原创:青空酱合天智汇
原创投稿活动:
http://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s/Nw2VDyvCpPt_GG5YKTQuUQ
---你可曾听过社工库的传说?
声明:本文介绍的安全工具仅用于渗透测试及安全教学使用,禁止任何非法用途
0x00 序言:
咳咳,这里是青空酱。本次为大家带来《手把手教你建立私人数据检索库》系列第二讲之数据的清洗导入与配置。对之前教程还不熟悉的读者可以查看上期文章以流畅的食用本文。
往期文章回顾
:http://mp.weixin.qq.com/s?__biz=MjM5MTYxNjQxOA==&mid=2652851659&idx=1&sn=7e2f574ab9dbbd3c2ae58b9c81e986d4&chksm=bd5931068a2eb810113d07da86e8e391caa60ad4e7171f2d522a9501d2698dbc6b7f71d9c0af&scene=21#wechat_redirect
言归正传,本讲分为几个以下部分:
- sphinx相关配置文件的介绍讲解
- 数据的导入,清洗与维护
- 索引生成实操及测试索引
请各位系好安全带,青空酱要发车啦!
最后还请大家持续关注本教程(毕竟我也不是什么鸽子)
0x01 Sphinx配置讲解:
上回我们讲到了sphinx的安装配置,接下来将在这里讲解下相关配置文件。
首先,使用sphinx查询数据的流程如下:
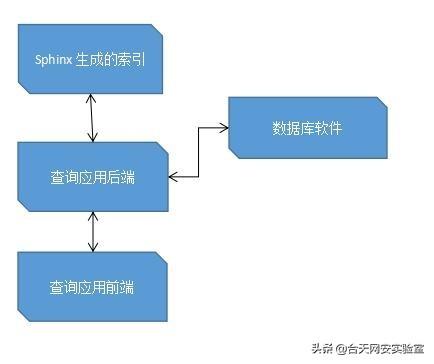
- Sphinx事先生成数据库的全文索引(将索引与数据的id一一对应)
- 后端向Sphinx监听服务发送查询关键字获取相关索引记录,即对应的数据库数据id
- 后端取得数据id后再向数据库发送查询请求获取信息
- 后端将信息返回前端渲染
大致流程介绍完了相比大家对于整个查询过程有了更深一层的理解,也方便进行进一步的讲解。
先放个官方的查询模板方便讲解,随后放本次搭建所用的模板。
索引模板:
source sphinx
{
type = mysql
sql_host = 192.168.1.1
sql_user = test 数据源连接信息
sql_pass = test
sql_db = sphinx //数据库名字
sql_port = 3306 //数据库库端口号
sql_query_pre = SET NAMES utf8 //设置连接字符集
sql_query = SELECT id, title, post_id, user_id,UNIX_TIMESTAMP(dated) as dateline
FROM test //最重要的部分嗷
sql_attr_uint = post_id
sql_attr_uint = user_id
sql_attr_timestamp = dateline 属性字段
}
index sphinx_idx //索引名
{
source = sphinx //这里与上面的source对应
path = /usr/local/coreseek-3.2.14/ var/data/sphinx //索引要存放的位置
docinfo = extern
charset_type = zh_cn.utf-8
charset_dictpath = /usr/local/coreseek-3.2.14/dict/ //字符集文件存放位置
html_strip = 0
}
indexer
{
mem_limit = 512M //用来构建索引的索引器运行所占用的内存
}
searchd
{
port = 9351 //不要被占用哦 netstat -anop|grep 9351 查询服务监听的端口
log = /usr/local/coreseek-3.2.14/ var/log/search_sphinx.log
query_log = /usr/local/coreseek-3.2.14/ var/log/query_sphinx.log //相关日志的存放位置
read_timeout = 5
max_children = 30
pid_file = /usr/local/coreseek-3.2.14/ var/searchd_sphinx.pid
max_matches = 10000 //返回的最大数据量
seamless_rotate = 1
preopen_indexes = 0
unlink_old = 1
}
......
有点懵? 先介绍这几个概念:
- source:数据源,数据是从什么地方来的。如Postgresql或Mysql
- index:索引,当有数据源之后,从数据源处构建索引。索引实际上就是相当于一个 缓存字典。有了整本字典内容以后,才会有字典检索。
- searchd:提供搜索查询服务进程。它一般是以deamon的形式运行在后台的。
- indexer:构建索引的服务。当要重新构建索引的时候,就是调用indexer这个服务。
- attr:属性,属性是存在索引中的,它不进行全文索引,但是可以用于过滤和排序。
Sphinx集轻量化与高拓展性与一体,相关配置可研究的东西很多,这里贴一下配置文件全解析,有兴趣的读者下去自行研究。
https://www.cnblogs.com/yjf512/p/3598332.html
贴下我自己的配置:
source data1
{
type = mysql
sql_host = localhost
sql_user = user
sql_pass = password
sql_db = sgk
sql_port = 3306
sql_query_pre = SET NAMES utf8
sql_query = SELECT `id`,`username`, `email` FROM data1 #sql_query第一列id需为整数,username、password、email等作为字符串/文本字段,被全文索引
sql_attr_uint = id #从SQL读取到的值必须为整数
#sql_field_string = username
#sql_field_string = password
#sql_field_string = email
#sql_attr_timestamp = date_added #从SQL读取到的值必须为整数,作为时间属性
sql_query_info = SELECT `id`, `username`, `password`, `email`, `salt` FROM data1 WHERE id=$id #命令行查询时,从数据库读取原始数据信息
}
#index定义
index data1
{
source = data1 #对应的source名称
path = /usr/local/sphinx/var/data/data1 #请修改为实际使用的绝对路径,例如:/usr/local/sphinx/var/...
docinfo = extern
mlock = 0
morphology = none
min_word_len = 1
ondisk_dict = 1 #索引不载入内存而是保存在硬盘上
#这个选项很重要 一定要把索引保存在硬盘,否则索引出的海量数据会充满整个内存
html_strip = 1
}
#全局index定义
indexer
{
mem_limit = 754M
}
#searchd服务定义
searchd
{
listen = 9312
read_timeout = 5
max_children = 30
max_matches = 1000
seamless_rotate = 0
preopen_indexes = 0
unlink_old = 1
pid_file = /usr/local/sphinx/var/log/searchd_mysql.pid #请修改为实际使用的绝对路径,例如:/usr/local/sphinx/var/...
log =/usr/local/sphinx/var/log/searchd_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/sphinx/var/...
query_log = /usr/local/sphinx/var/log/query_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/sphinx/var/...
binlog_path = #关闭binlog日志
}
0x02 数据导入,清洗与维护:
本教程以Mysql数据源为例。
首先创建数据库:
Create database sgk;


接着创建表:
数据库的表结构如下:
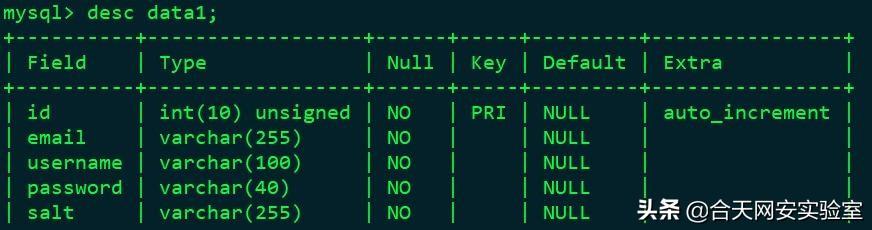
其实还可以加上一个’from’字段,用于记录数据的泄露来源,这里我没有设置。
表的字段主要为id,email,username,password,salt等,id即为数据对应编号,email为邮箱,username用户名,password为对应密码,salt一般为空,存在salt时可以写入。
注意:id的类型一定要写到unsigned或大整数等,因为数据量上去了可能会有数亿条。这里还有个坑之后会讲。而其他字段的类型最好设置为VARCHAR,毕竟数据中可能会有一些奇奇怪怪的字符。
先创建一个表data1,后续可能会有data2,data3...依数据量定。
创建命令
CREATE TABLE IF NOT EXISTS `data1`(
`id` INT UNSIGNED AUTO_INCREMENT,
`email` VARCHAR(255) NOT NULL,
`username` VARCHAR(100) NOT NULL,
`password` VARCHAR(40) NOT NULL,
`salt` VARCHAR(40) NOT NULL,
`from` VARCHAR(40) NOT NULL,
PRIMARY KEY ( `id` )
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
数据库结构这边准备好后,我们来讲讲数据的导入与清洗。
推荐两款工具:
- Navicat for Mysql 强大而操作简易的图形化工具,不多解释.
- Mysqlimport Mysql工具集自带的工具,命令行配置,灵活度高,在导入数据速度方面具有显著优势。
Navicat可自行去官网下载。
通常,泄露的数据格式会像这样:
(注: 本文所展现的所有数据均为机器随机生成,仅供教学)
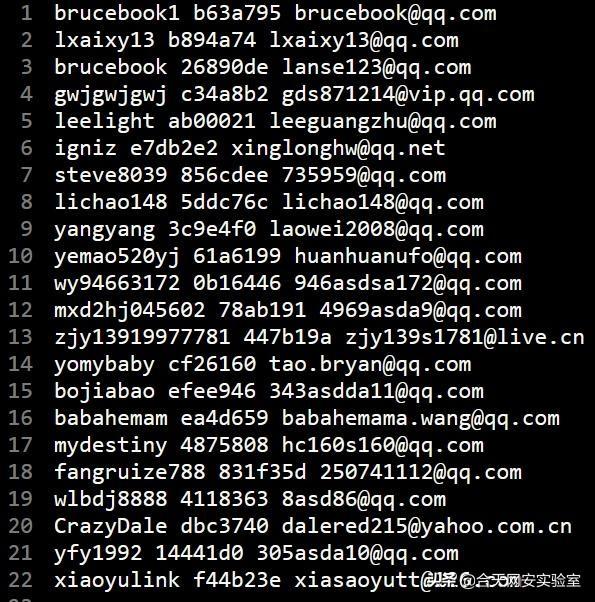
这是最简单且最好处理的一类数据,遇到就偷着乐吧hhhhhhh
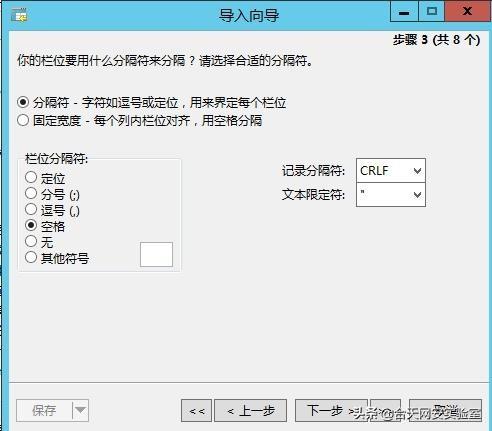
使用Navicat导入:
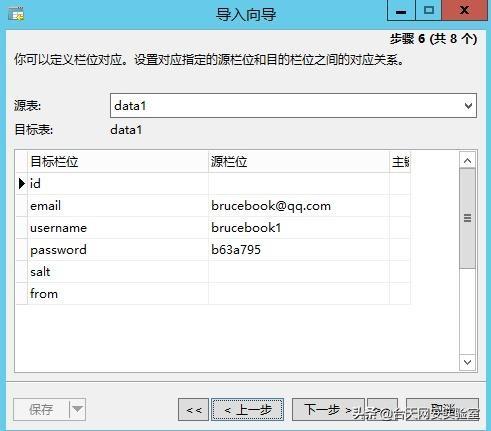
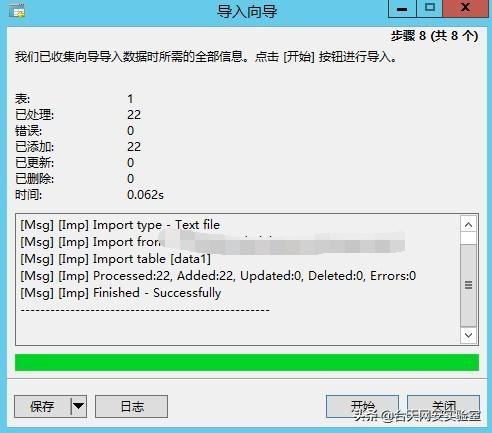
使用mysqlimport导入:
mysqlimport -u root -p --local --fields-terminated-by="" --lines-terminated-by="" sgk C:甥敳獲AdministratorDesktopdata1 --columns=username,password,email
参数详解:


--columns后字段名依次与数据表中的字段对应
最终效果:
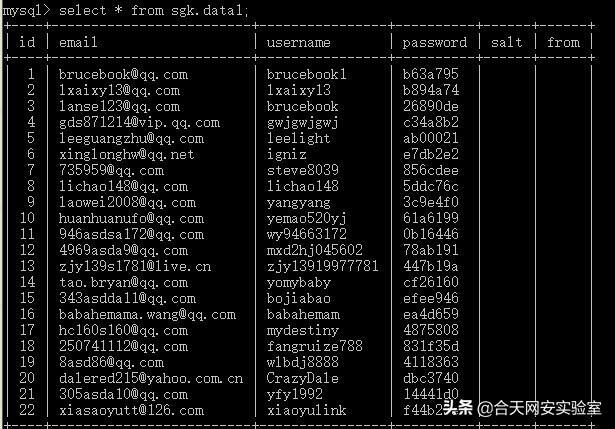
下面介绍几种较难处理的数据格式及清洗方法:
在清洗大文本数据时因为占用过高而无法直接打开查看,那么我们可以先取出一定样本进行分析。
比如head/tail命令便可从文本中取出前/后N行文本。
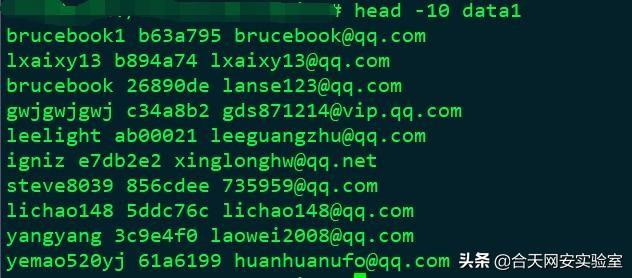
那么其实自己可以写一个脚本,将数据取样和mysqlimport操作执行自动化
类似这样的数据:
brucebook1----b63a795----brucebook@qq.com
lxaixy13----b894a74----lxaixy13@qq.com
brucebook----26890de----lanse123@qq.com
gwjgwjgwj----c34a8b2----gds871214@vip.qq.com
leelight----ab00021----leeguangzhu@qq.com
可以这么写:
mysqlimport -u root -p --local --fields-terminated-by="----" --lines-terminated-by="" sgk C:甥敳獲AdministratorDesktopdata1 --columns=username,password,email
数据清洗及导入就介绍到这里,关于数据维护由于篇幅限制我们放在下节讲。
0x03 测试索引查询效果:
1.建立索引:
/usr/local/coreseek/bin/indexer -c {最好配置文件绝对路径} {索引名字}
检查索引数据是否ok
2.启动索引服务
/usr/local/coreseek/bin/searchd -c /usr/local/coreseek/etc/sphinx.conf -i sgk
3.查看命令用法
/usr/local/coreseek/bin/search
4.直接搜索:
/usr/local/coreseek/bin/search -c {最好配置文件绝对路径} {索引名字}{搜索词}
1
demo:搜索一个词测试
5.索引重建
/usr/local/coreseek/bin/indexer --config /usr/local/coreseek/etc/project/sphinx.conf sgk --rotate 1
6.增量索引使用
/usr/local/coreseek/bin/indexer --config /usr/local/coreseek/etc/project/sphinx.conf sgk_merge --rotate
1
7.合并索引跟增量索引
/usr/local/coreseek/bin/indexer --config /usr/local/coreseek/etc/project/sphinx.conf --merge sgk_idx sgk_merge --rotate
0x04 结语:
本节教程就介绍到这里,介绍了索引引擎的配置文件与索引的建立,数据导入清洗相关的知识,希望大家有所收获。到目前为止,我们的私人数据查询系统就大概成形了,已经可以进行关键词的查询任务,下一步便是构建查询应用前后端,将数据完整且优雅的展现于眼前。之后如何,敬请期待下节课程。
渗透测试工程师岗位技能学习
岗位介绍:
渗透测试是通过模拟恶意黑客的攻击方法,来评估计算机网络系统安全的一种评估方法,渗透测试工程师利用各种手段对某个特定网络进行测试,以期发现和挖掘系统中存在的漏洞,然后输出渗透测试报告,并提交给网络所有者。网络所有者根据渗透人员提供的渗透测试报告,可以清晰知晓系统中存在的安全隐患和问题。
课程学习:
本岗位课程学习包括6章23小节134个实验,点击“http://www.hetianlab.com/pages/newPostSystem.jsp?channelID=zhihu”开始学习!
声明:笔者初衷用于分享与普及网络知识,若读者因此作出任何危害网络安全行为后果自负,与合天智汇及原作者无关,本文为合天原创,如需转载,请注明出处!


![IIS网站服务器性能优化指南[资源下载]](http://www.aspxhome.com/images/file/zip.gif)