爬虫项目实战
0x01 目标分析
最近发现一个比较好的欧美音乐下载网站,可以下载大部分高质量欧美音乐。该爬虫项目要实现自动化批量获取用户想要下载的音乐。本文从网站分析、爬虫设计、代码实现三个方面出发,系统介绍该爬虫项目。项目完整代码在Github中可以获得Github MusicDownload https://github.com/ctlyz123/MusicDownload
0x1 音乐搜索界面
在搜索页面输入想要音乐的名称,就可以搜索到类似的音乐。

分析搜索音乐的发送流程,在chrome中F12查看数据包内容
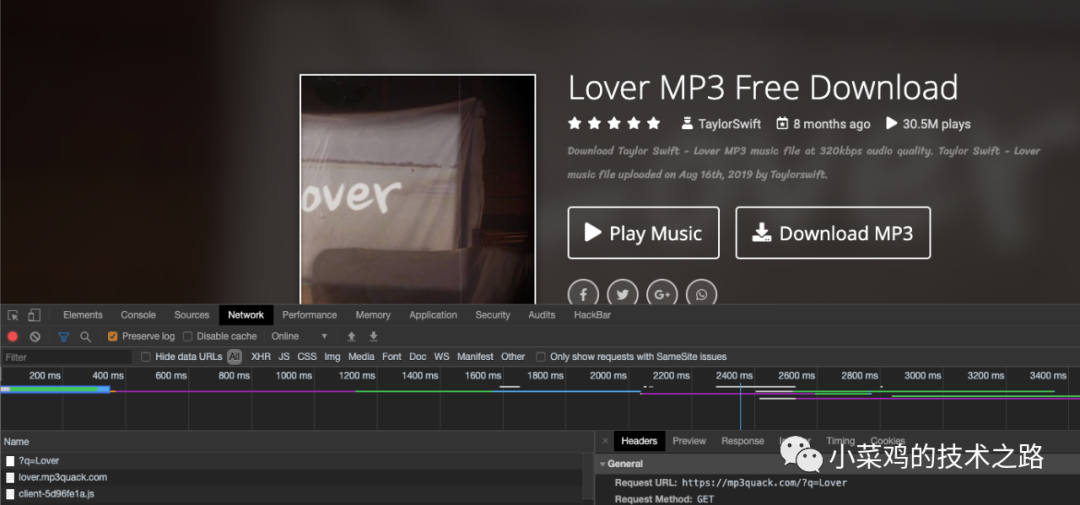
具体数据包内容如下,q参数为查询参数,向mp3quack.com发送请求
Request URL: https://mp3quack.com/?q=Lover
Request Method: GET
Status Code: 301
Remote Address: 127.0.0.1:1080
Referrer Policy: no-referrer-when-downgrade
与想象中不同的是回应包是个重定向包,重定向网址是音乐的介绍网址,内容如下:
location: https://lover.mp3quack.com/
pragma: no-cache
server: cloudflare
status: 301
taken-time: 2 ms
0x2 音乐下载界面
1 获取音乐编码
每个音乐下载界面都是https://mp3pro.xyz/ 加一串字符该字符的获取在音乐介绍网址对应上节就是 https://lover.mp3quack.com/

2 获取音乐token1
在本网站要有音乐token2和音乐code编码两个东西才能定位和下载音乐,但是token2的获取需要token1,所以首先要找到token1,获取token1的方法还是通过数据包中寻找,发现下面数据包
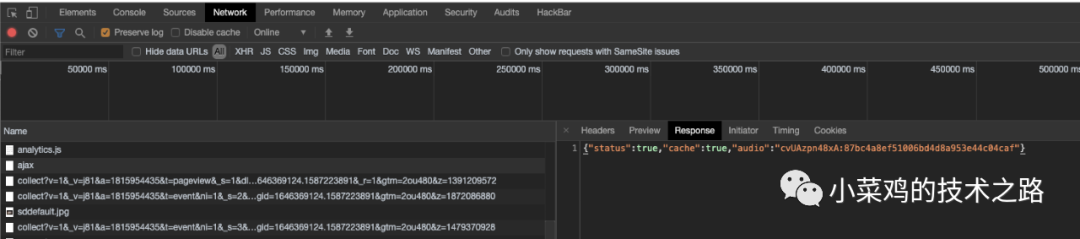
该数据包请求格式为
Request URL: https://mp3pro.xyz/ajax
Request Method: POST
Status Code: 200
Remote Address: 127.0.0.1:1080
Referrer Policy: no-referrer-when-downgrade
purpose: audio
token: cvUAzpn48xA:e70b1595e566ec841c9a11f920ac5b5b
最终在https://mp3pro.xyz/cvUAzpn48xA 网页源码找到token内容

有了token1就可以获取token2了通过https://mp3pro.xyz/ajax 处理的响应包为
{"status":true,"cache":true,"audio":"cvUAzpn48xA:87bc4a8ef51006bd4d8a953e44c04caf"}
0x3 获取下载网址
通过token2 发送 如下请求即可获取网址
Request URL: https://mp3pro.xyz/ajax
Request Method: POST
Status Code: 200
Remote Address: 127.0.0.1:1080
Referrer Policy: no-referrer-when-downgrade
purpose: download
token: cvUAzpn48xA:87bc4a8ef51006bd4d8a953e44c04caf
f: 0
d: 0
b: 320
c: 1
r: https://mp3pro.xyz/cvUAzpn48xA
在上面的数据请求中需要获取音乐编码和音乐token2,我们现在都以具备,看一下响应包:
{"status":true,"mp3url":"http:\/\/nl04.mp3pro.xyz\/7cb1bf3c5a39d7223b3d0\/Taylor%20Swift%20-%20Lover.mp3"}
响应包中的mp3url就是音乐的下载链接
0x02 流程设计
有了上述的简单分析,我们初步可以实现单个音乐的下载,本节设计代码结构,利用一些设计方法和思想,把大概框架梳理一下。
0x1 模块梳理
按照功能划分模块,本文想要实现的是一个多线程大批音乐链接获取和下载功能。
音乐下载链接生成模块
音乐下载模块
多线程模块
综合管理控制模块
为了方便后期扩展,在各个模块之间采用的依赖关系,相互关系如下
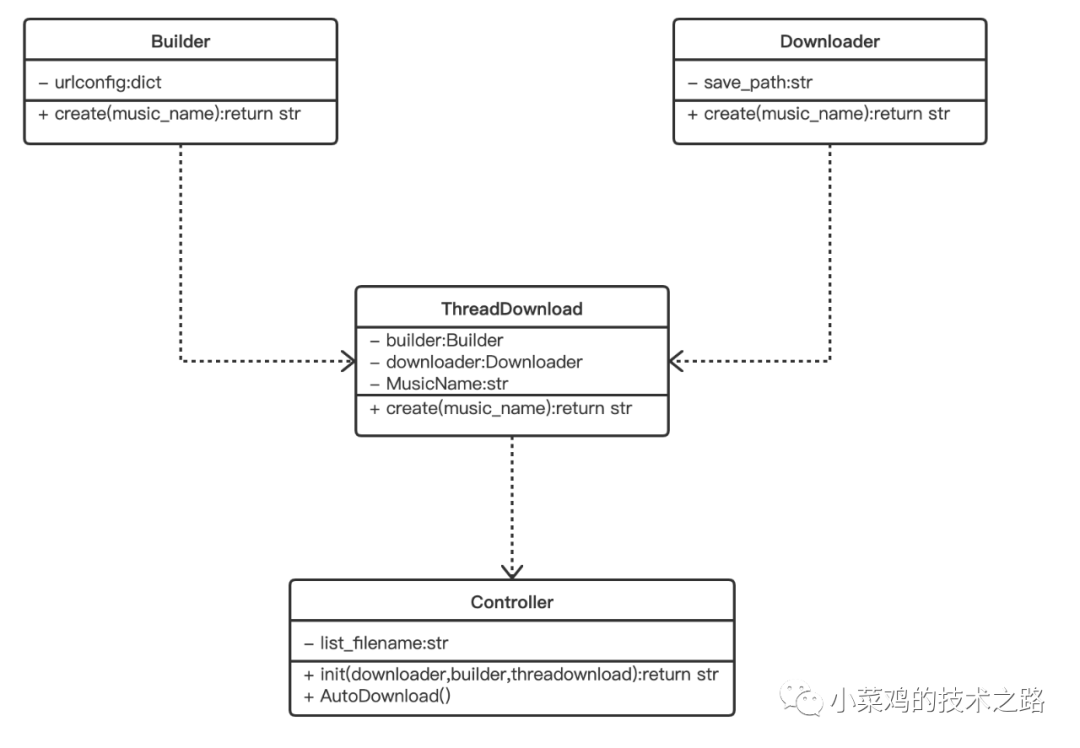
在main.py中向controller模块传递一个模块类和两个模块对象,实现模块的整合。整合代码和模块内容在代码实现中讲解。
0x2 配置文件
为方便配置,将配置以json的格式存储,利用Utils模块进行配置文件加载 配置文件格式如下:
{
"Url": {
"Main_url": "https://mp3quack.com",
"Mid_url": "https://mp3pro.xyz"
},
"Dir": {
"Save_Path": "Music"
},
"File":{
"MusicList": "Config/MusicList"
}
}
相关加载代码
def loadconfig(filename):
import json
json_data = {}
with open(filename) as f:
json_data = json.load(f)
return json_data
0x03 代码实现
分模块进行介绍,主要包含
链接生成模块
多线程模块
下载模块
综合管理模块
在这之前先看下主函数整合逻辑
0x1 main.py
# -----------------load config--------------------
configpath = "Config/config.json"
configs = loadconfig(configpath)//加载配置文件
dir_config = configs["Dir"]
file_config = configs["File"]
# -----------------create classes--------------
builder = Builder(configpath)
downloader = Downloader(dir_config["Save_Path"])
controller = Controller(file_config["MusicList"])
# ----------------auto download----------------
controller = controller.init(downloader,builder,ThreadDownload)
controller.AutoDownload()
代码比较简洁,分为三个步骤 加载配置文件、创建类和对象、生成链接下载器
0x2 链接生成模块
主要分为四个步骤 获取音乐码、获取token1、获取token2、获取链接
1.获取音乐码
search_url = "%s/?q=%s"%(self.urlconfig["Main_url"],quote(music_name))
content = requests.get(search_url).content
Music_code = re.findall("vi\/(.*)\/maxresdefault\.jpg",str(content))[0]
获取配置文件中Main_url字段,访问查询页面,利用正则匹配找到对应的音乐code
2.获取token1
mid_url = "%s/%s"%(self.urlconfig["Mid_url"],Music_code)
content = requests.get(mid_url).content
m_token = re.findall('token":"(.*)","verify"',str(content))[0]
访问配置文件中Mid_url链接,将获取的music code加到链接里面,通过正则寻找token位置和内容。
3.获取token2
data = {
"purpose": "audio",
"token": m_token,
}
req = requests.post("https://mp3pro.xyz/ajax",data=data)
res_json = json.loads(bytes.decode(req.content))
code_token = res_json["audio"]
带着token1访问ajax接口,利用json格式解析返回的内容,取出audio字段。该字段中存储着token2的值。
4.获取链接
data = {
"purpose":"download",
"token":code_token,
"f":0,
"d":0,
"b":320,
"c":1,
"r":"https://mp3pro.xyz/{}".format(code_token.split(":")[0])
}
req = requests.post("https://mp3pro.xyz/ajax", data=data)
res_json = json.loads(bytes.decode(req.content))//json解析response
再次利用ajax请求,将post数据设置为上述格式就可以获取到下载链接了,效果图如下
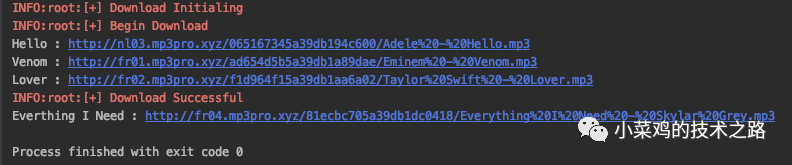
0x3 多线程模块
def __init__(self,builder,downloader,MusicName):
self.builder = builder
self.downloader = downloader
self.MusicName = MusicName
def run(self):
Musicurl = self.builder.create(self.MusicName)
print(self.MusicName.strip(),":",Musicurl)
# self.downloader.download(Musicurl,self.MusicName)//下载音乐
利用依赖的方式调用各个模块,注释的一行可以从链接中下载音乐内容。
0x4 下载模块
req = requests.get(url,stream=True)//采用流模式
with open(os.path.join("Music",MusicName+".mp3"), "wb") as f:
for chunk in req.iter_content(chunk_size=512):
if chunk:
f.write(chunk)
采用requests数据流模式,分块下载数据,每次下载chunk_size大小
0x5 综合管理模块
def AutoDownload(self):
MusicsName = readfile(self.list_filename)
logging.info("[+] Begin Download")
threads = []
threadPool = ThreadPoolExecutor(max_workers=10)//设置线程数
for MusicName in MusicsName:
thread = self.treadownload(self.builder,self.downloader,MusicName.strip())
threadPool.submit(thread.run)//注册线程函数
threadPool.shutdown(wait=True)//等待所有线程
logging.info("[+] Download Successful")
第五行利用ThreadPoolExecutor设置线程池大小为10,也就是最多有10个线程同时运行。第8行,注册线程中的主函数,也就是音乐链接和下载功能。
0x04 总结
本文通过分析音乐网站的下载方式,梳理单个音乐下载方法,设计代码结构模块,采用依赖方法将各个模块整合一起,实现多线程多音乐链接获取和下载功能。这里的核心在于token1和token2的获取和利用方面,其次是设计代码模块和衔接模块。希望大家能通过本文学习到关于python和爬虫的相关知识。
Usage:将要下载的音乐写在Config文件夹中的MusicList里面按照这种格式,执行main.py就会自动生成下载链接。
Lover
Hello
Venom
Everthing I Need