-
Logstash简介
-
Logstash安装
-
测试运行
-
配置输入和输出
-
使用Geoip过滤器插件增强数据编辑
-
配置接收 Beats 的输入
1.Logstash简介
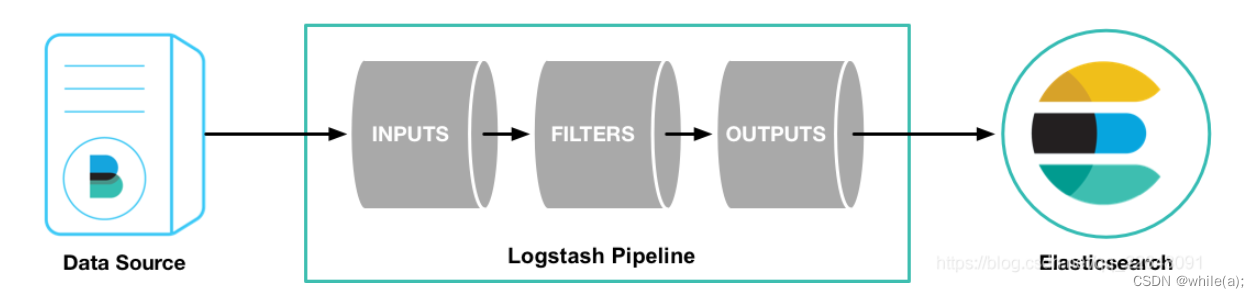
Logstash管道具有两个必需元素input和output,以及一个可选元素filter。输入插件使用来自源的数据,过滤器插件根据你的指定修改数据,输出插件将数据写入目标。
2.Logstash安装
参考官方网站:https://www.elastic.co/guide/en/logstash/current/index.html
# curl -OL https://artifacts.elastic.co/downloads/logstash/logstash-7.13.2-linux-x86_64.tar.gz
# tar -xf logstash-7.13.2-linux-x86_64.tar.gz -C /usr/local/
# mv /usr/local/logstash-7.13.2/ /usr/local/logstash
3.测试运行
运行最基本的Logstash管道来测试Logstash安装。
进入 Logstash 的安装主目录下执行:
/usr/local/logstash/bin/logstash -e ''
-e选项用于设置 Logstash 处理数据的输入和输出
-e ''等同于-e input { stdin { type => stdin } } output { stdout { codec => rubydebug } }
input { stdin { type => stdin } }表示 Logstash 需要处理的数据来源来自于标准输入设备
output { stdout { codec => rubydebug } }表示 Logstash 把处理好的数据输出到标准输出设备
稍等片刻,当看到屏幕上输出如下字样,即可尝试使用键盘输入
hello字样
message字段对应的值是 Logstash 接收到的一行完整的数据
@version是版本信息,可以用于建立索引使用
@timestamp处理此数据的时间戳,可以用于建立索引和搜索
type就是之前input中设置的值,这个值可以任意修改,但是,type是内置的变量,不能修改,用于建立索引和条件判断等
hosts表示从那个主机过来的数据修改
type的值为nginx的示例:./bin/logstash -e "input { stdin { type => nginx } } output { stdout { codec => rubydebug } }"


4.配置输入和输出
4.1 概述
生产中,Logstash管道要复杂一些:它通常具有一个或多个输入,过滤器和输出插件。
本部分中,将创建一个Logstash管道,该管道使用标准输入来获取Apache Web日志作为输入,解析这些日志以从日志中创建特定的命名字段,然后将解析的数据输出到标准输出(屏幕上)。并且这次无需在命令行上定义管道配置,而是在配置文件中定义管道。
4.2 创建并编写配置文件
创建任意一个文件,并写入如下内容,作为 Logstash 的管道配置文件
# vim /usr/local/logstash/config/first-pipeline.confinput {
stdin { }
}
output {
stdout {}
}配置文件语法测试:
bin/logstash -f config/first-pipeline.conf --config.test_and_exit
-f用于指定管道配置文件。
4.3 启动并测试
运行如下命令启动 Logstash:
bin/logstash -f config/first-pipeline.conf
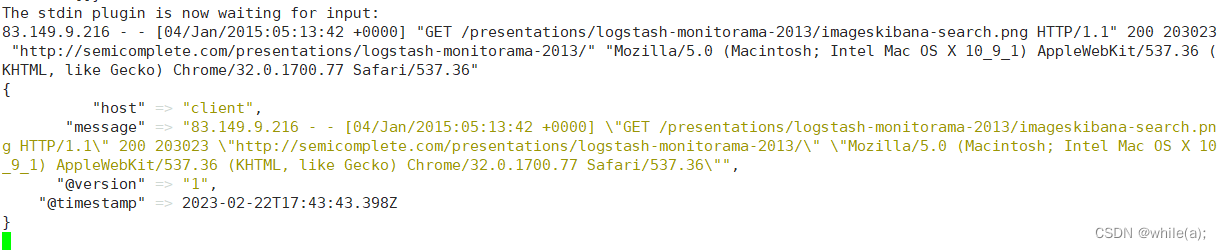
启动后复制如下内容到命令行中,并按下回车键:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/imageskibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
4.4 使用Grok过滤器插件解析Web日志
(一)概述
现在有了一个工作管道,但是日志消息的格式不是理想的。你想解析日志消息,以便能从日志中创建特定的命名字段。为此,应该使用grok 过滤器插件。
使用grok过滤器插件,可以将非结构化日志数据解析为结构化和可查询的内容。
grok 会根据你感兴趣的内容分配字段名称,并把这些内容和对应的字段名称进行绑定。
grok 如何知道哪些内容是你感兴趣的呢?它是通过自己预定义的模式来识别感兴趣的字段的。这个可以通过给其配置不同的模式来实现。
这里使用的模式是
%{COMBINEDAPACHELOG}
{COMBINEDAPACHELOG}使用以下模式从Apache日志中构造行:
原信息 对应新的字段名称 IP 地址 clientip 用户 ID ident 用户认证信息 auth 时间戳 timestamp HTTP 请求方法 verb 请求的 URL request HTTP 版本 httpversion 响应码 response 响应体大小 bytes 跳转来源 referrer 客户端代理(浏览器) agent 关于 grok 更多的用法请参考:
https://www.elastic.co/guide/en/logstash/7.10/plugins-filters-grok.html
(二)修改配置文件之后自动加载日志文件
并且这里要想实现修改配置文件之后自动加载它,不能配置
input为stdin。 所以, 这里使用了file,创建示例日志文件:# vim /var/log/httpd.log
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/imageskibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
4.5 确保没有缓存数据
[root@logstash file]# pwd
/usr/local/logstash/data/plugins/inputs/file
[root@logstash file]# ls -a
. .. .sincedb_aff270f7990dabcdbd0044eac08398ef
[root@logstash file]# rm -rf .sincedb_aff270f7990dabcdbd0044eac08398ef
4.6 修改好的管道配置文件如下:
# vim /usr/local/logstash/config/first-pipeline.conf
#注释方法#####
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}filter {
grok { # 对 web 日志进行过滤处理,输出结构化的数据
# 在 message 字段对应的值中查询匹配上 COMBINEDAPACHELOG
match => { "message" => "%{COMBINEDAPACHELOG}" } }
}output {
stdout {}
}
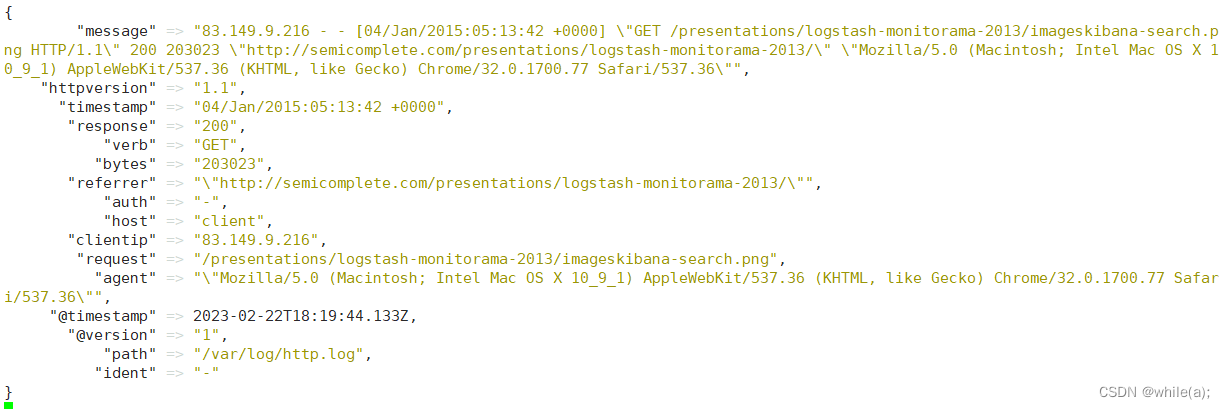
match => { "message" => "%{COMBINEDAPACHELOG}"}的意思是:当匹配到 "message" 字段时,用户模式 "{COMBINEDAPACHELOG}" 进行字段映射。
配置完成后,再次进行验证:
# /usr/local/logstash/bin/logstash -f config/first-pipeline.conf
发现原来的非结构化数据,变为结构化的数据了。
原来的
message字段仍然存在,假如你不需要它,可以使用 grok 中提供的常用选项之一:remove_filed来移除这个字段。
(一)remove_field 可以移除任意的字段
remove_field可以移除任意的字段,它可以接收的值是一个数组。rename可以重新命名字段
修改后管道配置文件如下:
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" } }
mutate {
#重写字段
rename => {
"clientip" => "cip"
}
}
mutate {
#去掉没用字段
remove_field => ["message","input_type","@version","fields"]
}
}
output {
stdout {}
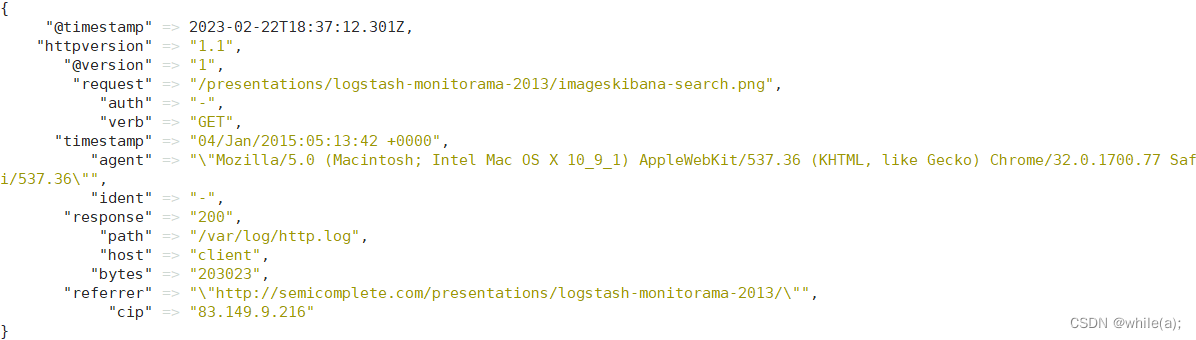
}再次测试并观察:
发现
message不见了,而且clientip重命名成了cip
5.使用Geoip过滤器插件增强数据编辑
5.1 概述
除解析日志数据以进行更好的搜索外,筛选器插件还可以从现有数据中获取补充信息。例如,
geoip插件可以通过查找到IP地址,并从自己自带的数据库中找到地址对应的地理位置信息,然后将该位置信息添加到日志中。该geoip插件配置要求您指定包含IP地址来查找源字段的名称。在此示例中,该clientip字段包含IP地址。
geoip {
source => "clientip"
}由于过滤器是按顺序求值的,因此请确保该geoip部分位于grok配置文件的该部分之后,并且grok和geoip部分都嵌套在该filter部分中。
5.2 配置文件并测试观察
完成后的管道配置文件如下:
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG }" }
}
geoip { source => "clientip" }
}output {
stdout {}
}再次输入之前的日志内容,就会看到如下输出----"country_code3" => "RU":
详情请参考:
https://www.elastic.co/guide/en/logstash/7.10/plugins-filters-grok.html
https://www.elastic.co/guide/en/logstash/7.10/plugins-filters-geoip.html

6.配置filebeat + logstash
6.1 配置接收 Beats 的输入
# vim /usr/local/logstash/config/pipeline-1.conf
# 监听 5044 端口,接收 filebeat 的输入
input {
beats {
port => 5044
}
}filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG }" }
}
# geoip { source => "clientip" }
}output {
stdout {}
}运行logstash之后修改filebeat的yml文件输出目标如下:
output.logstash:
# The Logstash hosts
hosts: ["192.168.19.3:5044"]filebeat机器清除缓存目录:
# rm -rf /usr/local/filebeat/data/
运行filebeat:
# ./filebeat
观察logstash接收到的filebeat的消息如下: