Zookeeper框架
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Java操作Zookeeper框架
#博学谷IT学习技术支持
文章目录
- Zookeeper框架
- 前言
- 一、shell命令操作ZK的节点
- 二、ZK节点的属性
- 三、ZK的Watch机制
- 四、ZK的Java操作
- 五、ZK的选举机制
- 总结
前言
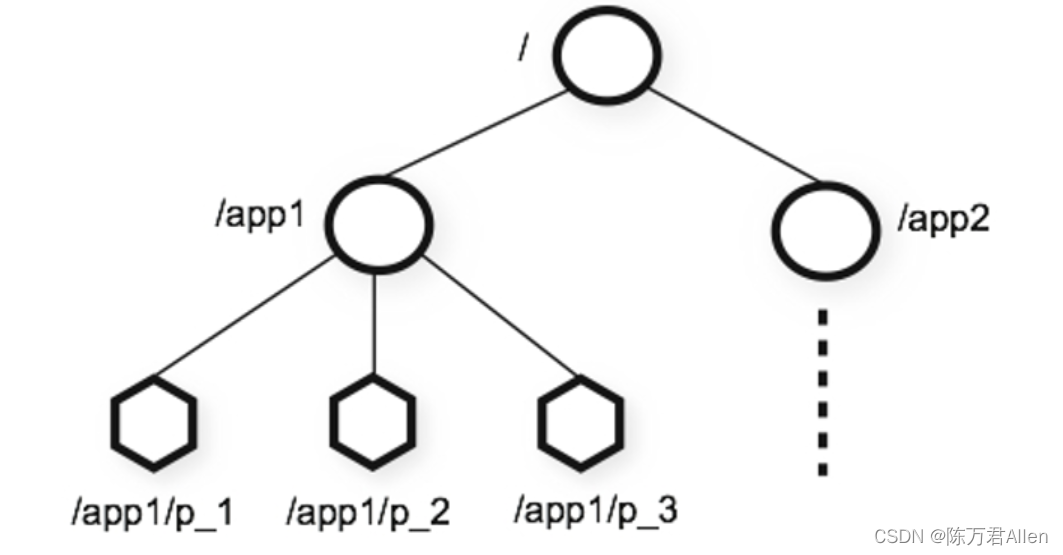
1、ZK内部有一个树形的结构的`目录树
2、访问目录树的节点必须使用绝对路径
3、ZK的节点称为Znode
4、Znode既具有文件特点(存数据),又具有文件夹特点(有子节点)
5、ZK中主要存储配置信息,数量量不大,一般是以K为单位,最多不超过1M
一、shell命令操作ZK的节点
1:创建普通永久节点#永久节点永远存在,除非手动删除create /app1 hello 2: 创建永久顺序节点#永久顺序节点永远存在,除非手动删除,会自动在节点名字后边加一串数字,该数字表示创建节点的先后顺序
#永久顺序节点的创建命令可以多次执行,因为后边会自动加编号create -s /app2 world 3:创建临时节点#临时节点依赖当前的会话(客户端和服务器构建的连接),会话消失,则节点自动消失
create -e /tempnode world4:创建临时顺序节点#临时顺序节点依赖当前的会话(客户端和服务器构建的连接),会话消失,则节点自动消失
#临时顺序节点的创建命令可以多次执行,因为后边会自动加编号
create -s -e /tempnode2 aaa5:创建子节点create /app1/app1_1 null #永久节点的子节点create -s /app1/app1_2 null #永久顺序节点的子节点#注意:临时节点,不能创建子节点6:获取节点数据get /app1get /app1/app1_17:修改节点数据set /app1 hadoop8:删除节点delete /app1 删除的节点不能有子节点rmr /app1 递归删除
二、ZK节点的属性
1、查看ZK节点属性get /app12、分析节点属性
nulll #节点数据
cZxid = 0x900000009 #节点创建事务ID,和创建的时机有关,该值不变
ctime = Sat Sep 03 13:51:44 CST 2022 #节点创建时间
mZxid = 0x900000009 #节点的修改事务ID,每次都节点进行修改,该值加1
mtime = Sat Sep 03 13:51:44 CST 2022 #节点修改时间
pZxid = 0x900000009 #子节点的事务ID,子节点发生变化,则会增加
cversion = 0 #子节点的版本号
dataVersion = 0 #节点数据版本,对字节数据修改,则值加1
aclVersion = 0 #节点的权限
ephemeralOwner = 0x0 #永久节点:0x0 临时节点(会话id): 0x182f95799320001
dataLength = 5 #节点数据的长度
numChildren = 0 #子节点的数量
三、ZK的Watch机制
wath机制就是监控一个节点的变化
数据修改
添加操作
删除操作
…
一旦监控到节点发生变化,则会自动触发某个行为(自定义):通知备用节点让他去进行节点创建
ZK的watch机制在命令行终端是一次性的,如果想重复的监听,则必须使用Java代码来完成
四、ZK的Java操作
<dependencies><dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>2.12.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>2.12.0</version></dependency><dependency><groupId>com.google.collections</groupId><artifactId>google-collections</artifactId><version>1.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.25</version></dependency></dependencies>
package pack01_zookeeper;import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.TreeCache;
import org.apache.curator.framework.recipes.cache.TreeCacheEvent;
import org.apache.curator.framework.recipes.cache.TreeCacheListener;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;public class Demo1Zookeeper {CuratorFramework client;@Beforepublic void init(){//定义重置策略ExponentialBackoffRetry policyRetry = new ExponentialBackoffRetry(3000, 3);//创建客户端对象String str = "node1:2181,node2:2181,node3:2181";client = CuratorFrameworkFactory.newClient(str, policyRetry);//开启客户端client.start();}//创建节点@Testpublic void createZnode() throws Exception {//创建永久节点client.create().forPath("/app1","hello".getBytes());//创建多级节点client.create().creatingParentsIfNeeded().forPath("/app2/app2_2","hello".getBytes());//创建不同节点的类型client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/app3","hello".getBytes());
// PERSISTENT -- 永久节点
// PERSISTENT_SEQUENTIAL -- 永久顺序节点
// EPHEMERAL -- 临时节点
// EPHEMERAL_SEQUENTIAL(3, true, true); --临时顺序节点}//修改节点数据@Testpublic void setZnode() throws Exception {client.setData().forPath("/app1","helloZK".getBytes());}//查询节点数据@Testpublic void getZnode() throws Exception{byte[] bytes = client.getData().forPath("/app1");String str = new String(bytes);System.out.println(str);}//删除节点@Testpublic void deleteZnode() throws Exception{client.delete().deletingChildrenIfNeeded().forPath("/app2");}//watch监听机制@Testpublic void watchDemo() throws Exception{//将要监听的的节点数存入缓存中TreeCache treeCache = new TreeCache(client, "/app1");//自定义监听treeCache.getListenable().addListener(new TreeCacheListener() {//childEvent方法是自动调用,只要你的/app1节点有状态变化,则就会自动执行该方法@Overridepublic void childEvent(CuratorFramework curatorFramework, TreeCacheEvent treeCacheEvent) throws Exception {switch (treeCacheEvent.getType()){case NODE_ADDED:System.out.println("NODE_ADDED");break;case NODE_REMOVED:System.out.println("NODE_REMOVED");break;case NODE_UPDATED:System.out.println("NODE_UPDATED");break;}}});treeCache.start();while (true);}@Afterpublic void close(){//关闭客户端client.close();}}
五、ZK的选举机制
1、场景1: 启动ZK,需要选举Leader
node1启动 投自己1票 和其他主机交换投票信息,系统判断投票数是否过半,否
node2启动 投自己1票 和其他主机交换投票信息,系统判断投票数是否过半,是,谁的myid最大,就是Leader node3启动 投自己1票 和其他主机交换投票信息,发现已经有Leader了,直接成为Follower
启动顺序: node3 ndoe2 node1 ----》node3就是leader
2、场景2:ZK运行的过程中,Leader挂掉,需要选举Leader
2.1 当Leader挂掉之后,系统会判断剩余的主机是否过半,是,则开始选举新Leader,否,则直接终止整个集群
2.2 如果剩余的主机过半,则开始选举新Leader
a:比较哪台主机的数据最新,如果某台主机的数据最新,则直接当选Leader
b:如果所有主机的数据都是一样新的,则谁的myid最大,谁就是Leader
总结
以上就是今天要讲的内容,本文仅仅简单介绍了Java操作Zookeeper框架