文章目录
- 基础要求
- 题目要求
- 代码如下
- 结果如下
基础要求
莫烦python–基础
python基础学习-个人博客
Tkinter 学习
题目要求
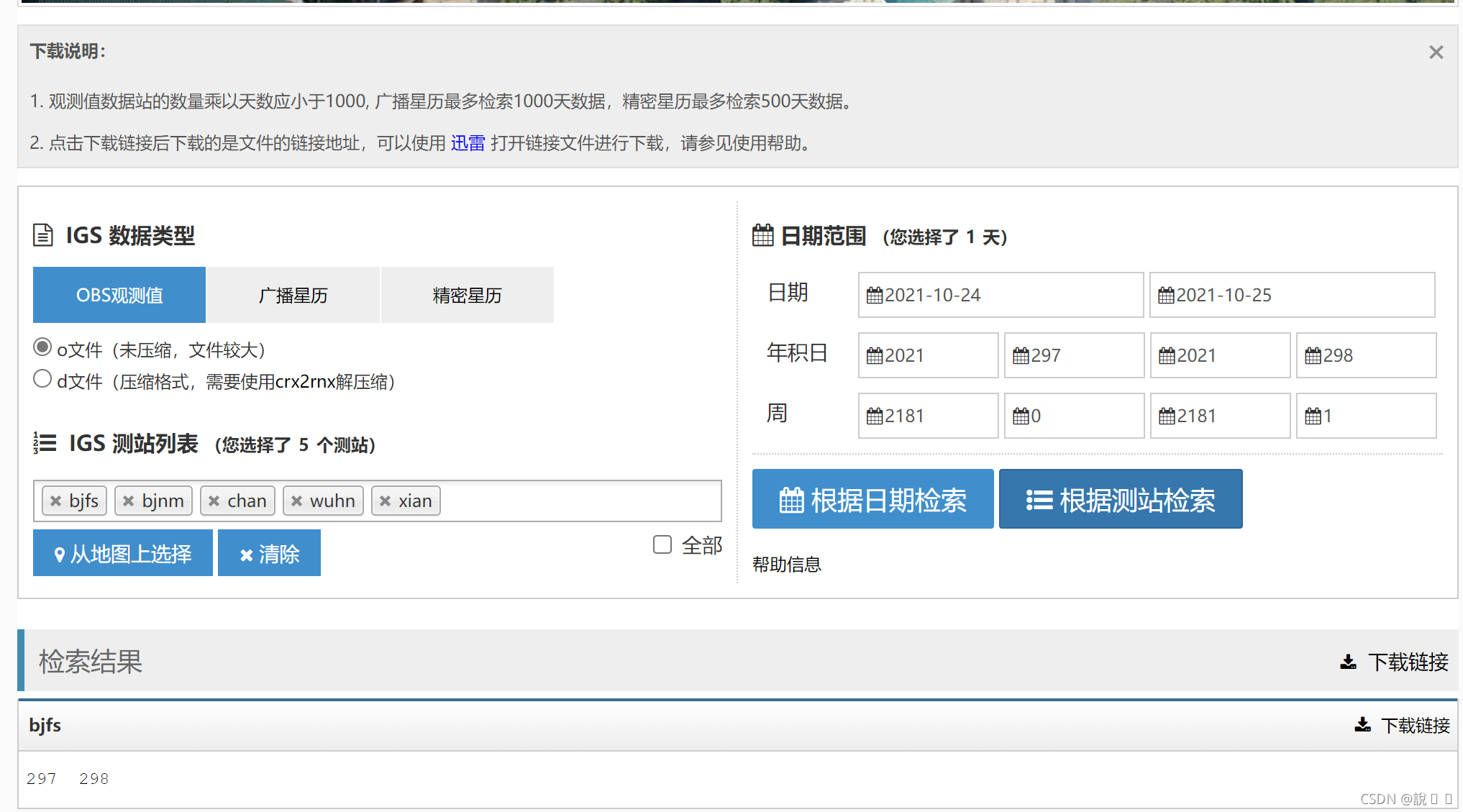
需求就是我要从这个网站里爬o文件和广播星历
武汉大学IGS数据中心
代码如下
import time
import urllib
from tkinter import *
import requests
from bs4 import BeautifulSoup
import os
import random
from tkinter.ttk import *# 假设是
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
}# 文件存储位置
dir = "E:\data"s = requests.Session()# 开始日期# igs观测站列表
select = []# 被选择的广播站
choose = ""def download(download_list, name):'''下载文件到指定位置:param name: 文件夹名称:param download_list::return:'''path = os.path.join(dir, name)# 如果下载路径不存在,则创建文件夹if not os.path.exists(path):# 创建文件夹os.makedirs(path)txt.insert(INSERT, "dir文件路径不存在,正在创建中\n")txt.insert(END, name + "下载开始,请稍等\n")for url in download_list:try:filename = os.path.join(path, get_randon_string() + get_filename(url))print("下载了--" + filename + "\n")urllib.request.urlretrieve(url, filename=filename)except Exception as e:txt.insert(END, "对不起下载失败--可能存在相同名字的文件名,或者网络问题")print(e)txt.insert(END, name + "下载结束\n")def get_randon_string():'''随机生成数字类型字符串:return: 随机字符串'''return str(random.randint(1, 50))def get_filename(url_str):'''根据url--获取文件名称:param url_str: url:return:'''try:return url_str[url_str.rfind('/') + 1:]except:print("文件名称寻找失败")return str(random.randint(1, 700)) + ".gz"def get_obs(choose, start_date, end_date):'''获取obs观测值:param choose: 选择:param start_date: 开始时间:param end_date: 截止时间:return:'''if choose.strip() == '':txt.insert(END, "选择的广播站错误\n")if not is_valid_date(start_date):txt.insert(END, "起始时间输入错误\n")if not is_valid_date(end_date):txt.insert(END, "起始时间输入错误\n")url = "http://www.igs.gnsswhu.cn/index.php/home/data_product/get_obs_data.html?src=IGS&start_date=" + start_date + "&end_date=" + end_date + "&sites%5B%5D=" + choose + "&order=site&format=o"data = s.get(url, headers=headers)if data.text.strip() == '':txt.insert(END, "广播星历没有任何数据\n")returnsubject = BeautifulSoup(data.text, "html.parser")download_list = []for item in subject.select(".site-item"):# 添加所有符合条件的下载地址temp = item.select("a")[0]["href"]download_list.append("http://wz-igs.oss-cn-beijing.aliyuncs.com/" + temp[temp.find('=') + 1:])# 开始下载download(download_list, "obs")def get_broadcast_ephemeris(start_date, end_date):'''获取广播新历:param start_date: 开始时间:param end_date: 截止时间:return:'''if not is_valid_date(start_date):txt.insert(END, "起始时间输入错误\n")if not is_valid_date(end_date):txt.insert(END, "起始时间输入错误\n")URL = "http://www.igs.gnsswhu.cn/index.php/home/data_product/get_brdc_data.html?src=IGS&start_date=" + start_date + "&end_date=" + end_datedata = s.get(URL, headers=headers)if data.text.strip() == '':print("广播星历没有任何数据")returnsubject = BeautifulSoup(data.text, "html.parser")# 下载链接download_list = []for item in subject.select(".am-success"):# 添加所有符合条件的下载地址temp = item.select("a")[0]["href"]download_list.append("http://wz-igs.oss-cn-beijing.aliyuncs.com/" + temp[temp.find('=') + 1:])# 开始下载文件download(download_list, "broadcast")def is_valid_date(times):'''判断日期格式是否正确:param times: 字符串的日期:return:'''try:time.strptime(times, "%Y-%m-%d")except:txt.insert(END, "输入日期的格式不合法哦,请重新检查\n")return Falsereturn Truedef calc(event):'''点击组合框的按钮:param event: 时间信息:return:'''global choosechoose = select[comb.current()]def init():'''初始化:return:'''url = "http://www.igs.gnsswhu.cn/index.php/home/data_product/igs.html"data = s.get(url, headers=headers)subject = BeautifulSoup(data.text, "html.parser")for item in subject.select("#sites-selector option"):select.append(item.text)start = "2021-10-01"
end = "2021-10-26"init()
root = Tk()
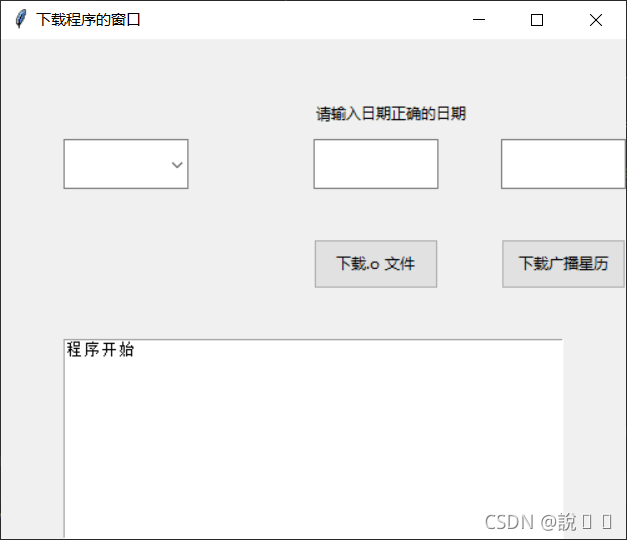
root.title('下载程序的窗口')
root.geometry('500x400') # 这里的乘号不是 * ,而是小写英文字母 x
lb1 = Label(root, text='请输入日期正确的日期')
lb1.place(relx=0.5, rely=0.1, relwidth=0.5, relheight=0.1)# 第一个输入框--起始时间
inp1 = Entry(root)
inp1.place(relx=0.5, rely=0.2, relwidth=0.2, relheight=0.1)# 第二个输入框---截止时间
inp2 = Entry(root)
inp2.place(relx=0.8, rely=0.2, relwidth=0.2, relheight=0.1)btn1 = Button(root, text='下载.o 文件', command=lambda: get_obs(choose, inp1.get(), inp2.get()))
btn1.place(relx=0.5, rely=0.4, relwidth=0.2, relheight=0.1)# 方法二利用 lambda 传参数调用run2()
btn2 = Button(root, text='下载广播星历', command=lambda: get_broadcast_ephemeris(inp1.get(), inp2.get()))
btn2.place(relx=0.8, rely=0.4, relwidth=0.2, relheight=0.1)# 复选框
comb = Combobox(root, textvariable="选择测试站", values=select)
comb.place(relx=0.1, rely=0.2, relwidth=0.2, relheight=0.1)
comb.bind('<<ComboboxSelected>>', calc)# 在窗体垂直自上而下位置60%处起,布局相对窗体高度40%高的文本框# scroll = Scrollbar(root)
# scroll.place(relx=0.1, rely=0.6, relwidth=0.8, relheight=0.4)
txt = Text(root)
txt.place(relx=0.1, rely=0.6, relwidth=0.8, relheight=0.4)
# scroll.config(command=txt.yview)
# txt.config(yscrollcommand=scroll.set)
# txt.pack()txt.insert(END, "程序开始\n")
root.mainloop()
结果如下