前面介绍的scrapy爬虫只能爬取单个网页。如果我们想爬取多个网页。比如网上的小说该如何如何操作呢。比如下面的这样的结构。是小说的第一篇。可以点击返回目录还是下一页

对应的网页代码:
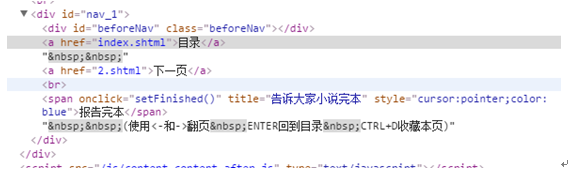
我们再看进入后面章节的网页,可以看到增加了上一页

对应的网页代码:
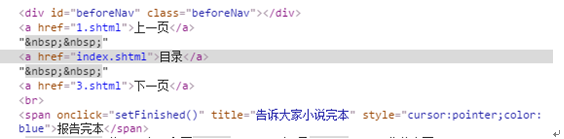
通过对比上面的网页代码可以看到. 上一页,目录,下一页的网页代码都在
下的元素的href里面。不同的是第一章只有2个元素,从二章开始就有3个元素。因此我们可以通过
下
前面介绍的scrapy爬虫只能爬取单个网页。如果我们想爬取多个网页。比如网上的小说该如何如何操作呢。比如下面的这样的结构。是小说的第一篇。可以点击返回目录还是下一页
对应的网页代码:
我们再看进入后面章节的网页,可以看到增加了上一页
对应的网页代码:
通过对比上面的网页代码可以看到. 上一页,目录,下一页的网页代码都在
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.luyixian.cn/news_show_730106.aspx
如若内容造成侵权/违法违规/事实不符,请联系dt猫网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!









![网站安装打包 新建网站[四][创建网站] 中](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)