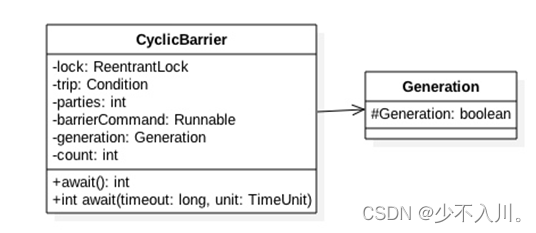
Pandas数据结构
Series
-
一维数据,一行或一列
-
Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
-
有数据列就可以生成Series
# 有数据列就可以产生Series s1 = pd.Series([1, 'a', 5.2, 7]) # 左侧为索引 右侧为数据 print(s1) print(s1.index) print(s1.values)
0 1
1 a
2 5.2
3 7
dtype: object
RangeIndex(start=0, stop=4, step=1)
[1 ‘a’ 5.2 7]
-
创建一个具有标签索引的Series
# 创建特定的索引 s2 = pd.Series([1, 'a', 5.2, 7], index=['a', 'b', 'c', 'd']) print(s2) print(s2.index)
a 1
b a
c 5.2
d 7
dtype: object
Index([‘a’, ‘b’, ‘c’, ‘d’], dtype=‘object’)
- 使用python字典创建Series
# 使用字典创建Series
sdata = {'DX': 12, 'WY': 15}
s3 = pd.Series(sdata)
print(s3)
DX 12
WY 15
dtype: int64
- 根据标签索引查询数据
sdata = {'DX': 12, 'WY': 15}
s3 = pd.Series(sdata)
print(s3['DX'])
print(type(s3['WY']))
12
<class ‘numpy.int64’>
DataFrame
-
二维数据,整个表格,多行多列。
-
df.columns:多列
-
df.index:多行
-
-
DataFrame是一个表格型的数据结构
-
每列可以是不同的值类型(数值、字符串、布尔值等)
-
既有行索引index,也有列索引columns
-
可以被看做由Series组成的字典
-
-
创建dataframe最常用的方式是,读取纯文本文件、excel、mysql数据库
-
根据多个字典序列创建dataframe
data = {'Ceng': ['DX', 'WY', 'CS'],'Day': ['2010', '2012', '2018'],'Weilai': ['变瘦', '变帅', '有钱']
}
df = pd.DataFrame(data)
print(df)
print(df.dtypes)
print(df.columns)
print(df.index)
Ceng Day Weilai
0 DX 2010 变瘦
1 WY 2012 变帅
2 CS 2018 有钱
Ceng object
Day object
Weilai object
dtype: object
Index([‘Ceng’, ‘Day’, ‘Weilai’], dtype=‘object’)
RangeIndex(start=0, stop=3, step=1)
- 查询多列,返回一个DataFrame(两层中括号)
print(df[['Ceng', 'Weilai']])
print(type(df[['Ceng', 'Weilai']]))
Ceng Weilai
0 DX 变瘦
1 WY 变帅
2 CS 有钱
<class ‘pandas.core.frame.DataFrame’>
-
查询行,一行返回Series,多行返回DataFrame
-
使用loc函数
- 通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)
-
使用iloc函数
- 通过行号来取行数据(如取第二行的数据)
-
print(df.loc[1])
print(type(df.loc[1]))print(df.loc[1:2])
print(type(df.loc[1:2]))
Ceng WY
Day 2012
Weilai 变帅
Name: 1, dtype: object
<class ‘pandas.core.series.Series’>
Ceng Day Weilai
1 WY 2012 变帅
2 CS 2018 有钱
<class ‘pandas.core.frame.DataFrame’>

![[数据结构]:05-循环队列(链表)(C语言实现)](https://img-blog.csdnimg.cn/a63177dcd6974290a3eaa455362d19a4.png)