我们来到这个比赛页面:https://www.kaggle.com/competitions/dog-breed-identification
这个数据集的目标是Determine the breed of a dog in an image(确定图像中狗的品种)
我们先下载数据集解压之后来看下(当然不手动解压,也可以使用),这里我放在一个DOG-BREED目录的dataset里面:
D:\DOG-BREED\dataset\train:10222张训练图
D:\DOG-BREED\dataset\test:10357张测试图
D:\DOG-BREED\dataset\labels.csv:10222行的id与breed,就是图片名称与对应的类别
D:\DOG-BREED\dataset\sample_submission.csv:提交的格式,121列,除了第一列的id,其余列是120个狗的品种分别对应的识别概率,10357行。
狗的品种之多属实超出我的想象:比如有㹴犬类、金毛猎犬、苏俄牧羊犬、马尔济斯犬、蓝色快狗、美洲赤狗等等
从下载的数据集来看是跟上一篇的Kaggle系列之CIFAR-10图像分类(残差网络模型ResNet-18)
的CIFAR-10数据集类似,区别就是图片尺寸更大了,尺寸也不是固定的大小。那对于熟悉了CIFAR-10分类方法来说,这节就显得比较容易了,大部分都差不多,对比上节来说有个新的知识点,就是图片大了,网络模型大了,我们使用预训练模型来获取特征,这个可以节省时间和训练期间存储参数的梯度的空间,对于配置低的伙伴们来说是最大的帮助了。
整理数据集
下载好之后,我们同样对数据集进行一些必要的整理,在原始训练数据集中切分出验证集,参数valid_ratio表示验证集中每类狗的样本数与原始训练集中数量最少一类的狗的样本数(66)之比。同一类狗的图像分别放到各自对应的目录中,便于后面的读取。
代码如下:
import collections
import d2lzh as d2l
import os
from mxnet import autograd,gluon,init,nd
from mxnet.gluon import data as gdata,loss as gloss,nn,model_zoo
import shutil
import time
import mathdef reorg_train_valid(data_dir, train_dir, input_dir, valid_ratio, idx_label):# 选择训练集最少一类的狗的样本数min_n_train_per_label = (collections.Counter(idx_label.values()).most_common()[:-2:-1][0][1])#验证集中每类狗的样本数n_valid_per_label = math.floor(min_n_train_per_label*valid_ratio)label_count = {}for train_file in os.listdir(os.path.join(data_dir, train_dir)):idx = train_file.split('.')[0]label = idx_label[idx]d2l.mkdir_if_not_exist([data_dir, input_dir, 'train_valid', label])src1 = os.path.join(data_dir, train_dir, train_file)dst1 = os.path.join(data_dir, input_dir, 'train_valid', label)shutil.copy(src1, dst1)if label not in label_count or label_count[label] < n_valid_per_label:d2l.mkdir_if_not_exist([data_dir, input_dir, 'valid', label])src2 = os.path.join(data_dir, train_dir, train_file)dst2 = os.path.join(data_dir, input_dir, 'valid', label)shutil.copy(src2, dst2)label_count[label] = label_count.get(label, 0)+1else:d2l.mkdir_if_not_exist([data_dir, input_dir, 'train', label])src3 = os.path.join(data_dir, train_dir, train_file)dst3 = os.path.join(data_dir, input_dir, 'train', label)shutil.copy(src3, dst3)def reorg_dog_data(data_dir, label_file, train_dir, test_dir, input_dir, valid_ratio):'''读取训练数据的标签,以及切分验证集并整理测试集'''with open(os.path.join(data_dir, label_file), 'r') as f:lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]idx_label = dict(((idx, label) for idx, label in tokens))reorg_train_valid(data_dir, train_dir, input_dir, valid_ratio, idx_label)# 整理测试集d2l.mkdir_if_not_exist([data_dir, input_dir, 'test', 'unknown'])for test_file in os.listdir(os.path.join(data_dir, test_dir)):src = os.path.join(data_dir, test_dir, test_file)dst = os.path.join(data_dir, input_dir, 'test', 'unknown')shutil.copy(src, dst)data_dir, label_file, train_dir, test_dir = 'dataset', 'labels.csv', 'train', 'test'
input_dir, batch_size, valid_ratio = 'train_valid_test', 128, 0.1
reorg_dog_data(data_dir, label_file, train_dir, test_dir, input_dir, valid_ratio)执行之后,我们将会在dataset目录看到生成了一个train_valid_test目录,在其下面创建了四个目录:train、valid、train_valid、test
然后在这些目录里面分别生成120个目录(文件夹名称就是类别),里面是对应品种的狗的图片,本人电脑的目录如下:
D:\DOG-BREED\dataset\train_valid_test\train\[affenpinscher]...\[74张]....jpg
D:\DOG-BREED\dataset\train_valid_test\valid\[affenpinscher]...\6张.jpg
D:\DOG-BREED\dataset\train_valid_test\train_valid\[affenpinscher]...\[74+6张]....jpg
D:\DOG-BREED\dataset\train_valid_test\test\unknown\10357张.jpg
collections.Counter
其中有一个collections.Counter方法,简单介绍下,也是官方源码:
c=collections.Counter('wwaabbcdeg')得到的是一组字典,并分别统计它们各自的数量
Counter({'w': 2, 'a': 2, 'b': 2, 'c': 1, 'd': 1, 'e': 1, 'g': 1})元组组成的列表形式
c.most_common()
#[('w', 2), ('a', 2), ('b', 2), ('c', 1), ('d', 1), ('e', 1), ('g', 1)]所以在代码中选择最少一类的狗的样本数就是最后一个元组的第二列
c.most_common()[-2:-1][0][1]查看元素
list(c.elements())
#['w', 'w', 'a', 'a', 'b', 'b', 'c', 'd', 'e', 'g']排序且去重
sorted(c)
#['a', 'b', 'c', 'd', 'e', 'g', 'w']统计数量
sum(c.values())#10查看单个元素的统计数
c['w']#2添加一个计数器
d=collections.Counter('wwwpla')
c.update(d)
#Counter({'w': 5, 'a': 3, 'b': 2, 'c': 1, 'd': 1, 'e': 1, 'g': 1, 'p': 1, 'l': 1})基本用法就这些,更多的用法示例可以查看其定义。
图像增广
这次的数据集的图片比CIFAR10要大很多,所以在图片增广方面,尽量选取更多有用的图像增广操作。
transform_train = gdata.vision.transforms.Compose([# 随机裁剪0.08~1倍,高宽比3/4~4/3,然后缩放为高宽为224像素的图像gdata.vision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3.0/4.0, 4.0/3.0)),# 随机左右翻转gdata.vision.transforms.RandomFlipLeftRight(),# 随机变化亮度、对比度、饱和度gdata.vision.transforms.RandomColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),# 随机加噪声gdata.vision.transforms.RandomLighting(0.1),gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])#测试时,需要确定性的图像预处理操作
transform_test = gdata.vision.transforms.Compose([gdata.vision.transforms.Resize(256), gdata.vision.transforms.CenterCrop(224),gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])ToTensor()的用法
在图像增广的方法里面我们可以看到,在做图像增广操作后标准化之前,都需要做一次ToTensor(),这里有两个作用:
1、将形状从H*W*C转换成C*H*W
2、里面的值的范围[0, 255]转换成[0,1)
我们来看个示例,官方源码:
transformer = gdata.vision.transforms.ToTensor()
image = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
'''
[[[144 100 236][213 18 86]][[ 22 165 5][ 93 212 244]][[198 35 221][221 249 120]][[203 204 117][132 199 173]]]
<NDArray 4x2x3 @cpu(0)>
'''
transformer(image)
'''
[[[0.5647059 0.8352941 ][0.08627451 0.3647059 ][0.7764706 0.8666667 ][0.79607844 0.5176471 ]][[0.39215687 0.07058824][0.64705884 0.83137256][0.13725491 0.9764706 ][0.8 0.78039217]][[0.9254902 0.3372549 ][0.01960784 0.95686275][0.8666667 0.47058824][0.45882353 0.6784314 ]]]
<NDArray 3x4x2 @cpu(0)>
'''读取整理好的数据集
将数据集做了分类存放以及图像增广操作之后,接下来就是对数据集的读取了,同样是使用ImageFolderDataset实例来去读
train_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train'), flag=1)
valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'valid'), flag=1)
train_valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train_valid'), flag=1)
test_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'test'), flag=1)train_iter = gdata.DataLoader(train_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
valid_iter = gdata.DataLoader(valid_ds.transform_first(transform_test), batch_size, shuffle=True, last_batch='keep')
train_valid_iter = gdata.DataLoader(train_valid_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
test_iter = gdata.DataLoader(test_ds.transform_first(transform_test), batch_size, shuffle=False, last_batch='keep')定义网络模型
数据集都做了预处理之后,我们就选择一个合适的网络模型,这里用ResNet-34模型,由于比赛数据集属于预训练数据集的子集(Gluon提供了很多的预训练模型),因此我们直接复用预训练模型在输出层的输入,即抽取的特征。然后自定义一个小型的输出网络即可,这样的好处就是不需要训练模型来抽取特征了,节省了训练时间,以及省去了存储参数梯度占用的空间。
def get_net(ctx):# 加载模型预训练的权重finetune_net = model_zoo.vision.resnet34_v2(pretrained=True)# 定义新的输出网络finetune_net.output_new = nn.HybridSequential(prefix='')finetune_net.output_new.add(nn.Dense(256, activation='relu'))# 狗的品种是120finetune_net.output_new.add(nn.Dense(120))# 初始化输入网络finetune_net.output_new.initialize(init.Xavier(), ctx=ctx)# 将模型参数分配到内存或显存上finetune_net.collect_params().reset_ctx(ctx)return finetune_netloss=gloss.SoftmaxCrossEntropyLoss()def evaluate_loss(data_iter, net, ctx):l_sum, n = 0.0, 0for X, y in data_iter:y = y.as_in_context(ctx)output_features = net.features(X.as_in_context(ctx))outputs = net.output_new(output_features)l_sum += loss(outputs, y).sum().asscalar()n += y.sizereturn l_sum/n训练模型
当数据集和模型准备好了之后,就开始来训练模型,先定义一个训练函数train:
def train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay):trainer = gluon.Trainer(net.output_new.collect_params(), 'sgd', {'learning_rate': lr, 'momentum': 0.9, 'wd': wd})for epoch in range(num_epochs):train_l_sum, n, start = 0.0, 0, time.time()if epoch > 0 and epoch % lr_period == 0:trainer.set_learning_rate(trainer.learning_rate*lr_decay)for X, y in train_iter:y = y.as_in_context(ctx)output_features = net.features(X.as_in_context(ctx))with autograd.record():outputs = net.output_new(output_features)l = loss(outputs, y).sum()l.backward()trainer.step(batch_size)train_l_sum += l.asscalar()n += y.sizetime_s = "time %.2f sec" % (time.time()-start)if valid_iter is not None:valid_loss = evaluate_loss(valid_iter, net, ctx)epoch_s = ("epoch %d,train loss %f,valid loss %f," %(epoch+1, train_l_sum/n, valid_loss))else:epoch_s = ("epoch %d,train loss %f," % (epoch+1, train_l_sum/n))print(epoch_s+time_s+',lr '+str(trainer.learning_rate))ctx, num_epochs, lr, wd = d2l.try_gpu(), 1, 0.01, 1e-4
lr_period, lr_decay, net = 10, 0.1, get_net(ctx)
net.hybridize()
train(net, train_iter, valid_iter, num_epochs,lr, wd, ctx, lr_period, lr_decay)批处理batch_size大了,很容易内存溢出:
mxnet.base.MXNetError: [12:31:44] c:\jenkins\workspace\mxnet-tag\mxnet\src\storage\./pooled_storage_manager.h:157: cudaMalloc failed: out of memory
所以需要结合自己的硬件配置来调整这个批大小,将128调小,我这里调成16先运行下是否正常
epoch 1,train loss 1.784260,valid loss 0.756940,time 104.48 sec,lr 0.01
然后我们使用全部训练数据集(含验证集)来重新训练模型,并对测试集分类,生成提交文件submission.csv,这里我将batch_size调成64,num_epochs设置成10,全部代码如下:
import collections
import d2lzh as d2l
import os
from mxnet import autograd,gluon,init,nd
from mxnet.gluon import data as gdata,loss as gloss,nn,model_zoo
import shutil
import time
import mathdef reorg_train_valid(data_dir, train_dir, input_dir, valid_ratio, idx_label):# 选择训练集最少一类的狗的样本数min_n_train_per_label = (collections.Counter(idx_label.values()).most_common()[:-2:-1][0][1])#验证集中每类狗的样本数n_valid_per_label = math.floor(min_n_train_per_label*valid_ratio)label_count = {}for train_file in os.listdir(os.path.join(data_dir, train_dir)):idx = train_file.split('.')[0]label = idx_label[idx]d2l.mkdir_if_not_exist([data_dir, input_dir, 'train_valid', label])src1 = os.path.join(data_dir, train_dir, train_file)dst1 = os.path.join(data_dir, input_dir, 'train_valid', label)shutil.copy(src1, dst1)if label not in label_count or label_count[label] < n_valid_per_label:d2l.mkdir_if_not_exist([data_dir, input_dir, 'valid', label])src2 = os.path.join(data_dir, train_dir, train_file)dst2 = os.path.join(data_dir, input_dir, 'valid', label)shutil.copy(src2, dst2)label_count[label] = label_count.get(label, 0)+1else:d2l.mkdir_if_not_exist([data_dir, input_dir, 'train', label])src3 = os.path.join(data_dir, train_dir, train_file)dst3 = os.path.join(data_dir, input_dir, 'train', label)shutil.copy(src3, dst3)def reorg_dog_data(data_dir, label_file, train_dir, test_dir, input_dir, valid_ratio):'''读取训练数据的标签,以及切分验证集并整理测试集'''with open(os.path.join(data_dir, label_file), 'r') as f:lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]idx_label = dict(((idx, label) for idx, label in tokens))reorg_train_valid(data_dir, train_dir, input_dir, valid_ratio, idx_label)# 整理测试集d2l.mkdir_if_not_exist([data_dir, input_dir, 'test', 'unknown'])for test_file in os.listdir(os.path.join(data_dir, test_dir)):src = os.path.join(data_dir, test_dir, test_file)dst = os.path.join(data_dir, input_dir, 'test', 'unknown')shutil.copy(src, dst)data_dir, label_file, train_dir, test_dir = 'dataset', 'labels.csv', 'train', 'test'
input_dir, batch_size, valid_ratio = 'train_valid_test', 64, 0.1
#reorg_dog_data(data_dir, label_file, train_dir, test_dir, input_dir, valid_ratio)# -------- 图像增广 ------------
transform_train = gdata.vision.transforms.Compose([# 随机裁剪0.08~1倍,高宽比3/4~4/3,然后缩放为高宽为224像素的图像gdata.vision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3.0/4.0, 4.0/3.0)),# 随机左右翻转gdata.vision.transforms.RandomFlipLeftRight(),# 随机变化亮度、对比度、饱和度gdata.vision.transforms.RandomColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),# 随机加噪声gdata.vision.transforms.RandomLighting(0.1),gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])#测试时,需要确定性的图像预处理操作
transform_test = gdata.vision.transforms.Compose([gdata.vision.transforms.Resize(256), gdata.vision.transforms.CenterCrop(224),gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# -----读取数据集-------
train_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train'), flag=1)
valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'valid'), flag=1)
train_valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train_valid'), flag=1)
test_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'test'), flag=1)train_iter = gdata.DataLoader(train_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
valid_iter = gdata.DataLoader(valid_ds.transform_first(transform_test), batch_size, shuffle=True, last_batch='keep')
train_valid_iter = gdata.DataLoader(train_valid_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
test_iter = gdata.DataLoader(test_ds.transform_first(transform_test), batch_size, shuffle=False, last_batch='keep')# ----定义模型-----
def get_net(ctx):# 加载模型预训练的权重finetune_net = model_zoo.vision.resnet34_v2(pretrained=True)# 定义新的输出网络finetune_net.output_new = nn.HybridSequential(prefix='')finetune_net.output_new.add(nn.Dense(256, activation='relu'))# 狗的品种是120finetune_net.output_new.add(nn.Dense(120))# 初始化输入网络finetune_net.output_new.initialize(init.Xavier(), ctx=ctx)# 将模型参数分配到内存或显存上finetune_net.collect_params().reset_ctx(ctx)return finetune_netloss=gloss.SoftmaxCrossEntropyLoss()def evaluate_loss(data_iter, net, ctx):l_sum, n = 0.0, 0for X, y in data_iter:y = y.as_in_context(ctx)output_features = net.features(X.as_in_context(ctx))outputs = net.output_new(output_features)l_sum += loss(outputs, y).sum().asscalar()n += y.sizereturn l_sum/ndef train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay):trainer = gluon.Trainer(net.output_new.collect_params(), 'sgd', {'learning_rate': lr, 'momentum': 0.9, 'wd': wd})for epoch in range(num_epochs):train_l_sum, n, start = 0.0, 0, time.time()if epoch > 0 and epoch % lr_period == 0:trainer.set_learning_rate(trainer.learning_rate*lr_decay)for X, y in train_iter:y = y.as_in_context(ctx)output_features = net.features(X.as_in_context(ctx))with autograd.record():outputs = net.output_new(output_features)l = loss(outputs, y).sum()l.backward()trainer.step(batch_size)train_l_sum += l.asscalar()n += y.sizetime_s = "time %.2f sec" % (time.time()-start)if valid_iter is not None:valid_loss = evaluate_loss(valid_iter, net, ctx)epoch_s = ("epoch %d,train loss %f,valid loss %f," %(epoch+1, train_l_sum/n, valid_loss))else:epoch_s = ("epoch %d,train loss %f," % (epoch+1, train_l_sum/n))print(epoch_s+time_s+',lr '+str(trainer.learning_rate))ctx, num_epochs, lr, wd = d2l.try_gpu(), 1, 0.01, 1e-4
lr_period, lr_decay, net = 10, 0.1, get_net(ctx)
net.hybridize()
#train(net, train_iter, valid_iter, num_epochs,lr, wd, ctx, lr_period, lr_decay)num_epochs=10
train(net, train_valid_iter, None, num_epochs,lr, wd, ctx, lr_period, lr_decay)
preds = []
for data, label in test_iter:output_features = net.features(data.as_in_context(ctx))output = nd.softmax(net.output_new(output_features))preds.extend(output.asnumpy())
ids = sorted(os.listdir(os.path.join(data_dir, input_dir, 'test/unknown')))
with open('submission.csv', 'w') as f:f.write('id,'+",".join(train_valid_ds.synsets)+'\n')for i, output in zip(ids, preds):f.write(i.split('.')[0]+','+','.join([str(num) for num in output])+'\n')'''
epoch 1,train loss 2.346387,time 105.90 sec,lr 0.01
epoch 2,train loss 1.054525,time 98.97 sec,lr 0.01
epoch 3,train loss 0.936225,time 100.72 sec,lr 0.01
epoch 4,train loss 0.882884,time 100.87 sec,lr 0.01
epoch 5,train loss 0.829612,time 98.21 sec,lr 0.01
epoch 6,train loss 0.820044,time 98.81 sec,lr 0.01
epoch 7,train loss 0.820517,time 101.82 sec,lr 0.01
epoch 8,train loss 0.789499,time 100.52 sec,lr 0.01
epoch 9,train loss 0.780991,time 98.92 sec,lr 0.01
epoch 10,train loss 0.742645,time 99.46 sec,lr 0.01
'''将提交文件提交到Kaggle看下结果如何:
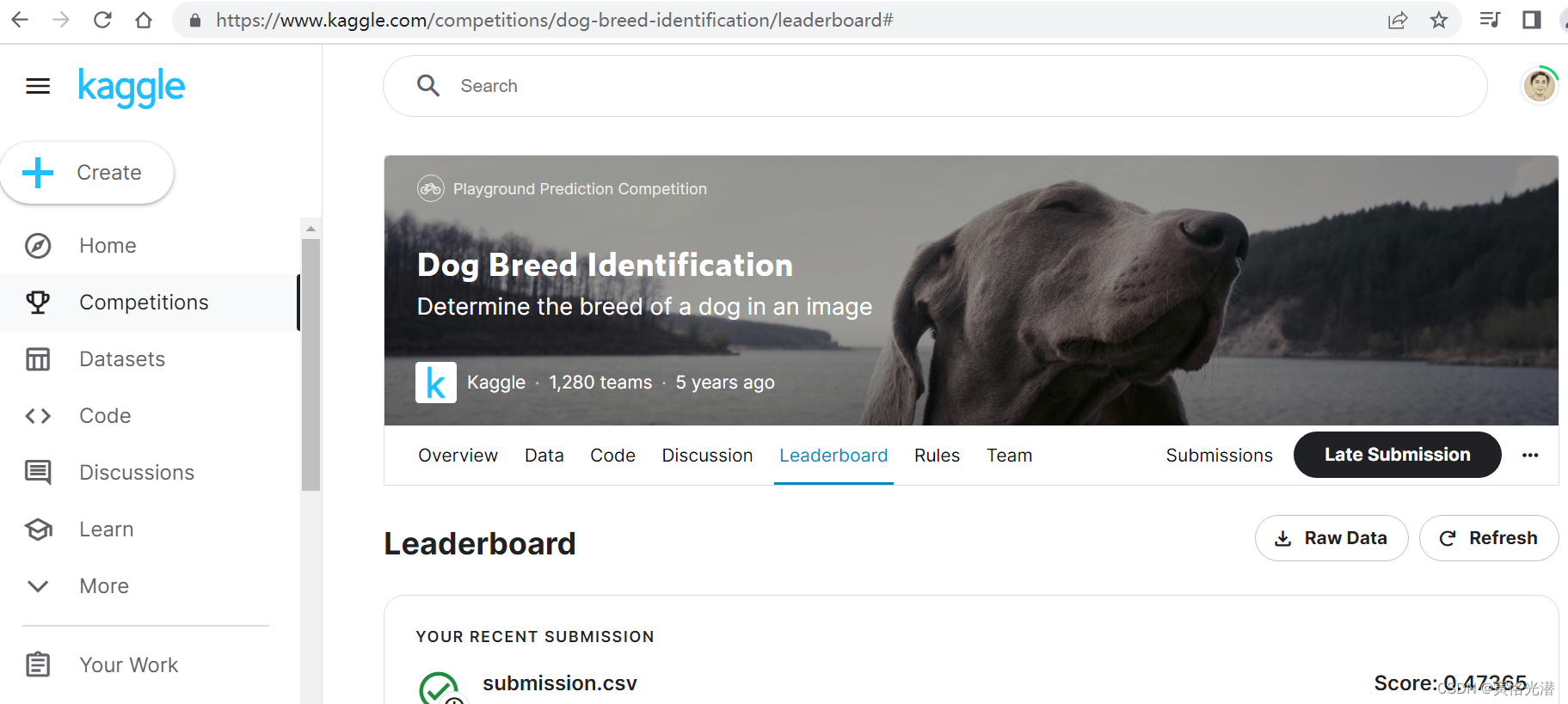
这个结果跟批处理大小和迭代次数有关,有兴趣的伙伴们可以调大点试试,当然还可以修改残差网络模型,加深层数看下效果会怎么样。