2019独角兽企业重金招聘Python工程师标准>>> 
利用Beautifulsoup爬取知名笑话网站
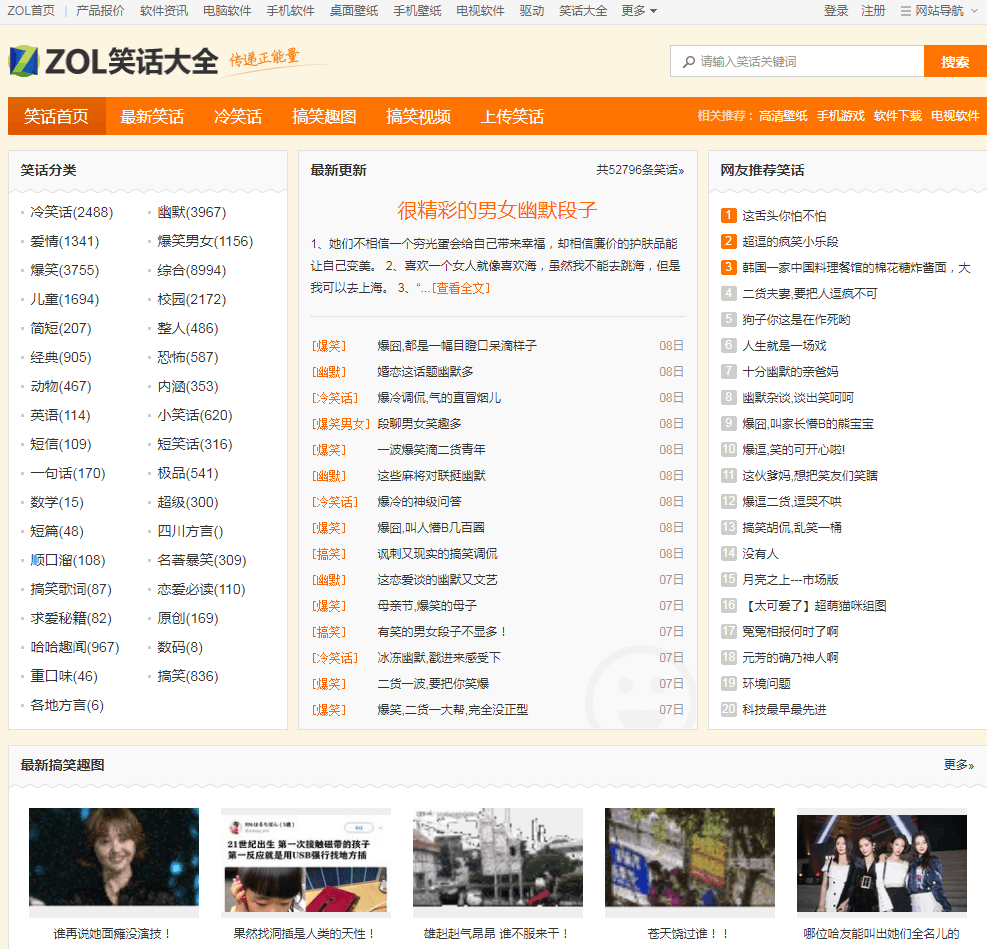
首先我们来看看需要爬取的网站:http://xiaohua.zol.com.cn/
1.开始前准备
1.1 python3,本篇博客内容采用python3来写,如果电脑上没有安装python3请先安装python3.
1.2 Request库,urllib的升级版本打包了全部功能并简化了使用方法。下载方法:
pip install requests1.3 Beautifulsoup库, 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.。下载方法:
pip install beautifulsoup41.4 LXML,用于辅助Beautifulsoup库解析网页。(如果你不用anaconda,你会发现这个包在Windows下pip安装报错)下载方法:
pip install lxml1.5 pycharm,一款功能强大的pythonIDE工具。下载官方版本后,使用license sever免费使用(同系列产品类似),具体参照http://www.cnblogs.com/hanggegege/p/6763329.html。
2.爬取过程演示与分析
from bs4 import BeautifulSoup
import os
import requests导入需要的库,os库用来后期储存爬取内容。
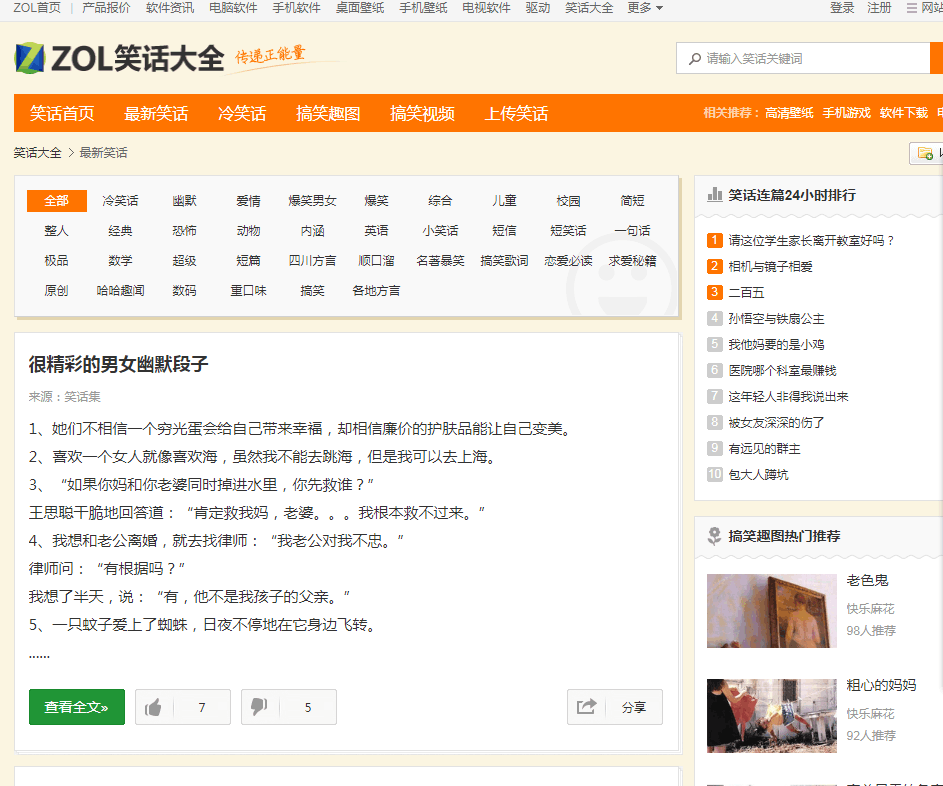
随后我们点开“最新笑话”,发现有“全部笑话”这一栏,能够让我们最大效率地爬取所有历史笑话!
我们来通过requests库来看看这个页面的源代码:
from bs4 import BeautifulSoup
import os
import requests
all_url = 'http://xiaohua.zol.com.cn/new/
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
all_html=requests.get(all_url,headers = headers)
print(all_html.text)header是请求头,大部分网站没有这个请求头会爬取失败
部分效果如下:
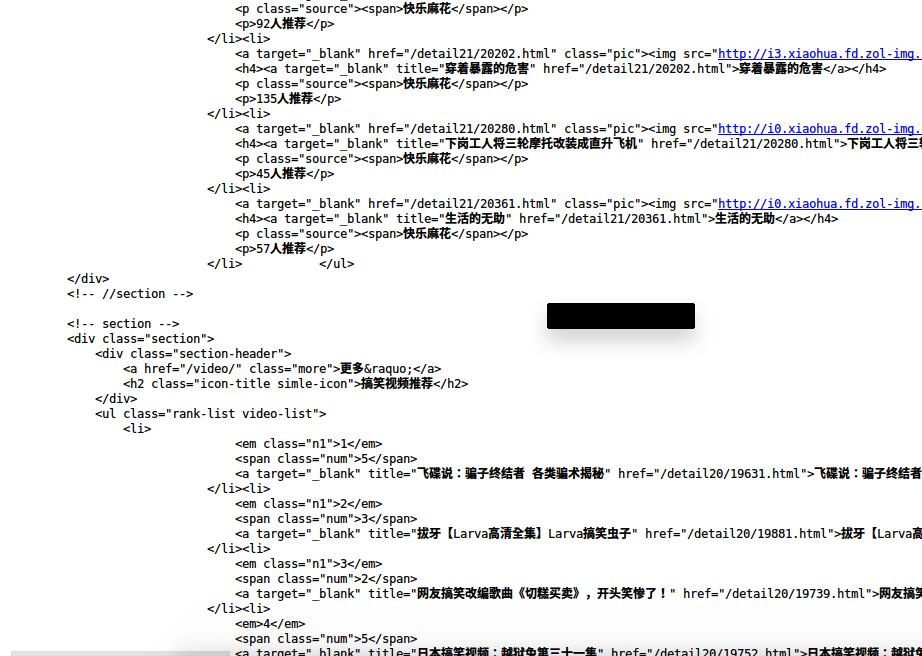
通过源码分析发现我们还是不能通过此网站就直接获取到所有笑话的信息,因此我们在在这个页面找一些间接的方法。
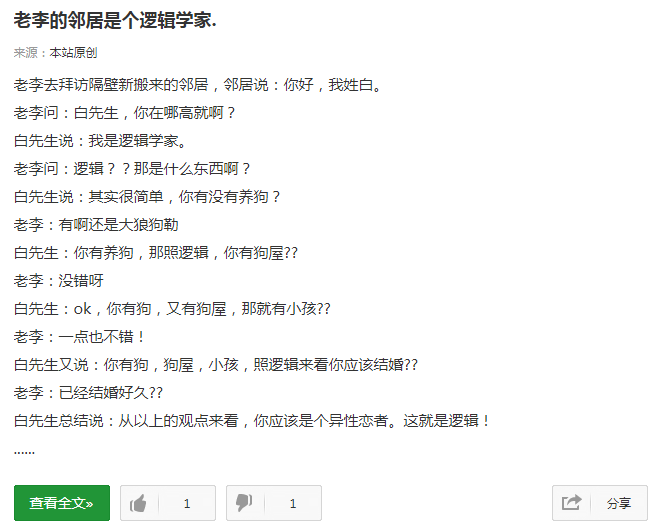
点开一个笑话查看全文,我们发现此时网址变成了http://xiaohua.zol.com.cn/detail58/57681.html,在点开其他的笑话,我们发现网址部都是形如http://xiaohua.zol.com.cn/detail?/?.html的格式,我们以这个为突破口,去爬取所有的内容
我们的目的是找到所有形如http://xiaohua.zol.com.cn/detail?/?.html的网址,再去爬取其内容。
我们在“全部笑话”页面随便翻到一页:http://xiaohua.zol.com.cn/new/5.html ,按下F12查看其源代码,按照其布局发现 :
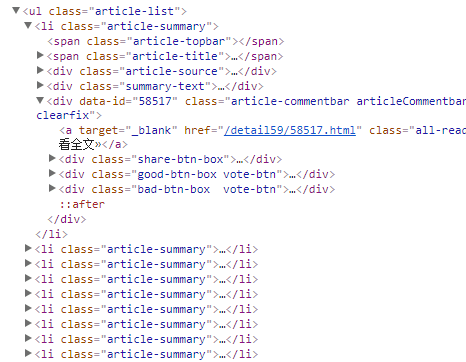
每个笑话对应其中一个
-
标签,分析得每个笑话展开全文的网址藏在href当中,我们只需要获取href就能得到笑话的网址
from bs4 import BeautifulSoup import os import requests RootUrl = 'http://xiaohua.zol.com.cn/new/' headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} RootCode=requests.get(RootUrl,headers = headers) #print(RootCode.text) Soup = BeautifulSoup(RootCode.text,'lxml') SoupList=Soup.find_all('li',class_ = 'article-summary') for i in SoupList:#print(i)SubSoup = BeautifulSoup(i.prettify(),'lxml')list2=SubSoup.find_all('a',target = '_blank',class_='all-read')for b in list2:href = b['href']print(href)我们通过以上代码,成功获得第一页所有笑话的网址后缀:
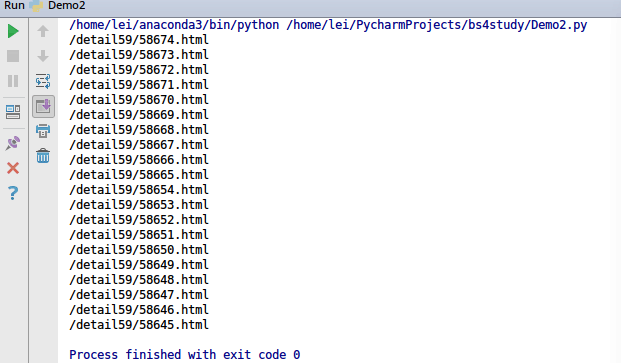
也就是说,我们只需要获得所有的循环遍历所有的页码,就能获得所有的笑话。
上面的代码优化后:
from bs4 import BeautifulSoup import requests import osRootUrl = 'http://xiaohua.zol.com.cn/new/' headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} RootCode=requests.get(RootUrl,headers = headers)def GetJokeUrl():JokeUrlList = []Soup = BeautifulSoup(RootCode.text,'lxml')SoupList=Soup.find_all('span',class_ = 'article-title')for i in SoupList:SubSoup = BeautifulSoup(i.prettify(),'lxml')JokeUrlList.append("http://xiaohua.zol.com.cn/"+str(SubSoup.a['href']))return JokeUrlList简单分析笑话页面html内容后,接下来获取一个页面全部笑话的内容:
-
from bs4 import BeautifulSoup import requests import osRootUrl = 'http://xiaohua.zol.com.cn/new/' headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} RootCode=requests.get(RootUrl,headers = headers)def GetJokeUrl():JokeUrlList = []Soup = BeautifulSoup(RootCode.text,'lxml')SoupList=Soup.find_all('span',class_ = 'article-title')for i in SoupList:SubSoup = BeautifulSoup(i.prettify(),'lxml')JokeUrlList.append("http://xiaohua.zol.com.cn/"+str(SubSoup.a['href']))return JokeUrlListdef GetJokeText(url):HtmlCode = requests.get(url,headers=headers) #don not forgetSoup = BeautifulSoup(HtmlCode.text,'lxml')Content = Soup.find_all('p')for p in Content:print(p.text)def main():JokeUrlList = GetJokeUrl()for url in JokeUrlList:GetJokeText(url)if __name__ == "__main__":main()效果图如下:

-
大功告成!