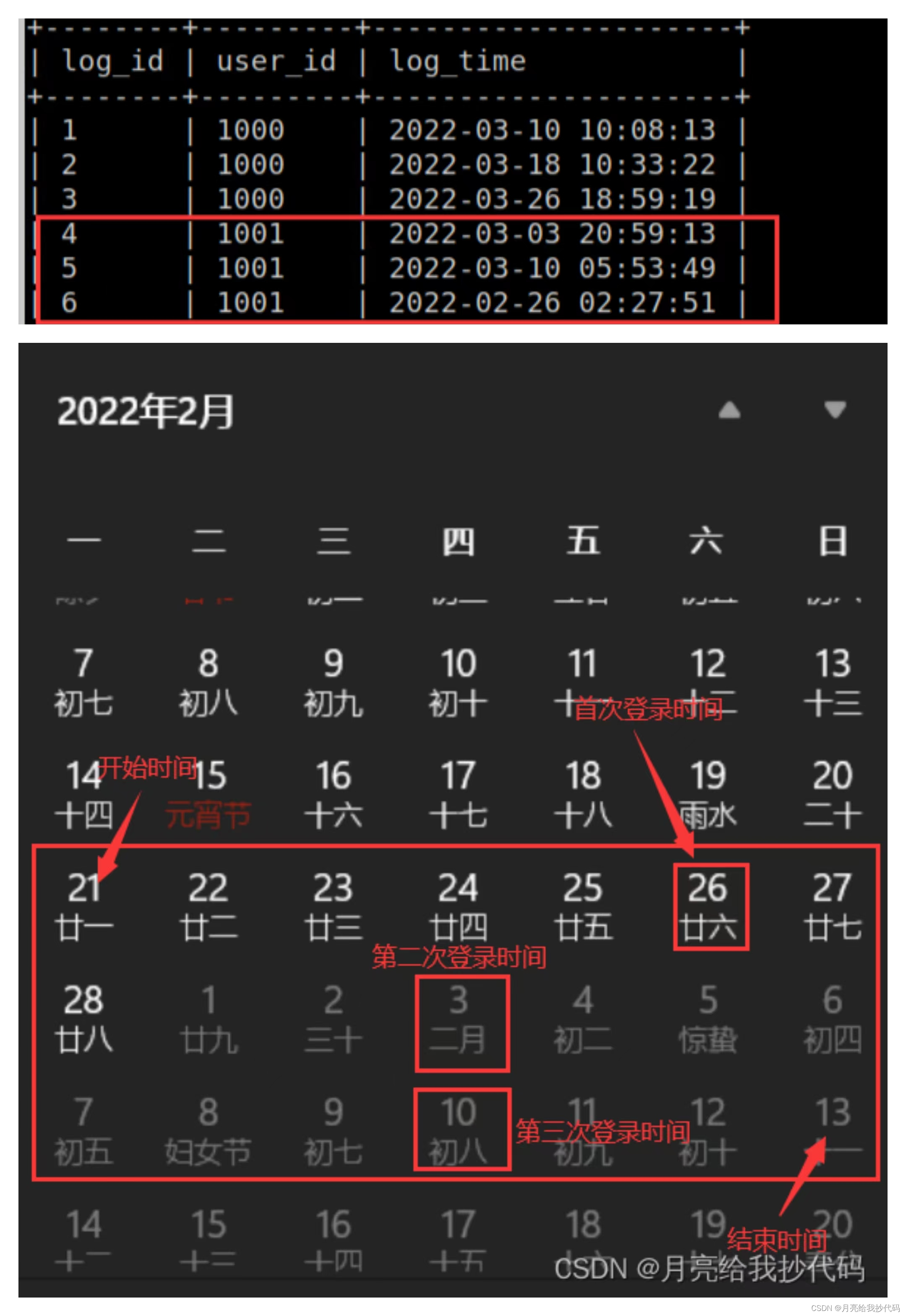
我们设置的时间跨度为一周,但是没有考虑到该日期为本周的第几天。通过用户 1001 可以看出,如果是这样算的话,就相当于我们把每个日期都当成了每周的第一天。就比如我们这里将 26 号作为了第一天,而六天后,也就是3月4号,变成了这周的最后一天。它将2.26号——3.4号作为了一个自然周。很明显,我们这样计算是错误的。
解决方法也很简单,我们可以通过一个字段来记录每个用户登录日期的那一周的周天日期,然后在日期计算的时候将该字段作为计算的考量日期。
修改后代码如下:
import org.apache.spark.sql.SparkSessionobject Get3WeekUserCnt {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("Get3WeekUserCnt").master("local[*]").getOrCreate()// 1.读取 MySQL 数据spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url","jdbc:mysql://master:3306/test").option("user","root").option("password","123456").option("dbtable","log_data").load().createTempView("data")// 2.获取 2022-03-10 这周的周日时间spark.sql("""|select| user_id,| date(log_time) log_date,| date_add("2022-03-10",if(pmod(datediff("2022-03-10","1970-01-01")-3,7)=0,0,7-pmod(datediff("2022-03-10","1970-01-01")-3,7))) date_end|from| data|""".stripMargin).createTempView("first_data")// 3.获取两周前的日期与当前日期周天的日期,筛选符合要求的数据spark.sql("""|select| *|from| (select| user_id,| date_add(log_date,if(pmod(datediff(log_date,"1970-01-01")-3,7)=0,0,7-pmod(datediff(log_date,"1970-01-01")-3,7))) log_week_end_date,| date_end,| date_sub(date_end,20) date_begin| from| first_data)t1|where| log_date <= date_end| and| log_date >= date_begin|""".stripMargin).createTempView("second_data")// 4.计算各个用户三周连续性spark.sql("""|select| end_date,| count(distinct user_id) active_total,| date_range|from| (select| "2022-03-10" end_date,| user_id,| concat(date_begin,"_",date_end) date_range,| count(user_id) over(partition by user_id order by unix_timestamp(log_week_end_date,"yyyy-MM-dd") range between 6*3600*24 preceding and current row) cnt_1week,| count(user_id) over(partition by user_id order by unix_timestamp(log_week_end_date,"yyyy-MM-dd") range between 1*3600*24 following and 7*3600*24 following) cnt_2week,| count(user_id) over(partition by user_id order by unix_timestamp(log_week_end_date,"yyyy-MM-dd") range between 8*3600*24 following and 14*3600*24 following) cnt_3week| from| second_data)t1|where| cnt_1week >= 1| and| cnt_2week >= 1| and| cnt_3week >= 1|group by| end_date,| date_range|""".stripMargin).show()spark.stop()}}
注意,最后统计数量的时候不要忘记对用户的 ID 进行去重!
输出结果如下:
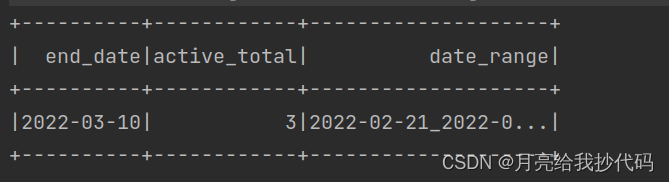
Bingo~