笔记整理:陈鹏,天津大学硕士
链接:https://aclanthology.org/2022.findings-acl.217.pdf
动机
实体对齐(Entity Alignment)的基本目标在于发现两个知识图谱间指向同一现实对象的实体对,以便将不同知识图谱连接起来,更好地支持下游应用。基于知识图谱嵌入的方法在最近的实体对齐研究中吸引了越来越多的注意。现有的方法尽管取得了很大进展,但是往往直接把相似度最高的候选实体直接匹配输入实体,而不考虑该候选实体更深层次的语义,很难高效、准确地搜寻和评估实体对。为了解决这个问题,本文将实体对齐任务建模为序列决策任务,提出基于强化学习的知识图谱实体对齐框架(RLEA)。实验结果显示本文提出的的方法显著提高了现有SOTA方法的性能表现,最高提高31.1%。
亮点
RLEA的亮点主要包括:
(1)首次将实体对齐问题建模为序列决策任务,为优化基于嵌入的实体对齐任务(EEA)的评估策略提供了通用的解决方法;
(2)首次提出基于强化学习的知识图谱实体对齐框架(RLEA)以解决序列EEA问题,显著提高了现有SOTA方法的性能表现;
概念及模型
RLEA并不直接使用实体嵌入的相似度作为判断依据,而是直接把嵌入作为输入,训练一个策略网络(Policy Network)使其能够寻找到尽可能多的实体对,以获得最大奖励(Reward)。同时,本文还采用了一种课程学习(Curriculum Learning)的策略,在训练过程中逐步增加难度,避免因任务复杂性而导致学习失败。
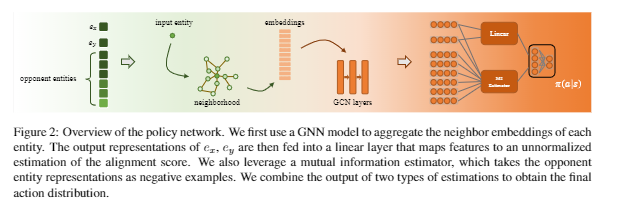
RLEA的基本结构如上图所示。对于输入实体和候选实体,本文选择了额外k个与输入实体接近的实体(即 opponent entities)作为context信息,可以用于拒绝当前匹配。对于每个实体,本文首先利用图卷积神经网络(GCN)同时编码其邻居向量以得到中间表示。
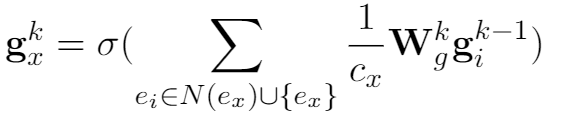
接下来将实体和候选实体的表示输入到线性层中进行合并,并利用相反的实体表示作为负样本互信息作为额外的特征,综合两个评估器最终得到行为分布。
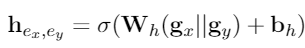
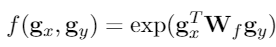
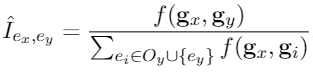
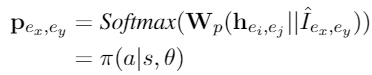
强化学习奖励函数如下所示:

本文使用策略梯度算法调整参数以获取更大的奖励得分,并利用一个基线函数作为比较以减少方差:

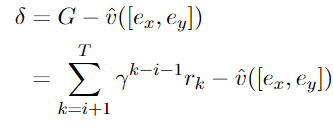
本文采用课程学习的策略与环境交互,在序列训练过程中逐步增加难度。
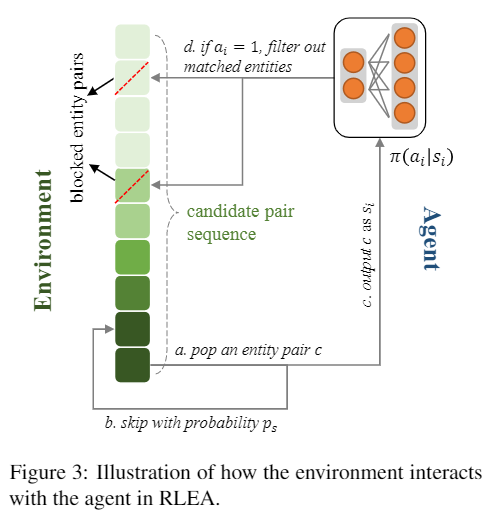
如上图所示,RLEA在环境中维持了一个匹配对序列,根据实体对间的相似度进行排序,以保证在测试阶段的使用。由于相似度高的实体对未必真正匹配,在训练过程中本文通过对比实际标签与相似度信息来判断一个匹配对的难易程度。根据当前训练轮数,较高难度的匹配对将有更大的概率直接逃过训练。在一轮中,环境所给出的实体对将被模型逐对进行判断,被认为匹配的实体对将会直接排除环境序列中的所有涉及这些实体的匹配对,这一过程一直持续到序列终止或所有实体均被匹配。
理论分析
实验
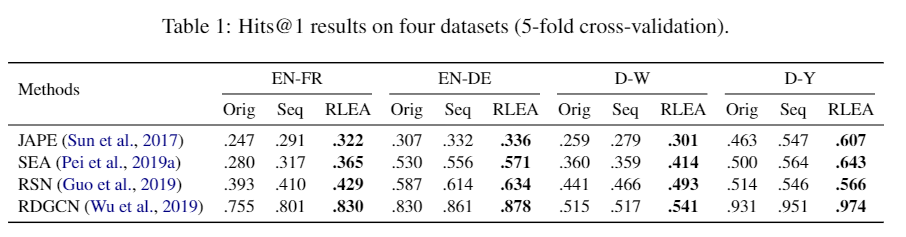
本文选取了含有15k条数据OpenEA数据集进行实验,包含EN-FR,EN-DE,D-W和D-Y4个子数据集,其中囊括跨语言和跨资源数据集。另外,本文选取4个性能领先且具有不同特点的实体对齐模型作为对比,结果如下表所示,RLEA在全部四种子数据集上均相较原有基线方法有显著提升。另外,Seq为仅仅采用序列决策而不涉及强化学习的对比方法,其在绝大多数情况下也优于目前所采用的贪心策略。
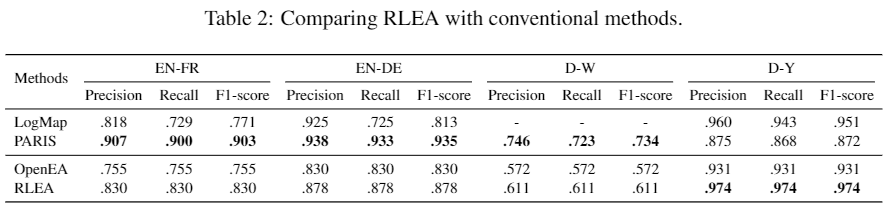
另外,本文还与传统实体对齐方法进行了对比。尽管之前的基于嵌入的方法具有许多优点,但在性能上仍与基于字符匹配等技术的传统方法有着较大差距。本文所提出的基于强化学习的方法不但缩小了这一差距,并且在一些数据集上(如D-Y)显著优于传统方法。
总结
本文针对直接把相似度最高的候选实体直接匹配输入实体,而不考虑该候选实体更深层次的语义,很难高效、准确地搜寻和评估实体对的问题,将实体对齐问题建模为序列决策任务,并提出提出基于强化学习的知识图谱实体对齐框架进行模型优化。实验结果显示本文提出的的方法显著提高了现有SOTA方法的性能表现。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。