(一) 问题描述
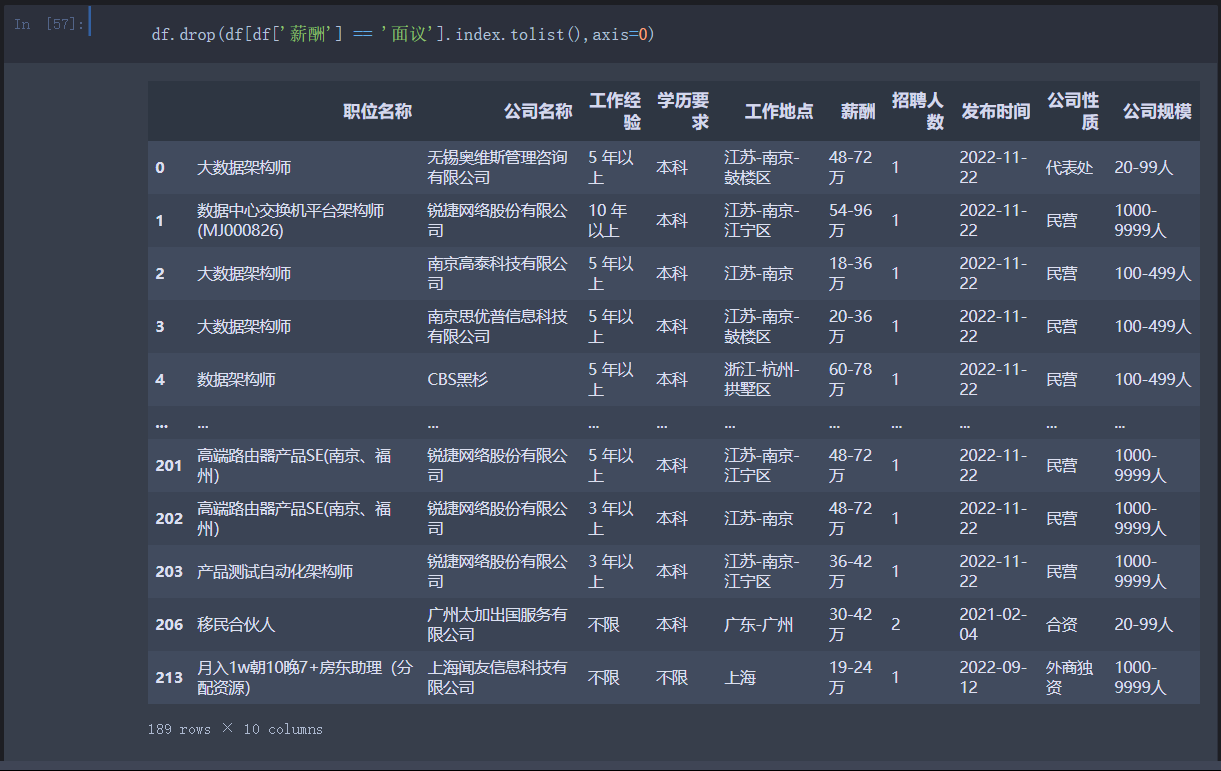
现有一招聘网站职位信息数据集, 数据集部分内容如下图所示, 现在我们需要的解决的问题是 该数据集中薪酬列有很多行填写的是 “面议”, 而一条招聘信息中包含有 “面议” 则没有参考价值 应当删去。那么我们如何将所有薪酬列为 “面议” 的行进行删除?
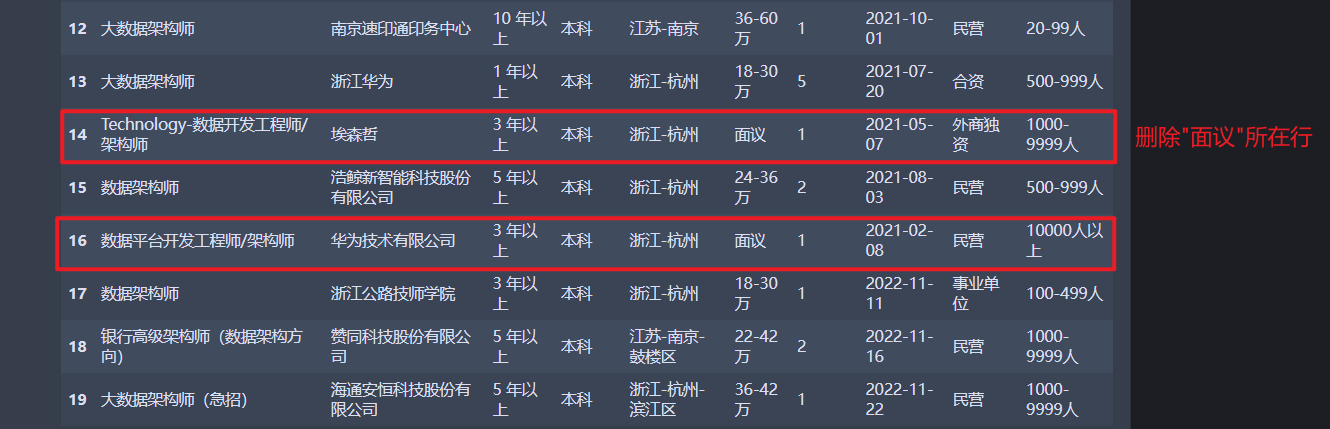
(二) 解决方案
import pandas as pddf = pd.read_csv('E:/Code/数据分析/data/InputData/zhilian_data.csv', encoding='gbk')
df.drop(df[df['薪酬'] == '面议'].index.tolist(),axis=0)
(三) 参考思路
1.判断 “薪酬” 列中哪些值为 “面议”
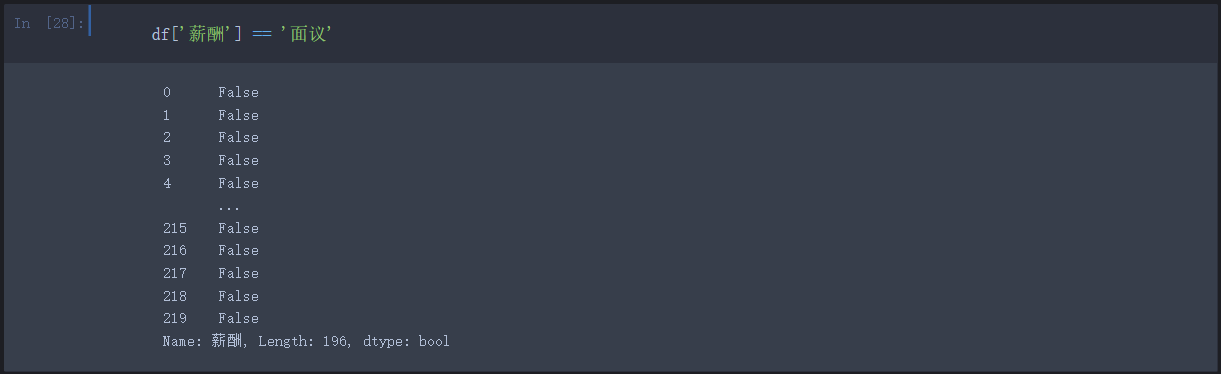
2.定位 “薪酬” 列中所有的 “面议” 值所在位置
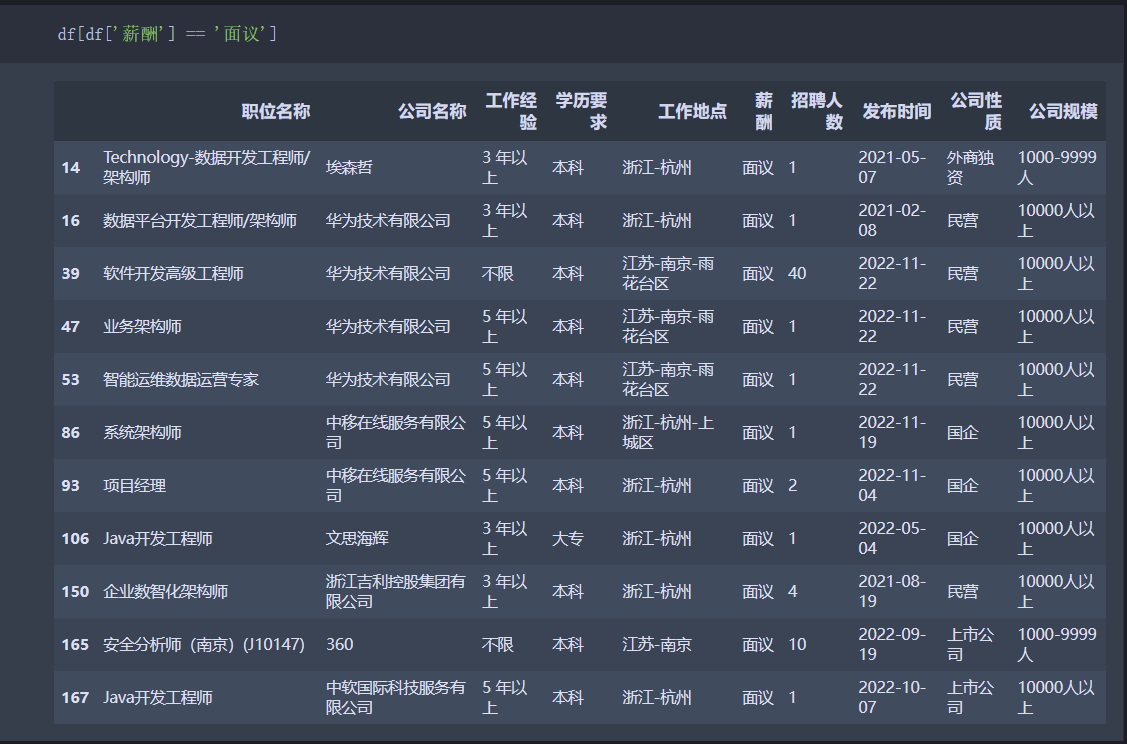
3.获取 “薪酬” 列中所有的 “面议” 值所在位置的行下标

4.将获取到的行下标转为列表类型

5.删除所有薪酬为面议的所在行 ( axis=0 表示删除行 )