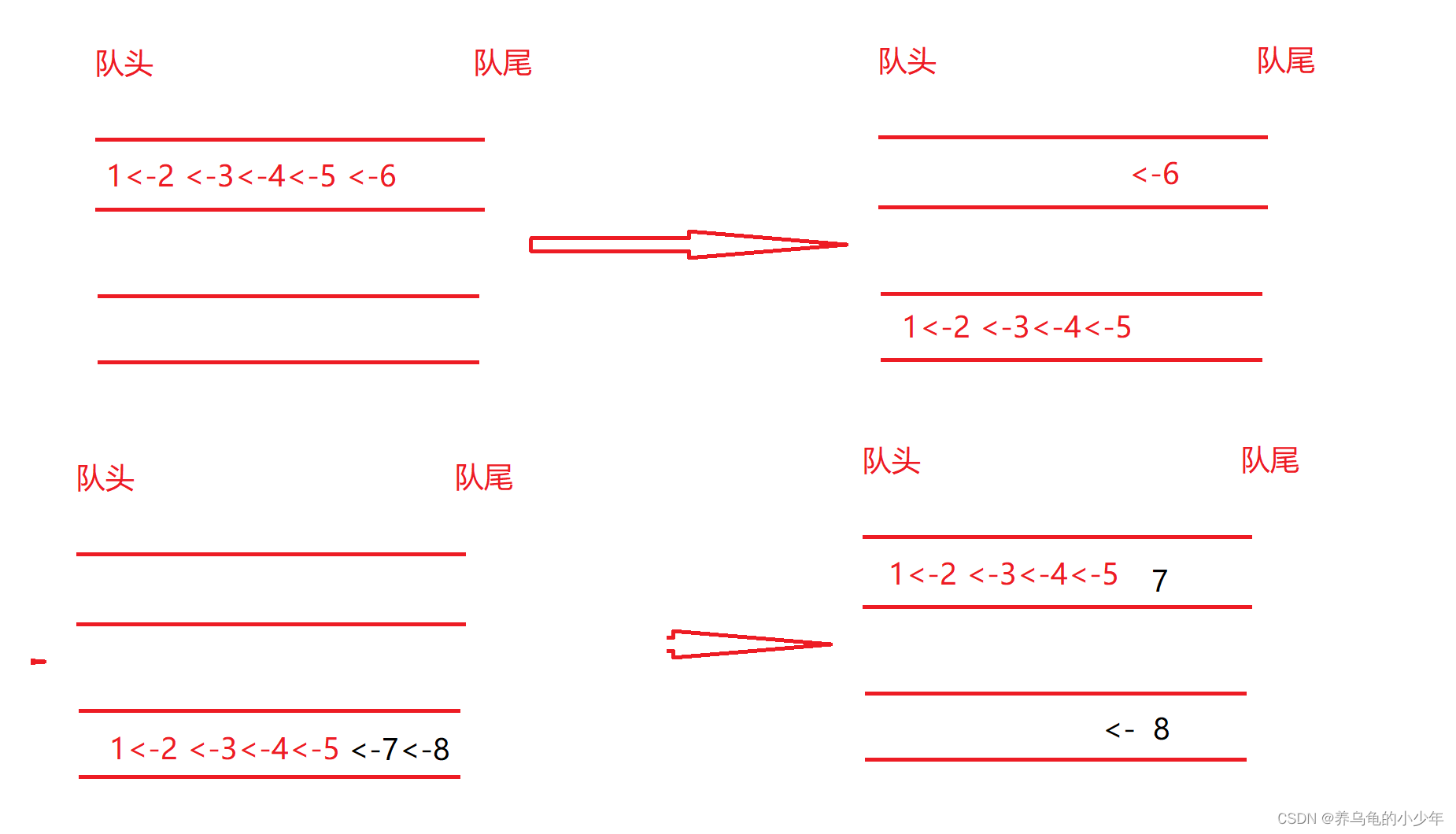
装饰器扩展点
- org.apache.shardingsphere.underlying.route.decorator.RouteDecorator
- org.apache.shardingsphere.underlying.rewrite.context.SQLRewriteContextDecorator
- org.apache.shardingsphere.underlying.merge.engine.decorator.ResultDecoratorEngine
- org.apache.shardingsphere.underlying.merge.engine.merger.ResultMergerEngine
SQL重写装饰器SQLRewriteContextDecorator主要作用是在真正的改写发生前,根据执行SQL的DML类型做一些预处理:
- 如果SQL语句是查询语句且分页查询参数不为空,构建分页参数下标对应的具体参数值映射;
- 如果SQL语句是插入语句且使用ShardingSphere的唯一键生成策略,构建每条插入语句对应的唯一键值映射;
- 构建SQL重写所需的SQLToken生成器。
通过以上三步,可以将SQL重写所需要的Token准备好。因此,如果需要对SQL做一些特殊处理,如SQL改写可以通过在该装饰器中增加自定义SQLToken生成器来实现。
SQLToken 生成器
每个SQL执行都会创建一个ShardingTokenGenerateBuilder来获取SQLTokenGenerator
public void decorate(final ShardingRule shardingRule, final ConfigurationProperties properties, final SQLRewriteContext sqlRewriteContext) {/**省略1,2步*/// 关键代码,获取Token生成器sqlRewriteContext.addSQLTokenGenerators(new ShardingTokenGenerateBuilder(shardingRule, routeContext).getSQLTokenGenerators());
}
ShardingSphere默认内置了多个Token生成器,根据不同的DML语句类型执行不同的SQLTokenGenerator
/**内置Token生成器*/
private Collection<SQLTokenGenerator> buildSQLTokenGenerators() {Collection<SQLTokenGenerator> result = new LinkedList<>();addSQLTokenGenerator(result, new TableTokenGenerator());addSQLTokenGenerator(result, new DistinctProjectionPrefixTokenGenerator());addSQLTokenGenerator(result, new ProjectionsTokenGenerator());addSQLTokenGenerator(result, new OrderByTokenGenerator());addSQLTokenGenerator(result, new AggregationDistinctTokenGenerator());addSQLTokenGenerator(result, new IndexTokenGenerator());addSQLTokenGenerator(result, new OffsetTokenGenerator());addSQLTokenGenerator(result, new RowCountTokenGenerator());addSQLTokenGenerator(result, new GeneratedKeyInsertColumnTokenGenerator());addSQLTokenGenerator(result, new GeneratedKeyForUseDefaultInsertColumnsTokenGenerator());addSQLTokenGenerator(result, new GeneratedKeyAssignmentTokenGenerator());addSQLTokenGenerator(result, new ShardingInsertValuesTokenGenerator());addSQLTokenGenerator(result, new GeneratedKeyInsertValuesTokenGenerator());return result;
}
应用
在业务应用中,有些场景的数据不允许物理删除,只能通过逻辑删除,即在数据表中添加与业务无关的字段来标记该条数据是否已删除。为了避免每次写SQL语句都要带上业务无关的标记字段,可以通过配置+SQL改写的方式,自动在已配置表的执行SQL语句中加入标记字段。
SQL 改写
通过源码分析,SQL语句改写主要依赖SQLTokenGenerator,我们可以通过自定义自己的SQLToken生成器来达到SQL改写的目的。
自定义SQLToken生成器
通过ShardingSphere自带的Token接口OptionalSQLTokenGenerator实现自定义Token生成器,由于在插入语句和查询语句中插入字段的方式是不一样的(插入语句字段之前用逗号分隔,查询语句where条件后用and分隔),
所以即使插入一个字段也需要实现多个Token生成器,下面以简单的查询语句类型为例
@Override
public boolean isGenerateSQLToken(SQLStatementContext sqlStatementContext) {// 检查是否需要插入标记字段,校验是否是查询语句,不是查询则跳过走下个Token生成器// 省略......// 获取逻辑表名,表名不存在不继续执行// 省略......// 判断白名单,可通过白名单配置哪些表不需要加该标记字段// 省略......// 获取自定义的标记字段信息TagField info = SQLTagUtil.getTagField(logicTableName);// 校验 where 条件是否已存在该标记字段,存在则不继续添加SelectStatement statement = (SelectStatement)sqlStatementContext.getSqlStatement();return SQLTagUtil.checkAddTagField(statement.getWhere().get(), info);
}@Override
public SQLToken generateSQLToken(SelectStatementContext sqlStatementContext) {// 获标记字段配置信息TagField info = SQLTagUtil.getTagField(logicTableName);// 获取 where 条件,在最后追加自定义字段Optional<WhereSegment> sqlSegment = sqlStatementContext.getSqlStatement().getWhere();Preconditions.checkState(sqlSegment.isPresent());// 根据之前SQL解析结果,计算插入下标索引,生成自定义Tokenreturn new CustomQueryColumnToken(sqlSegment.get().getStopIndex() + 1, SQLTagUtil.getSql(info));
}
自定义SQLToken
在上面自定义的SQLToken生成器中,我们自定义了CustomQueryColumnToken,该Token是可以拼接在where条件之后的
public final class CustomQueryColumnToken extends SQLToken implements Attachable {private final String column;public CustomQueryColumnToken(final int startIndex, final String column) {super(startIndex);this.column = column;}@Overridepublic String toString() {// 关键位置,主要拼接 and 语句return String.format(" and %s", column);}
}
追加SQLToken生成器
在自定义完Token生成器后,我们可以将该生成器追加到buildSQLTokenGenerators的后面,形如
/**内置Token生成器*/
private Collection<SQLTokenGenerator> buildSQLTokenGenerators() {Collection<SQLTokenGenerator> result = new LinkedList<>();// 省略部分生成器addSQLTokenGenerator(result, new ShardingInsertValuesTokenGenerator());addSQLTokenGenerator(result, new GeneratedKeyInsertValuesTokenGenerator());// 追加自定义的SQLToken生成器addSQLTokenGenerator(result, new TagFieldQueryColumnTokenGenerator());addSQLTokenGenerator(result, new TagFieldUpdateColumnTokenGenerator());addSQLTokenGenerator(result, new TagFieldInsertColumnTokenGenerator());addSQLTokenGenerator(result, new TagFieldInsertValuesTokenGenerator());return result;
}
到这里,我们已经将要插入的字段包装为一个自定义Token,接下来来,SQL改写引擎会去遍历SQLToken生成器获取具体的字段信息,并完成最终的SQL改写流程。
改进
本例中只添加一个字段,就需要在buildSQLTokenGenerators方法内追加4个自定义SQLToken生成器。如果是在SQL改写时,添加两个字段甚至更多的字段,需要不停的改动buildSQLTokenGenerators方法,违反了开闭原则。为了提高扩展性,我们定义了一个MySQLTokenGenerateHook来增加扩展SQLToken生成器
public interface MySQLTokenGenerateHook {/*** 自定义扩展生成器** @return 扩展 TOKEN 生成器*/LinkedList<SQLTokenGenerator> extendGenerators();
}
将buildSQLTokenGenerators方法修改为以下形式
private final Collection<MySQLTokenGenerateHook> tokenGenerateHooks = NewInstanceServiceLoader.newServiceInstances(MySQLTokenGenerateHook.class);
static {NewInstanceServiceLoader.register(MySQLTokenGenerateHook.class);
}private Collection<SQLTokenGenerator> buildSQLTokenGenerators() {Collection<SQLTokenGenerator> result = new LinkedList<>();// 省略默认生成器// 添加扩展生成器tokenGenerateHooks.forEach(hook -> hook.extendGenerators().forEach(ext -> addSQLTokenGenerator(result, ext)));return result;
}
每个扩展点实现里只需要将各自字段的SQLToken生成器创建并返回即可。
注意:每一个SQL执行上下文中都需要创建新的SQLToken生成器,多线程共用SQLToken生成器会导致线程安全问题,引起SQL改写语句错乱。
ResultDecoratorEngine与ResultMergerEngine主要是对查询的结构进行装饰合并。如进行分页排序查询,需要将多个表中查出的数据按照指定的排序维度进行合并返回最终的分页数据,由于没有对这两个装饰器进行过多的应用,因此不对这两个装饰器进行展开分析。