新增一个ebook页面--新增路由
the-header加菜单--点击跳转的页面--在index中添加路由--在the-header中跳转路由
使用PageHelper实现后端分页
集成PageHelper插件
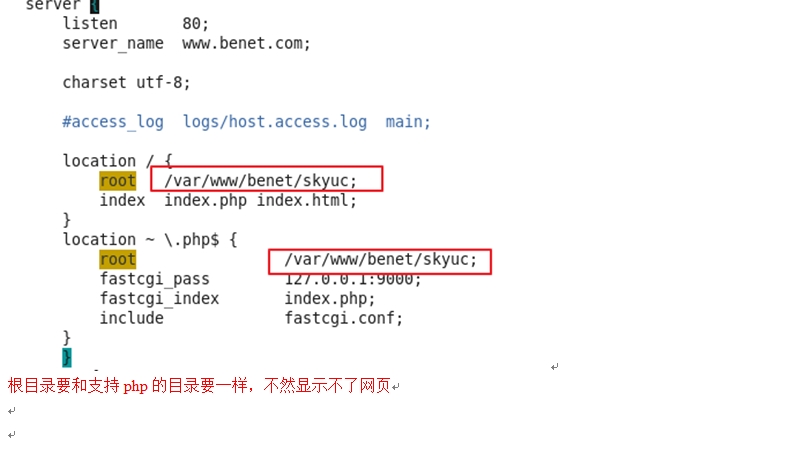
<!-- pagehelper 插件--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><version>1.2.13</version></dependency>修改电子书列表接口,支持分页(假分页数据)
分页参数PageNum从1开始
只对第一个遇到的SQL起作用
PageHelper.startPage(PageNum,PageSize);在日志中把sql语句打印出来
application.properties中加入
# 打印所有的sql日志:sql, 参数, 结果
logging.level.com.jwt.sys.mapper=trace以后很多功能都会用到分页,他们的分页都是PageReq
请求参数PageNum PageSize是0,表示前端数据根本没传到后端
@RequestBody注解对应的就是json方式的post提交
完成电子书编辑功能
- 在EbookController中写一个ebook的保存接口
最后保存成功,不需要返回任何东西,只需要返回CommonResp中success=true即可@PostMapping("/save")public CommonResp save(EbookSaveReq req){CommonResp resp = new CommonResp();ebookService.save(req);return resp;}
保存接口请求参数用XXXSaveReq
查询接口请求参数XXXQueryReq
查询接口返回参数用XXXQueryResp
查询和保存,请求参数数据是不一样的 -
POST请求,如果是以json方式提交,后端参数需要增加@RequestBody,如果是以form方式提交,则不需要加任何注解
雪花算法与新增功能
-
时间戳概念
2022-2-4 08:00:00 这个叫日期格式化,不叫时间戳
时间戳一般是一个长整形
打印当前时间 时间戳,就是与1970-01-01 08:00:00以毫秒为单位,做一个差值,与北京时间有8小时时间差
以某一时间点为时间戳,复制到最上方起始时间
/*** 起始的时间戳*/private final static long START_STMP = 1640995200000L; // 2022-01-01 00:00:00@Resource是jdk自带的
@Autowired是Spring自带的 -
雪花算法工具类
将雪花算法工具类注入到Service中 -
完成新增功能
在新增中调用nextId方法
ebook.setId(snowFlake.nextId());
面试题:id有几种算法
1.简单的自增
2.uuid
3.雪花算法
雪花算法ID,数据库和页面不一致
增加删除电子书功能
电子书管理页面,点击某一行的删除按钮时,删除该行电子书
后端增加删除接口
前端点击删除按钮时调用后端删除接口
删除时需要有一个确认框
删除一般根据id来删除,直接在路径后面加一个id,用大括号括起来,并不是mybatis参数${},直接就是{},需要在下面定义一下,@PathVariable Long id.在service中mapper调用delete主键方法
集成Validation做参数校验
添加依赖,Springboot内置,不需要添加版本号
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId></dependency>在属性上方添加注解,校验
还需要开启校验@Valid 表示里面这组数据要开启校验
统一异常处理
BindException 有针对性的异常 validation中的BindException
Exception 无针对性异常
根据日志出现的xxxException来做统一异常处理
- 使用方法:
-
实体增加校验注解
@NotNull(message = “【每页条数】不能为空”)
@Max(value = 100, message = “【每页条数】不能超过100”)
protected Integer size; -
接口参数增加注解@Valid,开启校验
public CommonResp query(@Valid EbookQueryReq req)
- 全局异常处理,使用@ControllerAdvice
电子书管理功能优化
-
增加名字查询
-
编辑时复制对象
面试题
- 什么是物理分页,什么是逻辑分页?
物理分页(后端分页):每次只从数据库查出当前页的数据,并查出总条数,前端显示页码和数据
逻辑分页(前端分页):数据一次性查询到前端,由前端根据总数据,来设置分页页码和当前页数据
适用场景:
物理分页适用于数据量大、更新频繁的场景
逻辑分页适用于数据量少、更新不频繁的场景
- 扩展:什么是物理删除,什么是逻辑删除?
逻辑删除 是指文件没有被真正的删除,只不过是文件名的第一个字节被改成操作系统无法识别的字符。通常这种删除操作是可逆的,就是说用适当的工具或软件可以把删除的文件恢复出来。
数据库的物理删除,直接使用delete、drop删除了表数据。
数据库的逻辑删除:通常使用一个is_deleted字段标示行记录是不是被删除(或者使用一个status字段代表所谓的“删除”状态),在逻辑上是数据是被删除的,但数据本身是依然存在的。
物理删除一定程度上删除了暂时“无用”的数据,降低了表的数据量,对性能肯定是有好处的;但是如果没有备份的话,数据很难恢复。
逻辑删除恢复的话只要修改is_deleted等类似的状态标示字段就可以了,但是表的数据量肯定会比物理删除增加了,并且查询时经常要考虑到is_deleted字段,对索引都会有影响。
- Mysql的分页关键字是什么?
LIMIT关键字
集成PageHelper插件后,在service层可直接使用
PageHelper.startPage(page, size)
page从1开始
获取分页信息
PageInfo<Ebook> pageInfo = new PageInfo<>(ebookList);
pageInfo.getTotal();
pageInfo.getPages();
PageHelper原理:Mybatis拦截器,拦截到SQL后,增加limit关键字
只对第一个遇到的SQL起作用
4.数据库ID有哪些设计方法,都有什么优缺点?
自增长ID
特点:
数值类型,值递增,由数据库内部生成
优点:
是最简单的方式,开发简单,性能优秀
缺点:
不适合分表分库场景,会出现主键冲突,ID重复,这是硬伤
会有N+1次查询问题,Java代码想获取ID,需要再查询一次
UUID
特点:
字符串类型,值没什么规律
优点:
适用于分表分库场景
UUID一般由Java代码生成,Java不需要查询就能知道ID
缺点:
性能不如自增
雪花算法
特点:
数值类型,由Twitter提供的分布式ID算法,递增
优点:
适用于分表分库场景,就是为这场景而生的
由Java代码生成,Java不需要查询就能知道ID
所有需要生成唯一ID的都可用雪花算法,比如登录token、日志编号等
缺点:
性能稍稍不如自增
生成的值较长,传递到前端number类型容易出现精度丢失,可以转成字符串解决
总结
如果是简单的小项目,可以考虑用自增ID
如果是中大型项目,推荐用雪花ID
至于UUID,因为有雪花算法的存在,所以可以放弃UUID
但是,小项目我也建议用雪花算法。以后做的项目多了,就不至于一会是自增ID,一会是雪花ID,不至于思维跳跃
6.什么是前端校验?什么是后端校验?
前端校验就是表单验证,后端校验就是接口参数校验。使用validation组件对接口请求的实体类通过NotNull等注解实现检验。
借助浏览器开发者工具,可以修改界面元素属性,比如将不可编辑变为可编辑,将不可点击变为可点击。
或者找到按钮提交的接口和请求参数,再利用接口测试工具,直接访问后端接口,完美绕过界面校验。
只做前端校验:会有安全问题
只做后端校验:会有服务器压力问题
正解:前端校验+后端校验
7.你们项目是如何处理异常的?
编写 统一异常处理类ControllerAdvice注解,ExceptionHandler注解对某种异常进行统一处理