电力图像分类最典型的场景就是安全帽佩戴识别。
针对电网作业现场人员行为的图像数据,采用目标检测、图像识别等人工智能技术,对电网作业现场人员是否规范佩戴安全帽进行检测识别。通过计算平均精确率、漏检率、误检率、平均计算时间等指标进行评测。
任务拆解
输入是图像数据,没有文本、语音等其它数据。
可将问题拆解为图像识别、目标检测、图像分类等任务。
具体是谁没有佩戴安全帽就需要用到人脸识别。
安全帽有佩戴要求和规则,我们需要去标注数据来匹配这个规则:帽子带在头上;帽子固定扣是否扣住。
对帽子带着头上数据标注的时候,同时标注帽子在头上带的作为正样本,还要标注只有帽子、只有脑袋的负样本,正负样本最好还是在电网作业现场这种场景下。
我们没有那么多不规范的数据,也没有那么多时间去标注数据。所以本文 问题简化为识别是否佩戴,问题转换为一个图像的二分类问题。
深度学习框架
深度学习框架:tensorflow(比较重)/pytorch(其次)/paddlepaddle(最好用)
很多人工智能开源的项目tensorflow(比较重)/pytorch(其次)这两种实现,也有paddle的实现,如果没有,我们可以参考这个paddle的规范把pytorch代码迁移过来,工作量不大。
常规安全帽检测流程
一. 准备数据
准备数据要注意场景匹配;如果标注数据的场景和实际使用的场景不一样的话,会有新的干扰因素影响你的准确率。
正负样本数据量要注意平衡的问题,如果正样本标注1万,负样本标注20万,让人工智能去分类,人工智能就会偷懒,我全部都识别为没有带安全帽就好了。
单纯的图像采样效果有限,我们最好做多种类型的数据增强。常见的数据增强mixup、cutmix,都是很规则的矩形边界。snapmix这个可以实现非矩形图像的切割填补等处理,对提升准确率有很大帮助。
数据需要做预处理:数据格式转换(目录结构、标签文件)、图片大小统一。
数据标注的数据质量问题可由数据标注质检人员完成,但成本高,cleanlab可以实现错误标签自动筛选。
二. 数据标注
要做目标检测,把我们要找的东西在图片上面自动框出来,才需要做框图标注,如果只是单纯的做图片分类,是不用画框标注的,比如,对鸟类做分类的话,但是把各类图片分门别类放到目录上去,也算是数据标注。
数据标注,准确率要求不一样,可能标注的方法也不一样,常见的我们就拉四边形的框,但是有的时候,我们可能要多边形。
voc是一种数据规范的格式,这个规范的格式一般来说,包含目录结构、标签文件的格式要求。
三. 选择模型
常规是目标检测+图像分类,图像二分类能选的模型比较多,重点考虑:准确率、处理速度、模型大小(主要考虑将来产品化了,这个模型的运行环境),作为练习来说,我们基本上考虑准确率、召回率就可以了。
往往会选择多个模型去比较,并且做模型融合。
四. 训练模型
训练前,做shuffle洗牌对图片数据做打乱处理。
图片数据按照训练集、验证集、测试集划分,8:1:1。
开始训练,不断改进,提升效率,调参,是人工智能训练师、调参侠表演的时刻了,调参也可以用工具自动搜索最好参数:自动调参工具NNI。
还有一点特别重要的,如果你不是专业学人工智能CV,你不要花太多时间去研究模型的改进,你就选择市面上效果最好的模型就可以了。(这里我暗讽一下浙江大学孟伟,他的课题就是模型改进,发不出论文,菜是原罪)
五. 模型评估
通过计算平均精确率、漏检率、误检率、平均计算时间等指标进行评测。
进阶学习
如果大家需要进阶研究学习,可以多去研究学习kaggle、天池上面的相关的竞赛,这上面经常会有很多创新的模型、算法。
kaggle:全球最顶级的人工智能竞赛平台。https://www.kaggle.com/
天池:阿里提供国内最顶级的人工智能竞赛平台。
本次开发任务
找到训练好的安全帽检测预测模型,在本地运行起来。
把这个模型封装成可调用的类。
用flask搭建网站来调用我们封装好的类实现在线安全帽检测预测业务。
flask网站
轻量级的web框架,本身采用jinja2模板,这个模板的作用是可以将我们的html代码和数据融合到一起。
@app.route('/xxx')做路径映射(这个映射的就是/xxx这个路径和一个对应函数的映射),我们正常是访问到127.0.0.1:5000/ (这个斜杠代表根目录),所以写路径的时候,一定是/开头的,然后这个@app.route会自动绑定到它最近的这个函数上,所以@app.route里面路径和函数名不一定要完全一致,但是我们一般写成一致,是出于命名规范。函数就是我们常见的函数,是完全一样的。
flask 接受前端参数的几种方式:
# GET,url参数
path = request.args.get("imgPath")
path1 = request.values.get("imgPath")
# POST,数据包参数
path2 = request.form.get("imgPath2")
path3 = "dd" # request.get_data().get("imgPath2")
path4 = request.get_json()path5 = request.get_data()
path6 = request.headers["Content-Type"]
api封装
简单粗暴的方法,就是用subprocess直接模拟命令行调用的方式,这种方式好处是简单,干净利落,不用import,所有的麻烦事都交给命令行环境去处理。
引入包的方式,这种方式比较精准,也不算麻烦,但是得看你用的东西的作者是否给你足够的示例代码。
直接把项目的源代码整合到我们的flask项目里面,作为其中的模块来使用,这个比较麻烦,会引发一些包路径的问题。
代码实现
https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/docs/zh_CN/models/PULC/PULC_safety_helmet.md
该案例提供了用户使用 PaddleClas 的超轻量图像分类方案(PULC,Practical Ultra Lightweight image Classification)快速构建轻量级、高精度、可落地的“是否佩戴安全帽”的二分类模型。该模型可以广泛应用于如建筑施工场景、工厂车间场景、交通场景等。
#安装 paddlepaddle
pip install paddlepaddle#安装 paddleclas
pip install paddleclas如果安装失败就下载源代码,进入代码目录,执行:python setup.py install进行离线安装。
下载样本来测试:
https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip
safety_helmet_test_1.png

safety_helmet_test_2.png

paddleclas --model_name=safety_helmet --infer_imgs=pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png[2022/10/18 21:26:47] ppcls INFO: class_ids: [1], scores: [0.9986255], label_names: ['unwearing_helmet'], filename: pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png
[2022/10/18 21:26:47] ppcls INFO: Predict complete!safety_helmet_test_1.png预测出的标签是:unwearing_helmet。
paddleclas --model_name=safety_helmet --infer_imgs=pulc_demo_imgs/safety_helmet/safety_helmet_test_2.png[2022/10/18 21:27:41] ppcls INFO: class_ids: [0], scores: [0.9977983916178346], label_names: ['wearing_helmet'], filename: pulc_demo_imgs/safety_helmet/safety_helmet_test_2.png
[2022/10/18 21:27:41] ppcls INFO: Predict complete!safety_helmet_test_2.png预测出的标签是:wearing_helmet。
我们已经可以利用cmd命令来实现预测,下面我们用python代码来实现预测:
import paddleclas
model = paddleclas.PaddleClas(model_name="safety_helmet")
result = model.predict(input_data="pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png")
print(next(result))[{'class_ids': [1], 'scores': [0.9986255], 'label_names': ['unwearing_helmet'], 'filename': 'pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png'}]完美,在MyPredict.py中把预测能力封装成类:
# encoding=utf-8
import os
import subprocess
import paddleclasclass CMD(object):def __init__(self):pass# 直接调用系统cmd命令行去执行。def doPredict1(self, imgPath):cmd = "paddleclas --model_name=safety_helmet --infer_imgs="+imgPathos.system(cmd)# subprocess 模块允许我们启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值。def doPredict2(self,imgPath):cmd = "paddleclas --model_name=safety_helmet --infer_imgs="+imgPathp = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE,stderr=subprocess.STDOUT,encoding='utf-8') # 将标准输出重定向到当前子进程p1 = subprocess.Popen("", shell=True, stdout=None, stderr=None, encoding='utf-8') # 将标准输出还原到ide下的输出content = p.communicate()[0]print(content) # 正常的一个print,要把内容输出到当前窗口return contentclass FUN(object):def doPredict3(self,imgPath):model = paddleclas.PaddleClas(model_name="safety_helmet")result = model.predict(input_data=imgPath)res = next(result)print(res)return str(res)# 实现三种方式的预测
if __name__ == "__main__":cmd = CMD()cmd.doPredict1("pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png")cmd = CMD()cmd.doPredict2("pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png")fun = FUN()fun.doPredict3("pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png")运行MyPredict.py可验证三种方式均可正常预测:
[2022/10/18 22:24:05] ppcls WARNING: The current running environment does not support the use of GPU. CPU has been used instead.
e[37m--- Fused 0 subgraphs into layer_norm op.e[0m
[2022/10/18 22:24:05] ppcls INFO: class_ids: [1], scores: [0.9986255], label_names: ['unwearing_helmet'], filename: pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png
[2022/10/18 22:24:05] ppcls INFO: Predict complete![2022/10/18 22:24:13] ppcls WARNING: The current running environment does not support the use of GPU. CPU has been used instead.
e[37m--- Fused 0 subgraphs into layer_norm op.e[0m
[2022/10/18 22:24:13] ppcls INFO: class_ids: [1], scores: [0.9986255], label_names: ['unwearing_helmet'], filename: pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png
[2022/10/18 22:24:13] ppcls INFO: Predict complete![2022/10/18 22:24:13] ppcls WARNING: The current running environment does not support the use of GPU. CPU has been used instead.
e[37m--- Fused 0 subgraphs into layer_norm op.e[0m
[{'class_ids': [1], 'scores': [0.9986255], 'label_names': ['unwearing_helmet'], 'filename': 'pulc_demo_imgs/safety_helmet/safety_helmet_test_1.png'}]把MyPredict.py放入文件夹core,只需要import设计好的类就可以获得安全帽预测能力。
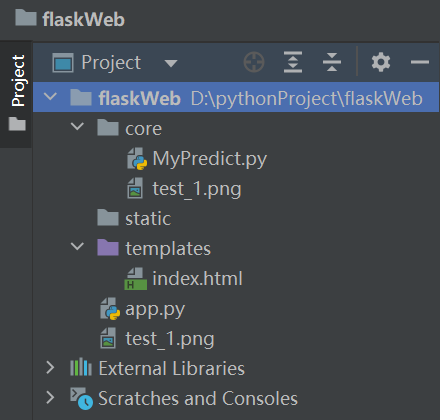
from core.MyPredict import CMD, FUN新建一个flask工程,整个工程布局如下:
index.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>login</title>
</head>
<body>
{{ msg }}
</body>
</html>app.py完成flask网站编写:
# encoding=utf-8from flask import Flask
from flask import request
import jsonfrom core.MyPredict import CMD, FUN
from flask import render_template# flask 是python非常轻量级的一个web框架
# 在线的版本,这个代码运行在服务器端,浏览器端、客户端来访问,这个就相当于百度开放的api# 创建应用实例
app = Flask(__name__)# Flask中的route()装饰器用于将URL绑定到函数
# 设置主页显示
@app.route('/', methods=["GET", "POST"])
def index():return render_template("index.html", msg="你好,这是安全帽预测服务网站")# 处理字符串的函数,提取需要的部分
def extractContent(res):return res.split("\n")[-3]@app.route('/predict1', methods=["GET", "POST"]) # 这个注解作用,就是做了一个路径映射,默认只支持GET方法,如果要POST,必须加上
def predict1():# 获得前端传来的参数# GET,url参数path = request.args.get("imgPath")path1 = request.values.get("imgPath")# POST,数据包参数# path2 = request.form.get("imgPath2")# path3 = "dd" # request.get_data().get("imgPath2")# path4 = request.get_json()# path5 = request.get_data()# header,header参数# path6 = request.headers["Content-Type"]print(path1)# print(path2)# print(path3)# print(path4)# print(path5)# print(path6)# img = request.args.get("imgBase64")cmd = CMD()res = cmd.doPredict2(path)res = extractContent(res)return json.dumps({"status":"ok","result":res})# 路径必须/开头
@app.route('/v1/predict2')
def predict2_v1():cmd = CMD()path = request.args.get("imgPath")res = cmd.doPredict1(path)return json.dumps(res)@app.route('/v2/predict2')
def predict2_v2():cmd = CMD()path = request.args.get("imgPath")res = cmd.doPredict2(path)return json.dumps(res)@app.route('/predict3')
def predict3():fun = FUN()path = request.args.get("imgPath")res = fun.doPredict3(path)return json.dumps(res)# 启动服务
if __name__ == '__main__':app.run()运行app.py:
打开网页:http://127.0.0.1:5000/
测试/predict1:

测试/v1/predict2:
返回null是因为doPredict1函数没有返回任何值。
# 直接调用系统cmd命令行去执行。def doPredict1(self, imgPath):cmd = "paddleclas --model_name=safety_helmet --infer_imgs="+imgPathos.system(cmd)测试/v2/predict2:
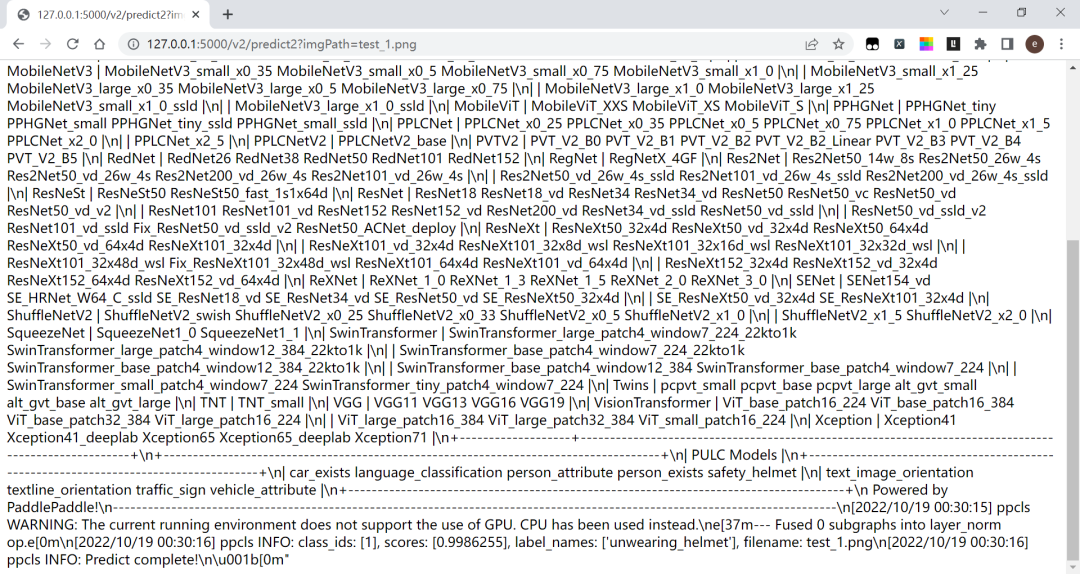
测试/predict3:

至此我们完成了具有安全帽检测预测服务的简单网站搭建,基本功能已经完成,剩下的任务就是做合适的前端设计,让用户方便使用。

往期精彩回顾适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码![[请教]关于超大数据量网站的数据搜索和分页的实现方法](/Images/OutliningIndicators/None.gif)