title: ElasticSearch索引管理
date: 2022-08-31 00:00:00
tags:
- ElasticSearch
- 索引管理
categories: - ElasticSearch
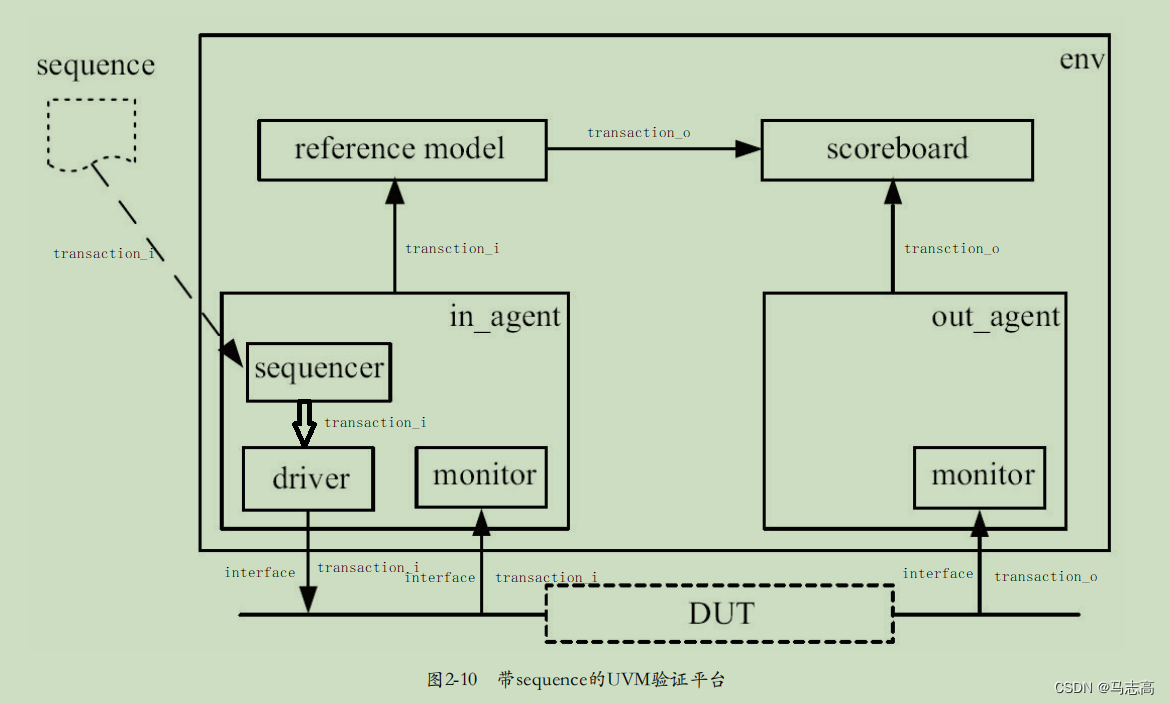
索引操作
-
创建索引
-
手动创建索引,可以在请求中加入所有设置和类型映射,例如:
PUT /mytest3 {"settings": {"number_of_shards": "3","number_of_replicas": "1"},"mappings": {"properties": {"description": {"type": "text","index": false}}} } -
如果在
config/elasticsearch.yml中添加action.auto_create_index: false配置来防止自动创建索引。
-
-
查看索引设置
GET /mytest3,可以指定响应对对象,例如GET /mytest3/_settings。 -
检查索引是否存在
HEAD /mytest3。 -
打开索引
POST /mytest3/_open,关闭索引POST /mytest3/_close。索引关闭后可以会在settings对象中增加"verified_before_close": "true"。 -
PUT mapping API
-
允许你创建索引并设定Mapping,或者给存在的索引增加新的类型,或者在已有类型中增加新的字段。一般不能修改已有的字段。
-
给存在的索引增加新的字段
PUT /mytest3/_mapping {"properties": {"user_name": {"type": "text"}} } -
可以同时为多个索引设置mapping,通配符也同样是支持的。
-
查询索引的mapping设置
GET /mytest3/_mapping,查询所有索引GET /_all/_mapping,查看某个索引的字段GET /mytest3/_mapping/field/user_name,description,也可以模糊匹配字段GET /mytest3/_mapping/field/descrip*。
-
-
更新索引的设置
- ES提供了优化好的默认配置,除非你明白这些配置的行为和为什么要这么做,请不要修改这些配置。
- 下面是两个最重要的设置:
- number_of_shards:定义一个索引的主分片个数,默认值是以前是5,现在根据节点数来计算。这个配置在索引创建后不能修改。
- number_of_replicas:每个主分片的复制分片个数,默认是1。这个配置可以随时在活跃的索引上修改。
PUT /mytest3/_settings {"index":{"number_of_replicas":2} }
- 更新索引分析器,需要先关闭索引再更新,最后打开索引。
POST /mytest3/_cloesePUT /mytest3/_settings {"analysis": {"analyzer": {"my_custom_analyzer": {"type":"custom", // 此参数可忽略"tokenizer":"whitespace"}}} }POST /mytest3/_open
-
Analyze API
- 执行对文本的分析,然后返回token结果:
GET /_analyze {"analyzer": "standard","text": "this is a 笔记本" }GET /_analyze {"analyzer": "ik_max_word","text": ["this is a 笔记本","Hello World! 世界你好!"] }
- 执行对文本的分析,然后返回token结果:
索引管理
- 索引统计信息
GET /mytest3/_stats。 - 查询低级的Lucene中索引段的信息
GET /mytest3/_segments。 - 查看索引分片的恢复信息,会报告recovery的状态
GET /mytest3/_recovery。 - 提供查看索引分片的存储信息
GET /mytest3/_shard_stores。 - 用来清除一到多个索引相关缓存
POST /mytest3/_cache/clear。 GET /mytest3/_flush把索引在内存里面的数据,存储到具体的存储器上,并删除相应的内部事务日志。- 可以设置参数:
- wait_if_ongoing:缺省是false,如果设置为true,将会阻塞并等待其它正在执行flush的功能执行完成,然后再执行。
- force:是否有必要强制执行,即使没有改变也要flush。
- 如果要同步f l ush,可以在后面设置synced,例如:
GET /mytest3/_flush/synced。
- 可以设置参数:
- 刷新索引,使得上次refresh后的操作引起的变化,都能够反映到查询上。例如:
GET /mytest3/_refresh。 _refresh和_flush的区别,前者是将ES内存中的文档刷到Lucene缓存区(此步就可被搜索),后者是将Lucene segment刷到磁盘。
索引配置
- 内存控制器
- 在ES中有很多控制器可以防止内存溢出,每个控制器可以指定内存使用的最大值,除此之外,还有一个总的控制器在确定整个系统使用的最大内存值。这些配置都可以动态更新。
- 总的内存控制有以下参数:indices.breaker.total.limit:
- 总的内存使用大小,默认为JVM堆内存大小的70%。
- 列数据内存大小
- 列数据内存大小是指,在ES系统中,系统会估计有多少数据被加载到内存中,如果估计超过这个阀值,它可以通过一个异常来防止该字段的数据加载。
- indices.breaker.fielddata.limit:列数据内存大小的限制,默认为JVM堆内存大小的60%。
- indices.breaker.fielddata.overhead:所有列估计的内存大小的乘积,默认是1.03。
- 请求控制器,防止Elasticsearch每个请求的数据结构超过一定的值:
- indices.breaker.request.limit:请求控制器的大小,默认为JVM堆内存大小的40%。
- indices.breaker.request.overhead:所有请求的乘积,默认为1。
- 数据缓存
- 现场数据缓存主要用于当排序或聚合操作的时候。它将所有的字段值加载到内存中以便提供快速访问文档中的这些值。
- indices.fielddata.cache.size:数据缓存的最大值,可以是一个节点的堆内存大小的比例,例如30%,也可以是一个绝对数字,比12GB。默认是无限制,可以最大的利用内存。这个配置是静态的配置,必须在集群中的每个数据节点上启动前配置好。可以通过
GET /_nodes/stats请求来监控节点的使用情况。
- 节点查询缓存
- 查询缓存是负责缓存查询的结果。每个节点都有一个查询缓存,这个缓存为这个节点下的所有分片服务。这个缓存采用最近最少使用算法; 当缓存满时,把最少使用的数据优先删掉。查询缓存只有使用过滤的时候才会起作用。
- indices.queries.cache.size:可以是一个节点的堆内存大小的比例,例如5%,也可以是一个绝对数字,比如512mb。默认为JVM堆内存大小的10%。
- 索引缓冲区
- 索引缓冲区用于存储新的索引文档。当缓冲区满后,缓冲区中的文件被写入磁盘上的一个段,它会在节点的所有分片上分离。它的设置是静态的,并且必须在群集中的每个数据节点上配置。
- indices.memory.index_buffer_size:一个节点索引缓冲区的大小,可以是一个节点的堆内存大小的比例获知是一个绝对数字。默认为JVM堆内存大小的10%。
- indices.memory.min_index_buffer_size:可以使用此设置指定最小的索引缓冲区大小。默认为48MB。
- indices.memory.max_index_buffer_size:可以使用此设置指定最大的索引缓冲区大小。默认为无限制。
- indices.memory.min_shard_index_buffer_size:分配给每个分片索引缓冲区的内存最小值,默认4MB。
- 分片请求缓存
- 当一个搜索请求是对一个索引或者多个索引的时候,每一个分片都是进行它自己内容的搜索然后把结果返回到协调节点,然后把这些结果合并到一起统一对外提供。分片缓存模块缓存了这个分片的搜索结果。这使得搜索频率高的请求会立即返回。
- 注意:请求缓存只缓存查询条件size=0的搜索,缓存的内容有hits.total, aggregations, suggestions,不缓存原始的hits。通过now查询的结果将不缓存。
- 缓存失效
- 只有在分片的数据实际上发生了变化的时候刷新分片缓存才会失效。刷新的时间间隔越长,缓存的数据越多,当缓存不够的时候,最少使用的数据将被删除。缓存过期可以手工设置,例如:
- 默认情况下缓存未启用,但在创建新的索引时可启用,例如:
PUT /mytest4 {"settings": {"number_of_shards": "2","number_of_replicas": 1,"index.requests.cache.enable": true} } - 当然也可以通过动态参数配置来进行设置:
PUT /mytest3/_settings {"index.requests.cache.enable": true } - 每请求启用缓存,查询字符串参数request_cache可用于启用或禁用每个请求的缓存。例如:
GET /mytest/_search?request_cache=true。- 如果你的查询使用了一个脚本,其结果是不确定的(例如,它使用一个随机函数或引用当前时间)应该设置request_cache为false禁用请求缓存。
- 数据的缓存是整个JSON,这意味着如果JSON发生了变化 ,如顺序不同,缓存的内容将会不同。
- 监控缓存使用
- 可以通过
GET /mytest4/_stats/request_cache或者GET /_nodes/stats/indices/request_cache来缓存监控,缓存的大小(以字节为单位)。
- 可以通过
- 索引恢复
- indices.recovery.concurrent_streams:默认为3。
- indices.recovery.concurrent_small_file_streams:默认为2。
- indices.recovery.file_chunk_size:默认为512KB。
- indices.recovery.translog_ops:默认为1000。
- indices.recovery.translog_size:默认为512KB。
- indices.recovery.compress:默认为true。
- indices.recovery.max_bytes_per_sec:默认为40MB。
- TTL区间
- 文档有个ttl值可以设置当过期的时候是否需要删除,设置如下:
- indices.ttl.interval:删除程序的运行时间。默认为60。
- indices.ttl.bulk_size:删除处理与批量请求的数量,默认为10000。
- 文档有个ttl值可以设置当过期的时候是否需要删除,设置如下: