今天的任务是爬取外文网站所有pdf链接:
今天的程序不同的是我写了两个程序,其实可以写在一起的,但是两个好理解,首先我拿到所有详情页的链接,保存到数据库,然后去数据库拿出来一条一条访问详情页得到想要的内容
网站链接如下:https://ntrs.nasa.gov/search.jsp?N=4294129243
获取的内容有点多,大部分只要详情页有的都要,
获取所有链接代码如下:
import pymysql
import pymongo
import requests
from urllib.parse import urlencode
from lxml import etree
import hashlib
from multiprocessing.pool import Pool
from requests import codes
import lxml
import re
from bs4 import BeautifulSoup
def get_html(url):
try:
r = requests.get(url)
if codes.ok == r.status_code:
return r.text
except requests.ConnectionError:
return None
def get_urls(html):
soup = BeautifulSoup(html, 'lxml')
a = soup.find_all('form')
b = a[1].find_all('tr')
for i in b:
urls = i.find_all('a')
url_2 = urls[0]['href']
url_3 = 'https://ntrs.nasa.gov/' + url_2
# print(url_3)
md5 = md5Encode(url_1=url_3)
result = {
'md5': md5,
'url': url_3,
'state': 0
}
save_to_mongo(result)
def save_to_mongo(result):
client = pymongo.MongoClient('localhost', connect=False)
db = client['day6']
try:
# 加个判断, 如果插入数据失败,再次循环
if db['day6_tb'].insert(result):
print("insert into mongo success", result)
# 查询当前存储的数据条数
print('当前已存储%d条数据' % db.day6_tb.find().count())
return True
else:
print('插入失败')
return False
except:
print('md5重复')
def md5Encode(url_1):
# 创建md5对象
m = hashlib.md5()
# 传入需要加密的字符串
m.update(url_1.encode("utf8"))
# 返回加密之后的字符串
return m.hexdigest()
def main():
for i in range(3655, 27311):
page = i * 10
params = {
'No=': page
}
q = urlencode(params).replace('%3D', '')
base_url = 'https://ntrs.nasa.gov/search.jsp?N=4294129243&'
# print(base_url)
url = base_url + q
print(url)
html = get_html(url=url)
m = get_urls(html)
if __name__ == '__main__':
# main()
pool = Pool(10)
for i in range(20):
pool.apply_async(main)
pool.close()
pool.join()
获得所有详情页内容代码如下:
# 导入相关模块
import pymongo
import pymysql
from requests import codes
import requests
import hashlib
from multiprocessing.pool import Pool
import datetime
import lxml
import re
from lxml import etree
from bs4 import BeautifulSoup
# 打开数据库连接
db2 = pymysql.connect(host="192.168.8.212", user="sa", password="123456", db="Search")
# 使用cursor()方法获取操作游标
cursor = db2.cursor()
# 创建表
sql = '''
CREATE TABLE IF NOT EXISTS Day6(
id VARCHAR (20) NOT NULL,
title NVARCHAR (4000) NOT NULL,
author NVARCHAR (4000) NOT NULL,
patent number VARCHAR (100) NOT NULL,
page VARCHAR (100) NOT NULL,
abstract NVARCHAR (max) NOT NULL,
researchDirection NVARCHAR (4000) NOT NULL,
data NVARCHAR (25) NOT NULL,
url VARCHAR (255) NOT NULL,
md5 VARCHAR (255) NOT NULL
)
'''
client = pymongo.MongoClient('localhost', 27017)
db = client['day6']
table = db['day6_tb']
def get_html(url):
try:
r = requests.get(url)
if codes.ok == r.status_code:
return r.text
except requests.ConnectionError:
return None
def md5_Encode(url_1):
# 创建md5对象
m = hashlib.md5()
# 传入需要加密的字符串
m.update(url_1.encode("utf8"))
# 返回加密之后的字符串
# print('pppppp')
return m.hexdigest()
def download_url():
while 1:
data = table.find_one_and_update({"state": 0}, {"$set": {"state": 1}}) # 替换MongoDB中的第一个匹配的数据
# 此函数匹配第一个参数,若存在,则用第二个替换,若无匹配则反回None
if not data:
# 如果替换则表示已下载,not None为True,跳出循环
return
data["state"] = 1
url = data["url"]
# print(url)
html = get_html(url=url)
# print(html)
content = etree.HTML(html)
try:
# 标题加作者
titles = content.xpath('//table[@id="doctable"]//tr[1]//text()')
# print(titles)
# print(titles[0])
# 标题
# title = (titles[0],)
title = (titles[0])
# print(title)
# 作者 作者单位
# author = (titles[1],)
author = (titles[1])
# print(author)
# pdf链接
pdfs = content.xpath('//table[@id="doctable"]//a/@href')
pdf = pdfs[0]
# print((pdfs[0],))
# 抽象
abstract = content.xpath('//td[contains(text(),"Abstract:")]/following-sibling::td/text()')
abstract = abstract[0].strip()
# print((abstract,))
# 发布日期
data = content.xpath('//td[contains(text(),"Publication Date:")]/following-sibling::td/text()')
data = data[0].strip()
# print((data,))
# 文件编号
number = content.xpath('//td[contains(text(),"Document ID:")]/following-sibling::td/div/text()')
number = number[0].strip()
# print((number,))
# 学科类别
researchDirection = content.xpath('//td[contains(text(),"Subject Category:")]/following-sibling::td/text()')
researchDirection = researchDirection[0].strip()
# print((researchDirection,))
# 专利号
number_2 = content.xpath('//td[contains(text(),"Report/Patent Number:")]/following-sibling::td/text()')
number_2 = number_2[0].strip()
# print((number_2,))
# 页码
page = content.xpath('//td[contains(text(),"Description:")]/following-sibling::td/text()')
# print(page[0])
b = str(page[0])
# c = (b.split(';')[0].strip(),)
c = (b.split(';')[0].strip())
# print(c)
md5 = md5_Encode(pdf)
# print('111', md5)
result = {
'url': pdfs[0],
'md5': md5,
'num': number,
'title': title,
'patent number': number_2,
'author': author,
'page': c,
'summary': abstract,
'researchDirection': researchDirection,
'data': data
}
table = 'Day6'
keys = ','.join(result.keys())
values = ','.join(['%s'] * len(result))
sql = "INSERT INTO {table}({keys}) VAULES ({vaules})".format(table=table, keys=keys, values=values)
# sql = "insert into Day6(id,title,author,patent,number,page,abstract,researchDirection,data,url,md5) values ('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')"
try:
if cursor.execute(sql, tuple(result.values())):
print('储存成功')
db2.commit()
# cursor.execute(sql, (id,title,author,patent,number,page,abstract,researchDirection,data,url,md5))
# db.commit()
except:
print('储存失败')
db2.rollback()
db2.close()
except Exception as e:
print(e)
pass
if __name__ == '__main__':
pool = Pool(10)
for i in range(20):
pool.apply_async(download_url)
pool.close()
pool.join()
# 4一般代表电脑核数
# p = Pool(4)
# for i in range(5):
# p.apply_async(download_url, args=(i,))
# p.close()
# p.join()
# download_url()
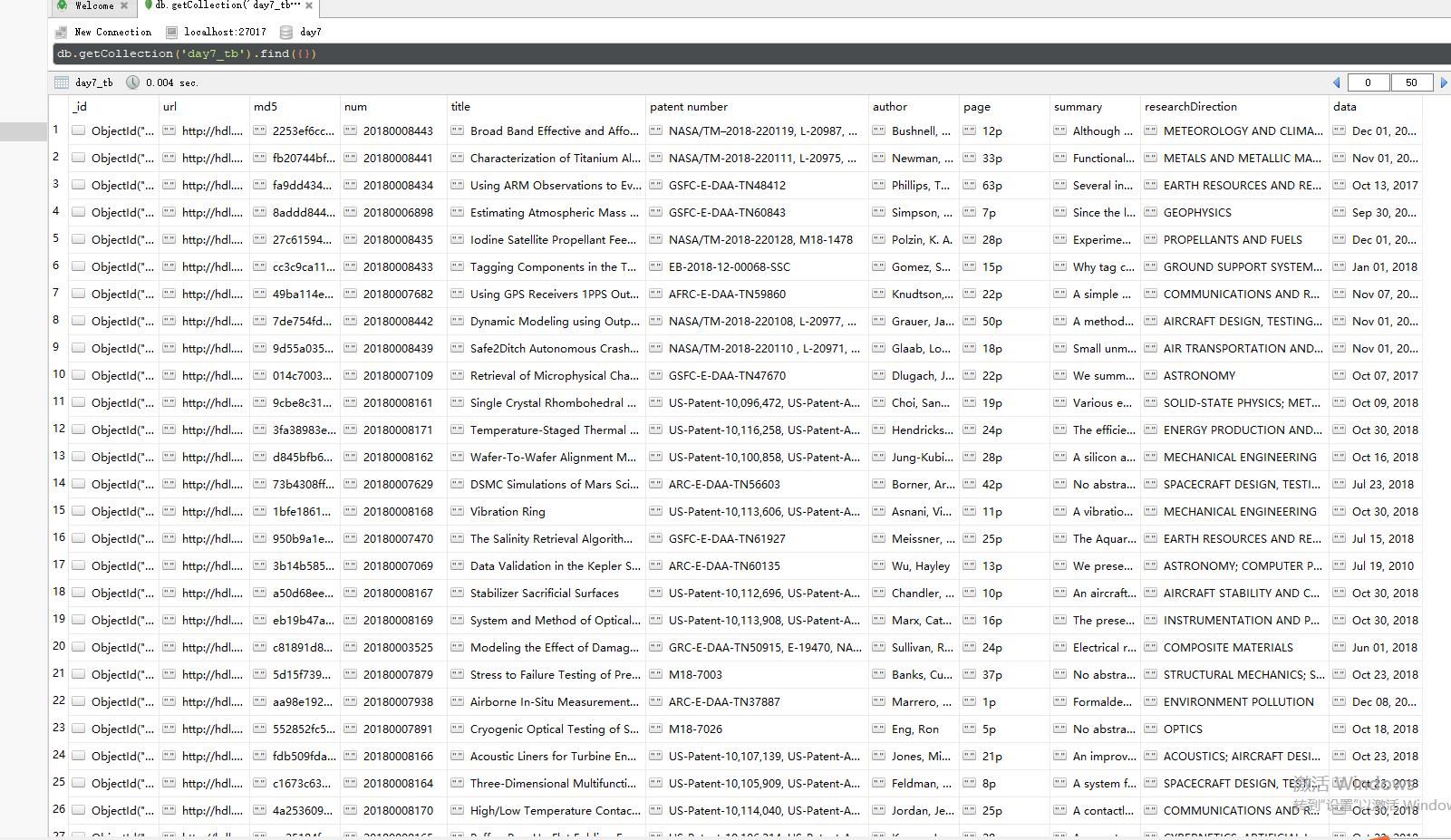
数据库内容如下,因为公司要求储存到MySQL数据库,但是现在连接不上,所以储存到MongoDB看一下: