采集网址:https://www.zhihu.com/people/ponyma/followers
爬虫文件
import scrapy
import jsonclass ZhihuSpider(scrapy.Spider):name = 'zhihu'allowed_domains = ['zhihu.com']start_urls = [f'https://www.zhihu.com/api/v4/members/ponyma/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={offset}0&limit=20'for offset in range(0, 200, 20)]def parse(self, response):# 打印请求头# print(response.request.headers)json_data = json.loads(response.text)if json_data.get("data", False):for data in json_data['data']:item = datayield item
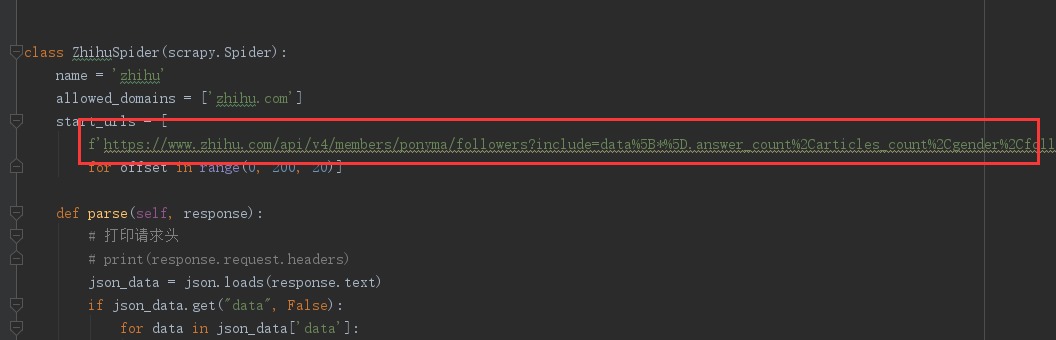
此网址采用抓包方式爬取
步骤一:打开采集网址 右边右键选择检查或者F12打开开发者模式
步骤二:
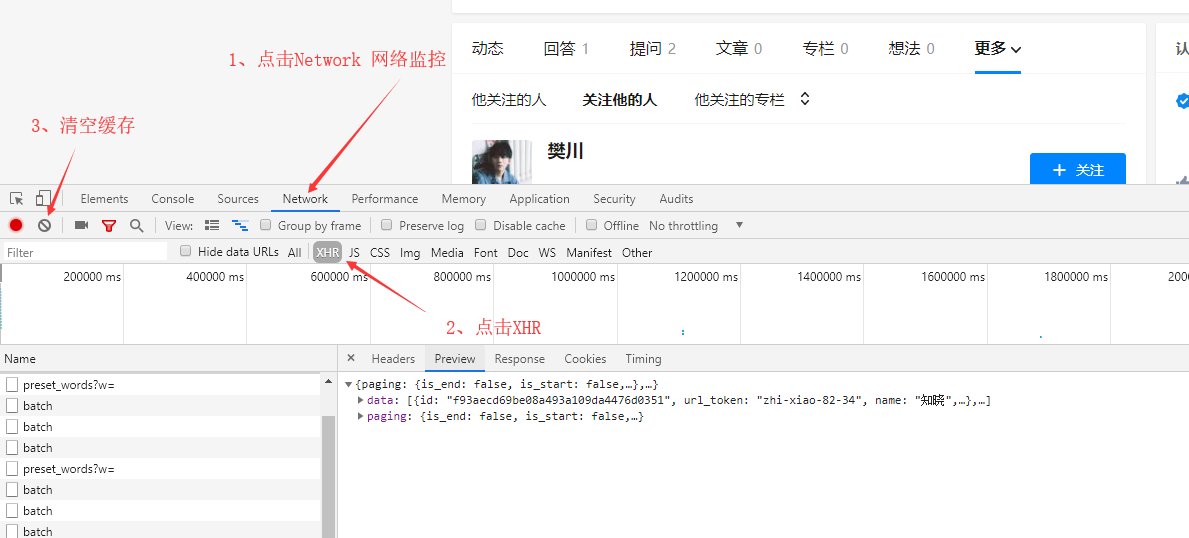
步骤三:点击页面中的下一页,注意不用刷新整个页面


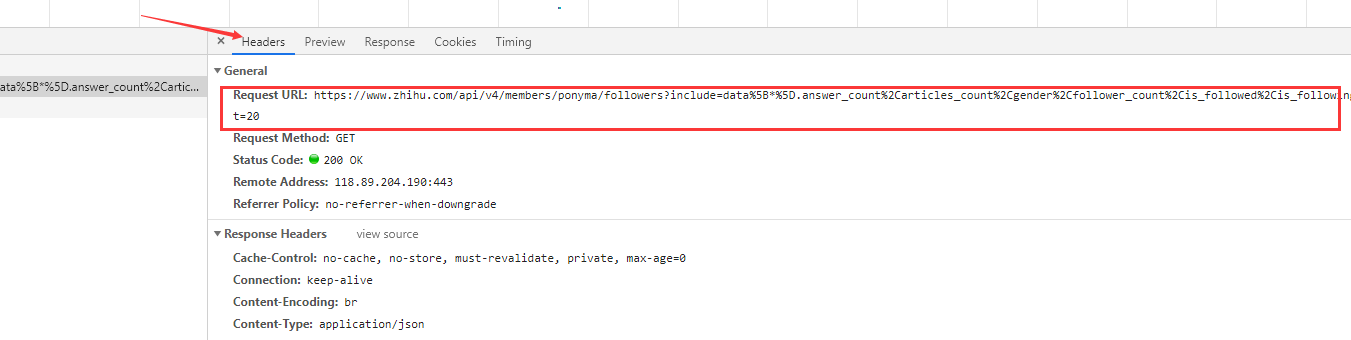
步骤四:点击Headers找到对应请求网址
管道文件(pipelines.py)
import jsonclass ZhihuspiderPipeline(object):def __init__(self):# 打开文件self.file = open("zhihu.json", "a", encoding="utf-8")def process_item(self, item, spider):self.file.write(json.dumps(item, ensure_ascii=False) + "\n")return itemdef close_spider(self, spider):# 关闭文件self.file.close()
配置文件(settings.py)
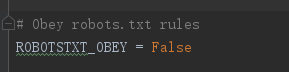
步骤一:关闭网址的robotstxt协议
步骤二:设置请求头

步骤三:激活管道文件

运行程序
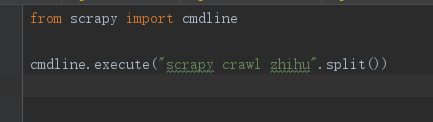
方法① :使用终端执行文件

进入文件的目录下使用命令:scrapy crawl 爬虫名
方法② :使用文件运行
在文件的目录下创建run_spider.py 文件,这里的文件名可以随意起