本文最早发表在我的个人博客上,转载请保留出处 http://jsorz.cn/blog/2016/11/node-action-in-website-detection.html
(这是拖了近一年的文章。。。)去年这个时候接了一个心力交瘁的项目,大体目标是:1、为用户的网站提供安全监测的服务,用户在我们的管理端系统中添加一个站点并勾选要检测的项;2、然后由后台爬虫系统完成用户站点链接的入库,并定时针对站内链接执行各种检测任务;3、再由前端系统给用户交付网站监测报表。在中间这一步,最重要的爬虫系统,我第一次学习用 Nodejs 来做。
Node起步
安装
-
nvm
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.25.2/install.sh | bash -
node 0.12.x
nvm install 0.12 -
cnpm 镜像
npm install --registry=http://r.cnpmjs.org -g cnpm -
debug 工具
cnpm install -g node-inspector node-debug yourApp.js
教程
Node.js 包教不包会
中文API文档
一些库
-
用于爬虫
superagent 处理请求的模块
request 另一个处理请求的模块,比起 superagent,语法配置项更多一些。如果说 superagent 是
$.post(),那 request 就是$.ajax()cheerio 用于DOM解析,提供与 jquery 选择器类似的接口
-
异步流程控制
Q in Github Promise 化的一种实现,promise 不是万能,改造复杂的动态决定的执行链是比较烦的事情
async 点赞数很高的库,有人说有毒,我觉着很好用
eventproxy @朴灵的基于事件的流程控制,我觉着和 promise 或 async 搭配着使用很好用
主程序设计
在摘要中已经提到,这个项目的目标分为3步:添加检测任务 => 爬虫执行任务 => 前端报表展现。但在具体实现时,需要对爬虫进行细分,最终会有6步过程。
1、添加要监测的站点

在web端添加一个站点任务,输入客户的摘要信息以及要监控的站点列表,然后可以更改检测类别的周期以及具体检测项等配置。


“可用性”检测主要是网站的一些基本信息,通常都在首页的 http 头中就能找到。而“内容检测”需要对网站中的所有页面进行检测,因此会有一个“检测深度”和“最大页数”的配置,页面深度越深,页面数目会呈指数级增长,这对爬虫服务器是巨大的压力。
此外还有一个“安全检测”的模块,具体检测项有:ActiveX挂马,iframe挂马,js挂马,WebShell后门,暗链,以及后台地址检测。由于我对安全方面了解太少,在这个系统中实现得也很simple,就不多说了。。。
2、站点入库
由于上面“内容检测”和“安全检测”都需要对网站首页下的其他页面全部检测,因此我们需要维护一个 site 表和 site_link 表,记录下网站的域名和 ip 信息,并且存下每个页面链接的信息,包括该页面相对于首页的深度层级,该页面的链接是 同源、同域 还是 外链,以及页面的发现时间、状态信息等。
另外注意的是,从首页开始取链接,然后再对链接再取它的后继链接,整个过程应采用“广度优先”的策略。而“检测深度”和“最大页数”也是在这个时候进行限制的,如果当前页面深度为 N,N + 1 > 检测深度,那么该页面就不再往爬取队列中 push 后继链接了。
3、周期性生成检测任务
站点任务配置完,站点链接也入完库,这时候就可以根据上面配置的检测周期来定时产生任务。例如当内容检查的周期到来时,需要取出该站点下所有符合的页面链接,对每个页面的每个检测项都生成1个检测任务。
需要注意生成任务时,要按照页面链接的顺序来遍历,而不是先遍历检测项。这样的好处是当具体爬虫执行时,相同 url 的检测任务在队列中会连续挨着,这样可以给爬虫做爬取的合并,同样的 url 只需要爬取1遍,就可以给不同的检测任务去执行。
4、爬虫执行检测任务
如果说第3步生成任务是“生产者”,那么现在就轮到“消费者”。爬虫系统要支持并发,多机器 + 多线程。在1台机器上,1次从任务队列中取100个出来,如第3步所说检测任务是按相同url连续排列的,那么这100个检测任务可以抽出20个任务组(举个例子),每个任务组都可以只爬取1个页面,然后将内容传递给各检测项去执行。而每个检测项的执行结果都以 log 的形式存储。
如果爬虫的机器不是那种“树莓派”微型机器,那可以先将 log 以文件形式存到本地,留出带宽给爬虫。或者每个检测项的结果 log 都发送到1个指定的地方,这就会多占用带宽,也需要专门搞1台日志服务器。
5、定时计算日志
爬虫的任务执行过程是很连续又很离散的,连续是因为做完1个就要做下1个,离散是说日志的离散,单独1个页面的1个检测项的1次执行日志并没有太大意义,要整合到整个站点和时间段、检测类别的维度来看才有价值。从前面的步骤可以看到,站点链接的入库以及周期性的生成任务时,会有一定的“顺序”控制,并且只有全部入完库才会进入下一步骤。而爬虫系统是很离散的,它可能分布到多台机器上,只要任务队列中有东西,它就会取出来执行,也不会区分任务是来自哪个站点哪个类别的。
因此,如果 log 分布在各爬虫机器上,那就需要一个定时的脚本对其进行汇总计算后传回数据中心。而如果有统一的日志服务器,那同样需要将原始日志计算成有效的数据。
6、前端报表查询
前端系统直接查数据中心,可以得到站点级和检测类别级的报告。前面“生产者”生成检测任务时,会在数据库中打上一些任务模块的时间信息,前端系统也能够查到一些调度状态信息。
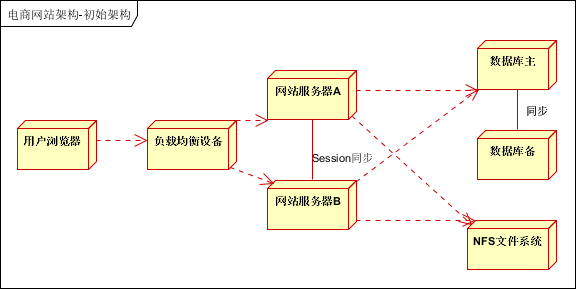
架构图
整个系统分为4个部分:前端系统、任务Producer、爬虫系统、日志计算同步进程。架构图如下,可以看到箭头就代表着数据流的方向。

而爬虫调度和执行是典型的“生产者-消费者”模式,这里生产者只有1个,而有N个消费者爬虫进程。

所谓的检测任务队列,实际就是数据库中的一张表,多个爬虫进程或多台爬虫机器都共享这张表,只要保证从表的顶部开始读取,读完后就要重置状态位,防止被其他进程重复读取。而当任务执行失败后,会将该检测任务的记录移到 table 的队尾,并设置1个失败次数的字段。
爬虫实现思路
技术框架
在本文第一节中就列出了一些库,在页面爬取方面,使用 superagent 获取页面内容,使用 cheerio 做文档解析。而对于一些不需要解析内容的爬取任务(比如查询某个页面的 header 信息,或是检查某个页面是否 200 状态),使用 request 来发请求。
对于爬虫系统中最关键的异步流控制,我在实现时做了多种风格的尝试,在数据库读写层面使用 promise 风格,在检测项内部使用 async,而在爬虫的实例中使用 eventproxy 来进行流控制。
目录结构
base/ 跟继承和通用相关的
conf/ 各种配置项(检测项的配置、规则的配置)
constant/ 各种常量的定义和配置
database/ 数据库配置和连接池
models/ 数据库表对应的 json schema
dao/ 与 model 相应的 Dao 增删改查封装
util/ 通用数据的helper
factory/ 工厂封装类,统一任务的组建过程
-
modules/ 具体检测项 (爬虫上搭载的具体task实现)
basic/ 基础信息 可用性检测
content/ 内容检测大类
secure/ 安全检测大类
common/ 站点入库、链接入库,以及抓取页面内容也抽象成1个通用task
crawler/ 爬虫对象与池管理(1个crawler实例只负责1次页面请求)
-
scheduler/ 监控和调度进程 (每隔一段时间就执行一轮)
runner.js 用来执行检测任务 (任务消费者)
siteRunner.js 针对“站点链接入库”的 runner
app.js 主程序,用来启动 runner
appSite.js 主程序之一,用来启动 SiteRunner
appPath.js 用来启动低频高请求量的检测任务(详见下面的地址型检测类)
爬虫实现流程
由上面的结构可以看到,程序运行时的调用过程是:app.js => runner.js => crawler => 具体检测项。
app.js
其中 app.js 只是个程序入口,里面构造了一些参数给 runner,代表性的参数有:runner 每轮执行时取出的任务数量(即1个消费者每次消耗的数量),以及每轮执行之间的间隔时间(因为执行1轮任务时会有 N 个请求,如果不做间隔时间的限制,同时等待请求响应的线程太多会爆)。
runner.js
runner.js 首先提供1个支持间隔时间的循环执行接口,这里使用 async 库来实现。
RunnerBase.prototype = {start: function(){var that = this;that._count = 0;async.whilst(function(){if(that.loopCount){return that._count < that.loopCount;}return true;},function (callback){// 第一次立即执行if(!that._count){that._count = 1;that.run();callback(null, that._count);}else{that._count++;setTimeout(function(){that.run();callback(null, that._count);}, that.loopInterval || 10000); // 默认10秒间隔}},function (n){console.log('Runner with [n=' + n + ']');});}
};而 runner 中的run()方法就是每轮具体要执行的操作,它其实整体是个串行过程,有以下步骤:
1、取出数据库中的任务队列中靠前的 N 个任务
2、如果取出为空,直接跳到第6步
3、将任务状态标为
PROCESSING4、对 N 个任务按检测的 url 重新分组,比如得到 M 个组,则构造 M 个 Crawler 实例(这里设计的准则就是1个 Crawler 实例只爬取1个页面)
5、使用
async.parallel并行执行 M 个 Crawler 的run()方法6、一轮 runner 执行结束
这里整体是串行,使用了 eventproxy 来进行流程控制
Runner.prototype.run = function(cb){var that = this;var ep = new EventProxy();// 统一错误处理 TODOep.fail(function (err){console.log(err);});// 各步骤一起调用,通过 event信号 等待Runner.steps.forEach(function (fn){fn.call(that, ep, cb);});
}而其中最关键的步骤是并行执行 M 个 Crawler,其实现原理如下
function (ep){var that = this;ep.on('crawlerReady', function (crawlers){// 构造 async.parallel 的执行函数var threads = crawlers.map(function (crawler){return function (callback){// run前的累计that.crawlerCount++;crawler.run(function (err){// run完的累计that.crawlerCountDone++;if (err){console.log(err);callback(err);} else {callback(null);}});}});async.parallel(threads, function (err, res){console.log('[OK] 并行Crawler[len=' + threads.length + ']执行完毕');});// 这里释放信号不能放在 async.parallel 的回调里,以防有爬虫挂了就卡死了// 直接到最后1步,可在每轮的最后看到爬虫累计的页面数目,and 爬虫监控池 TODOep.emit('crawlerDone');});
},function (ep, cb){var that = this;ep.on('crawlerDone', function(){console.log('[OK] 消费者1轮, ' +'累计爬了 ' + that.crawlerCount + ' 个页面, ' +'累计结束 ' + that.crawlerCountDone + ' 个页面');cb && cb();});
}crawler.js
上面已经提到了多次:1个 Crawler 对象只负责 1次 页面请求,在 Crawler 对象中主要记录着分组后的任务数组,它们有着同样的目标 url。先请求页面 url,得到页面文档后将内容依次传递给各检测项去各自执行任务。所以总的来说,这里也是一个串行过程,具体步骤如下:
1、将分组后的任务,通过任务类型的 key,反射到具体的类,得到可执行的任务对象的数组。
2、调用请求页面内容的通用检测项,作为 starter
3、将页面内容的文档作为 context 入参,依次调用各任务对象的数组
4、任务全部完成后,在数据库中将其移出队列;若失败,则先移除,计失败次数+1,然后重新插入队尾
这里也是用 eventproxy 控制流程的,其中关键的 context 传参调用各任务对象,实现如下
function (ep){var that = this;// 使 task.run() 结果按顺序排列ep.after('oneTaskFinished', that.tasks.length, function (results){ep.emit('allTasksFinished', results); });ep.on('starterFinished', function (context){that.tasks.forEach(function (task){task.run(context, ep.group('oneTaskFinished'));});});
},注意,使用 ep.group() 方法可以保证得到的执行结果的顺序是与调用顺序一致的,而各 task 的执行是并行的。
检测项工作模式
反射原理
在上面讲 crawler 的第1步中提到:将分组后的任务,通过任务类型的key,反射到具体的类。因为从数据库任务队列取来的检测任务只会含有 模板url / 检测大类 / 检测项小类 这样的数据,所以就要反射到具体的检测类来构造对象。
“反射”是强类型编程语言中的概念(我最早是在 Java 中了解的),而 js 天然的弱类型和动态特性,很容易实现。
// 根据命名规则,取检测模块的引用
getModuleFromCrawlTask: function(crawlTask){var modulePath = ModuleConf.getPath(crawlTask['item_key']);return require(modulePath);
}这里每个检测项任务都会带有 item_key 字段,表示具体的检测项,其实还有 mod_key,对应到系统的3大类检测:可用性,内容检测,安全检测。具体见下一段。
检测项分类
// 表明这个TaskItem属于哪一大类 (通用的除外)
var modDict = {COMMON_CRAWL: 'COMMON_CRAWL', // 通用爬取方法 如请求页面document, 取链接等BASIC_DETECT: 'BASIC_DETECT', // 可用性检测CONTENT_DETECT: 'CONTENT_DETECT', // 内容检测 合并了篡改检测SECURE_DETECT: 'SECURE_DETECT' // 安全检测
};// 表明这个TaskItem能否与其他合并, 能否共用1次请求
var typeDict = {EXCLUSIVE: 'EXCLUSIVE', // 排它性 (独占 request 的任务)INCLUSIVE: 'INCLUSIVE' // 可合并性 (只需传递 context)
};// 表明这个TaskItem应该在哪个表中, 应该交给哪个Runner处理
var runnerTypeDict = {COMMON: 'COMMON_TASK', // 普通任务 -> Runner -> app.jsSITE: 'SITE_TASK', // 站点入库类 -> SiteRunner -> appSite.jsPATH: 'PATH_TASK' // 路径检测类 -> Runner -> appPath.js
};这里定义了两种表示任务属性的类型:INCLUSIVE 表示该任务是可以与同目标 url 的其他任务合并的,只需要请求1次页面,传递页面内容的 context 即可,详见 crawler.js 的部分实现代码。而 EXCLUSIVE 表示该任务内部要自己发请求,比如查 Whois 信息,或者要检测是否存在某些后门路径,这类任务是不可以合并的。
而 runnerType 又是另一个层面的另一种分类,在第二节主程序设计中提到过站点链接入库。我在实现时做了一层抽象,将“站点入库”和“链接入库”也视为一种检测项任务,任务放在单独的一个队列表中。这样就能共用一些 crawler 和 runner 的逻辑。
此外对于路径类检测,比如 Webshell 地址检测,或是敏感路径检测,由于规则的字典很大,1个检测项可能会有上千次请求。因此对于这类“低频”又“高请求量”的检测项,我也单独将任务放在另一个独立的队列表中,也由另一个程序入口启动。
并行与管道
总结整个爬虫调度与检测项的工作流程,是“串行”与“并行”同时存在着。

由 runner 执行时每轮会取出一堆任务,生成多个 crawler 实例,这是并行的。而在每个 crawler 内部可以理解为像工厂的流水线模式,先请求页面 url,然后将页面内容一个个传递给各检测项去完成相应的提取或检测工作。每个检测项内部都会去写各自的 log 文件,最后所有检测任务都完成后,间隔一段时间后会进入下一轮 runner 的执行。
注意的是,检测项是根据目标 url 来分组的,搭载在 crawler 实例上执行的,同一组的检测项都执行完后,相应的 crawler 实例也应该销毁。而 runner 对象的实例是始终存在的,它像一个定时器一样每隔十来秒就会再触发1轮执行。同时,1个 runner 实例应该对应1个进程,多个 runner 实例应该跑在多台爬虫服务器上。
总结与不足
这个项目从去年11月开始需求分析,做界面 demo,到任务分解和组装过程的设计,再到爬虫的实现,也是从零开始学 nodejs,整个过程最初都只有我1个人,对自己的挑战提升很大。熬了两三个月后才有人手帮我做日志的回收计算以及前端的报表部分,之后项目就交给他们了,他们后来做了一些安全检测项方面的强化以及多机器的部署和通信。
我在单机(Mac Air Book @ 2012)上运行的效率平均1小时,爬取近1万个页面,并完成剩余的内容检测项部分。在前面图中一轮取出的任务数量以及并行 Crawler 的数目,对机器的性能和网速都有要求,如果入不敷出(每轮间隔时间内都只有少数的 crawler 执行完),最终会产生很多内存错误,或者 TCP 连接数过多,也得不到结果。
我尝试后得到的经验参数是,每隔 10 秒,取 50 个任务,根据目标 url 合并完后大约有 20~30 个任务组。注:用的是云服务器,内存 2G,带宽 2M。
还是简单粗暴
这个爬虫系统和检测项都还比较简陋,可以从以下方面改进:
nodejs 的 cluster 尝试,能否对爬取效率有性能提升
数据库“同步写”的锁问题,多台爬虫机器共用同一个数据库的任务队列,有性能瓶颈(或者说集中式存储的通病)
内容检测方面的篡改识别算法,目前仅用 content-length 和 md5 来判别页面更改
引入 phantomJS 来做网页截图,警示页面恶意篡改
加强安全检测方面的力度,对各种挂马和暗链的代码模式的识别
支持对检测项的扩展,能让更有经验的安全工程师编写的 python 代码也接入到系统中
TODO
在开发过程中还记录了一些遇到的问题,nodejs爬虫实现中遇到的坑 后续会慢慢整理补充
有时间再抽象出一个业务无关的可配置的“生产者-消费者”模式的网站检测框架,供学习交流
本文最早发表在我的个人博客上,转载请保留出处 http://jsorz.cn/blog/2016/11/node-action-in-website-detection.html