2019独角兽企业重金招聘Python工程师标准>>> 
在很多博客系统中,做SEO 都需要涉及到内链,下面主要介绍使用java替换部分关键字(怎样中文分词,有空再写写)的代码。
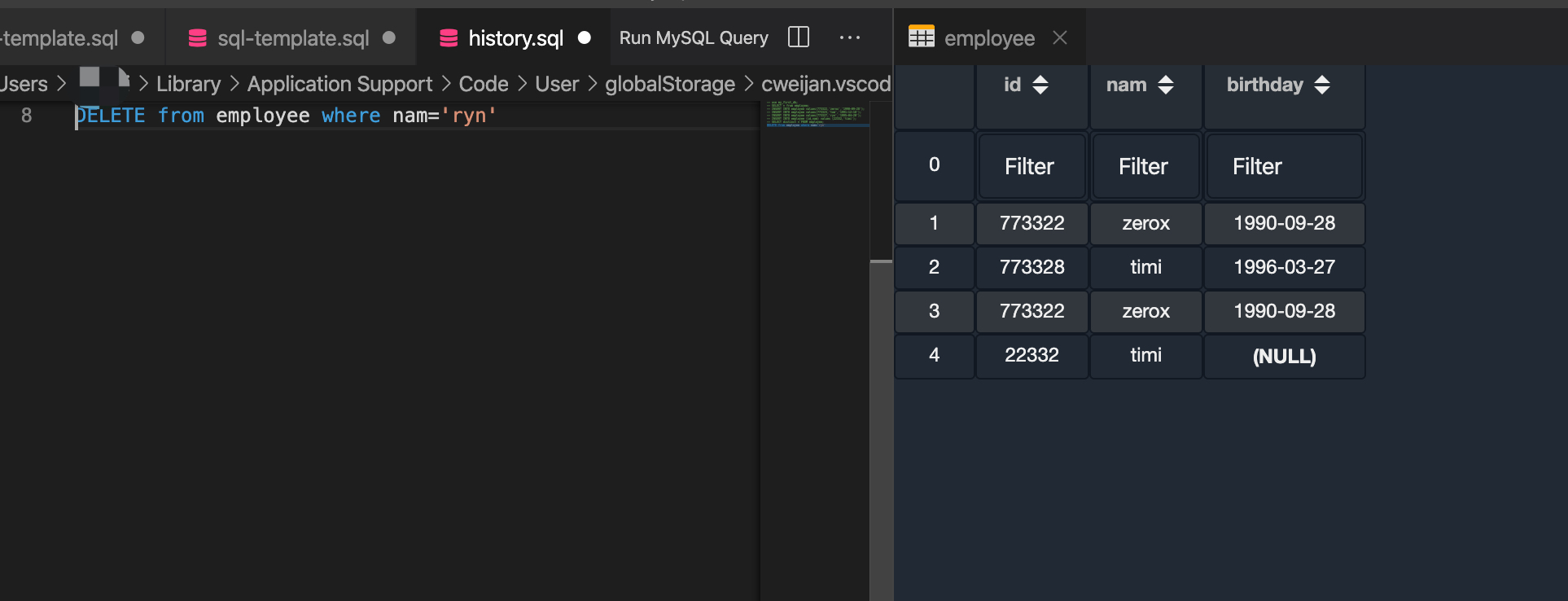
SEO 内链,把富文本原文:
//原文 假设 建筑为关键字String source = "<p alt='建筑设计'>建筑很美,建筑很烂" +"<br/>"+"建筑很美,<a href=\"http://www.baidu.com/建筑\" title='优秀的建筑'>优秀的建筑</a>" +"建筑人,建筑社区" +"<img src='http://www.baidu.com/建筑' alt='优秀的建筑'></img>" +"</p>" +"<p>" +"<a href='http://www.baidu.com/建筑' title='优秀的建筑'>优秀的建筑</a>" +"<img src='http://www.baidu.com/建筑' alt='优秀的建筑'></img>" +"建筑很美,建筑很烂</p><a>baidu建筑真的不错</a>";
转换成我们希望的目标:
//目标String target = "<p alt='建筑设计'><a>建筑</a>很美,<a>建筑</a>很烂" +"<br/>" +"<a>建筑</a>很美,<a href=\"http://www.mahoooo.com/建筑\" title='优秀的建筑'>优秀的建筑</a>" +"<a>建筑</a>人,<a>建筑</a>社区" +"<img src='http://www.mahoooo.com/建筑' alt='优秀的建筑'></img>" +"</p><p>" +"<a href='http://www.mahoooo.com/建筑' title='优秀的建筑'>优秀的建筑</a>" +"<img src='http://www.mahoooo.com/建筑' alt='优秀的建筑'></img>" +"<a>建筑</a>很美,<a>建筑</a>很烂</p><a>mahoooo建筑真的不错</a>";
通过原文和想要得到的目标比对,可以总结出:
1. 不想替换掉html 标签里面的文字,例如: src='http://www.baidu.com/建筑', alt='建筑设计'
2. 不希望替换掉<a href='http://www.baidu.com/建筑' title='的建筑'>优秀的建筑</a> text中的内容,既:优秀的建筑
通过上述分析(经过多种正则表达式测试,各种弯路,尝试过使用jsoup等工具类,中文分词保持<a>标签等方法):
public static void main(String[] args) {
// String regex = "(?=(<a.*?>(.*?)</a>))";//原文String source = "<p alt='建筑设计'>建筑很美,建筑很烂" +"<br/>"+"建筑很美,<a href=\"http://www.baidu.com/建筑\" title='优秀的建筑'>优秀的建筑</a>" +"建筑人,建筑社区" +"<img src='http://www.baidu.com/建筑' alt='优秀的建筑'></img>" +"</p>" +"<p>" +"<a href='http://www.baidu.com/建筑' title='优秀的建筑'>优秀的建筑</a>" +"<img src='http://www.baidu.com/建筑' alt='优秀的建筑'></img>" +"建筑很美,建筑很烂</p><a>baidu建筑真的不错</a>";//目标String target = "<p alt='建筑设计'><a>建筑</a>很美,<a>建筑</a>很烂" +"<br/>" +"<a>建筑</a>很美,<a href=\"http://www.mahoooo.com/建筑\" title='优秀的建筑'>优秀的建筑</a>" +"<a>建筑</a>人,<a>建筑</a>社区" +"<img src='http://www.mahoooo.com/建筑' alt='优秀的建筑'></img>" +"</p><p>" +"<a href='http://www.mahoooo.com/建筑' title='优秀的建筑'>优秀的建筑</a>" +"<img src='http://www.mahoooo.com/建筑' alt='优秀的建筑'></img>" +"<a>建筑</a>很美,<a>建筑</a>很烂</p><a>mahoooo建筑真的不错</a>";// String regex = "<[^a].*?>.*?<";//主要考虑html标签里面的属性 value值不能替换,和<a>标签text()不能替换,// 例如:匹配 src="***" 和 <a href=''>建筑<//之后就排除匹配段,其他都可以替换关键字String regex = "([\\w]+(='.*?'))|([\\w]+(=\".*?\"))|(<a.*?>.*?<)";Pattern p = Pattern.compile(regex);// 获取 matcher 对象Matcher m = p.matcher(source);//保存结果StringBuffer result = new StringBuffer();//上一个结束位置int lastEnd = 0;//是否匹配while (m.find()) {System.out.println("text:" + m.group());System.out.println("start: " + m.start() + "end:" + m.end());//提取没有匹配段,替换关键字并拼接result.append(source.substring(lastEnd,m.start()).replaceAll("建筑", "<a>建筑</a>"));//拼接匹配段result.append(source.substring(m.start(), m.end()));//作为下一个未匹配段的开始下标lastEnd = m.end();}//最后未匹配段result.append(source.substring(lastEnd).replaceAll("建筑", "<a>建筑</a>"));System.out.println("result:" + result.toString());}